
Brevet des sites de haute qualité de Google
Publié: 2016-12-08
Vous reconnaîtrez peut-être les noms de l'un des inventeurs du brevet sur lequel j'écris un article. Il avait l'une des mises à jour Google dont on a le plus parlé en son honneur. Il est connu sous le nom de Panda.
Un article du blog Google sur Panda l'appelle la mise à jour des « sites de haute qualité » ; ce brevet parle de remplacer les résultats de recherche de haut rang provenant de sites de faible qualité par des résultats de recherche de haut rang provenant de sites de haute qualité. L'un des meilleurs articles de blog sur la mise à jour de Panda est celui d'Amit Singhal :
Plus de conseils sur la construction de sites de haute qualité
Il est bon que l'article de blog détaille beaucoup ce qu'est un site Web de haute qualité, car le brevet ne nous dit pas comment faire la distinction entre un site de mauvaise qualité et un site de haute qualité. Encore plus d'informations sur la façon dont Google peut identifier les sites de mauvaise qualité et de haute qualité sont expliquées dans cette interview Wired avec Matt Cutts et Amit Singhal :
TED 2011 : Le « Panda » qui déteste les fermes : Questions-réponses avec les meilleurs ingénieurs de recherche de Google
Ce brevet est intéressant car il donne un aperçu de la mise à jour Panda pour nous donner une idée de ce qui arrivait aux chercheurs plutôt qu'aux propriétaires de sites lorsqu'ils effectuaient des recherches et ne se retrouvaient pas sur les sites de ferme de contenu que la mise à jour Panda était censée les détourner de. Comme le dit le brevet, il "se concentre sur l'amélioration des résultats de recherche en remplaçant les sites Web de mauvaise qualité par des sites identifiés comme des sites de haute qualité".
C'était un problème qui avait été identifié à quelques endroits et noté dans des endroits importants, tels que le New York Times, qui a remarqué la mise à jour Panda de Google :
Google Tweaks Algorithm pour repousser les sites de faible qualité
Ce brevet identifie les pages qui se classent bien pour certaines requêtes et examine la qualité de ces pages. Si une quantité seuil de ces pages de classement sont des pages de mauvaise qualité, le moteur de recherche peut utiliser une requête alternative pour trouver le deuxième ensemble de résultats de recherche qui incluent des pages de sites de haute qualité. Ces résultats de recherche de la première requête peuvent ensuite être fusionnés avec les résultats de la requête alternative, les pages des sites de faible qualité étant supprimées afin que les résultats de la recherche incluent un plus grand pourcentage de pages de sites de haute qualité.
L'aspect positif de ce résultat est que les résultats qui ont un seuil élevé de résultats provenant de sites de faible qualité disparaissent et sont remplacés par des résultats qui incluent des sites de meilleure qualité. Les résultats de recherche de Google finissent par être meilleurs.
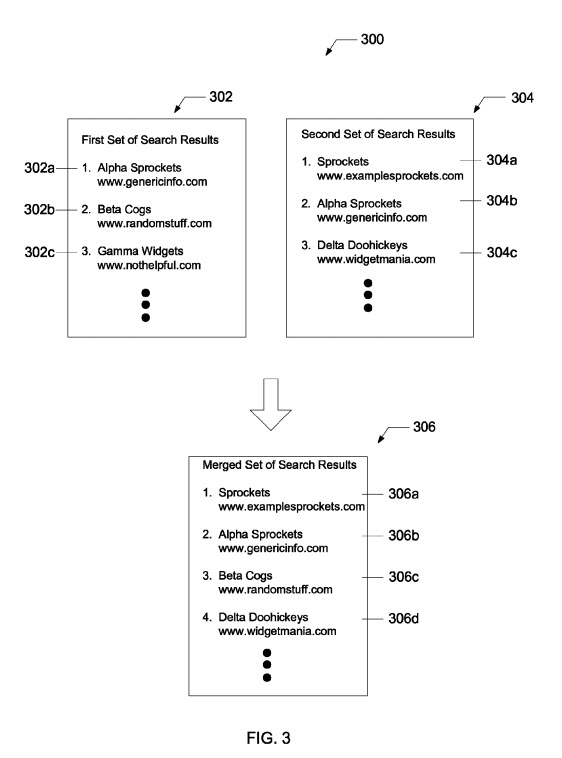
Résultats de recherche fusionnés
Le brevet ne définit pas ce qu'est pour nous un site de haute qualité ou de mauvaise qualité. Le billet de blog d'Amit Singhal fait un meilleur travail en fournissant des « orientations » sur la signification de ces termes.
Le brevet ne traite pas de la perte de trafic vers les sites de mauvaise qualité qui sont supprimés des résultats de recherche. Nous avons entendu des personnes affectées par Panda combien de trafic elles perdaient sur leurs sites.
