
Google은 Q&A 페이지에서 엔티티 관계 정보를 어떻게 추출합니까?
게시 됨: 2019-10-30질문 및 답변 웹사이트가 검색 엔진에 엔터티에 대한 정보와 해당 엔터티 및 기타 엔터티 및 엔터티 속성에 대한 엔터티 관계 정보를 제공하는 데 얼마나 도움이 될까요?
Google에서 최근에 부여한 특허는 이러한 잠재적인 정보 소스를 살펴보고 더 많은 정보를 제공합니다.
이 특허의 발명가 중 한 명인 Evgeniy Gabrilovich는 엔티티에 대한 웹의 텍스트에서 관계 정보를 추출하는 것과 같은 것에 대해 이야기하는 Google의 지식 보관소 프로젝트에 참여했습니다. 웹에서 엔터티 관계 정보를 추출하는 방법에 대해 설명하기 위해 지식 보관소 프로젝트 개발 중에 준비된 프레젠테이션을 볼 가치가 있습니다. 웹 규모 지식 그래프 구성 및 마이닝에서 찾을 수 있습니다.
엔터티 간의 후보자 관계
2019년 10월 22일 Google에 부여된 해당 특허는 "버락 오바마는 누구와 결혼했습니까?"와 같은 엔터티 간의 관계에 대한 정보를 제공하는 리소스로 이러한 사이트를 사용할 수 있는 방법에 대해 알려줍니다. 그 페이지에는 "Michelle Obama"라는 대답도 포함될 수 있습니다.
특허는 그러한 페이지가 관련된 질문을 살펴봄으로써 엔티티 관계를 식별할 수 있다고 지적합니다.
예를 들어, 질문 텍스트에서 "결혼한"이라는 용어가 질문 텍스트에 표시된 개체와 답변 텍스트에 표시된 개체 사이의 배우자 관계를 나타낼 가능성이 있다고 결정함으로써 질문 텍스트를 기반으로 관계 유형이 결정됩니다. 엔터티는 질문 텍스트와 답변 텍스트에서도 식별됩니다. 예를 들어, 컴퓨터 시스템은 질문 텍스트에서 엔티티 "Barack Obama"를 식별하고 답변 텍스트에서 엔티티 "Michelle Obama"를 식별할 수 있습니다.
질문과 답변 텍스트로 식별된 두 엔터티와 관계 유형을 식별하면 후보 관계가 결정됩니다. 예를 들어, 결정된 후보 관계는 엔티티 "버락 오바마"와 "미셸 오바마" 간의 배우자 관계일 수 있다.
가능한 답변에서 후보자 답변으로 이동
이 특허는 Q&A 사이트가 "미셸 오바마", "힐러리 클린턴" 또는 "로라 부시"를 포함할 수 있는 버락 오바마와의 배우자 관계에 대한 질문에 대한 잠재적인 답변을 표시할 수 있다고 알려줍니다.
Google은 어떤 후보 답변이 가장 가능성이 높은지 어떻게 결정할 수 있습니까?
Google은 "Q&A 웹사이트의 웹페이지에서 후보 관계가 결정된 빈도"에 따라 후보 관계 각각에 점수를 매길 수 있습니다. 특허는 다음과 같이 알려줍니다.
점수가 가장 높은 후보 관계가 특정 관계 유형 및 엔터티에 대해 가장 가능성이 높은 유효한 관계로 선택됩니다. 예를 들어, "버락 오바마"와 "미셸 오바마" 사이의 후보 배우자 관계가 엔티티 "버락 오바마"에 대해 가장 자주 발생하는 배우자 관계라는 결정에 기초하여 컴퓨터 시스템은 "버락 오바마" 사이에 배우자 관계가 존재한