Le brevet est :
Génération sélective de requêtes alternatives
Inventeurs Navneet Panda, April R. Lehman, Trystan G. Upstill
Cessionnaire d'origine Google Inc.
Numéro de publication US9135307 B1
Type de publication Subvention
Numéro de demande US 13/728 851
Date de publication 15 sept. 2015
Date de dépôt 27 déc. 2012
Résumé:
L'invention concerne des procédés, des systèmes et un appareil, y compris des programmes informatiques codés sur des supports de stockage informatiques, permettant d'obtenir des résultats de recherche à partir de sites de haute qualité. L'un des procédés comprend la réception de données identifiant des premières ressources qui répondent à une première requête. Si au moins un premier nombre seuil N de premières ressources les mieux classées sont situés sur des sites précédemment identifiés comme des sites de faible qualité, une deuxième requête et des données identifiant des deuxièmes ressources qui répondent à la deuxième requête sont obtenues, au moins un deuxième seuil nombre M de deuxièmes ressources les mieux classées sont localisées sur des sites préalablement identifiés comme des sites de qualité. Les résultats de la recherche sont fournis en réponse à la première requête, les résultats de la recherche identifiant une ou plusieurs des premières ressources et identifiant également une seconde ressource particulière des secondes ressources.

La définition d'un « site » dans ce brevet est intéressante, et voici les alternatives proposées :
(1) une collection de ressources hébergées sur un serveur particulier.
(2) Les ressources d'un domaine, par exemple "example.com", où les ressources du domaine, par exemple "host.example.com/resource1", "www.example.com/folder/resource2" ou " example.com/resource3 », se trouvent sur le site.
(3) Les ressources dans un sous-domaine, par exemple, "en.example.com", où les ressources dans le sous-domaine, par exemple, "en.example.com/resource1" ou "en.example.com/folder/resource2", sont sur le site.
(4) Les ressources d'un sous-répertoire, par exemple « example.com/sous-répertoire », où les ressources du sous-répertoire, par exemple « exemple.com/sous-répertoire/ressource.html », se trouvent sur le site.
Il est fait mention des scores de qualité du site, mais pas de la manière dont ils sont déterminés. Le brevet nous dit que le moteur de recherche peut utiliser une liste blanche de sites de haute qualité et une liste noire de sites de mauvaise qualité préparées manuellement ou par une autre méthode hors ligne.
On nous dit également que des informations sur les requêtes peuvent être collectées au fil du temps. Si une certaine quantité des pages les mieux classées pour la requête initiale se trouvent sur des sites de faible qualité, une deuxième requête basée sur cette première requête peut être utilisée. Le brevet nous dit qu'une façon de procéder consiste à utiliser une base de données qui "inclut des termes de requête de substitution et peut générer une requête alternative en substituant un terme de requête de substitution à l'un des termes de requête dans la première requête". Cela m'a rappelé certains articles que j'ai écrits sur les brevets de Google couvrant des termes de requête de substitution, comme j'en ai parlé dans :
- Comment Google peut remplacer les termes de requête par la co-occurrence
- Comment les moteurs de recherche peuvent remplacer les vôtres par d'autres termes de recherche
- Enquêter sur Google RankBrain et les substitutions de termes de requête
Comme alternative, le brevet nous dit que le moteur de recherche pourrait construire « un graphe conceptuel de requêtes et parcourir le graphe pour obtenir une ou plusieurs requêtes alternatives ». Que, « chaque nœud du graphique est défini par une requête et un ensemble de résultats de recherche les mieux classés obtenus pour la requête. Les liens entre les nœuds du graphique peuvent indiquer que les requêtes sont liées ou qu'une requête est une requête alternative pour une autre requête.
Ce serait très différent des graphiques de liens auxquels nous pensons quand il s'agit de Google, mais une façon intéressante de penser à la façon dont des requêtes alternatives pourraient être trouvées. Le brevet s'appuie sur cette approche graphique, et il semble que cela pourrait être une méthode qu'ils ont utilisée.
Ce système de recherche peut évaluer plus d'une requête alternative possible avant d'en sélectionner une avec la mesure de confiance la plus élevée.
Si l'ensemble de résultats inclut une quantité seuil fusionnée de sites de haute qualité, il peut essayer d'accumuler davantage de résultats de requête alternatifs à partir de sites de haute qualité.
Conclusion
Il s'agit peut-être du brevet original de la mise à jour Panda. Navneet Panda de Google est l'un des inventeurs du brevet, comme cela a été révélé dans l'interview de Wired avec Cutts et Singhal. Et ce brevet cible les sites de ferme de contenu, ce pour quoi la mise à jour originale de Panda était la plus connue. Le brevet lui-même ne divulgue pas les différences entre les sites de mauvaise qualité et de haute qualité, et nous avons appris dans l'interview filaire que c'est l'ingénieur de recherche nommé Panda qui a posé certaines des questions initiales identifiant les différences entre les deux.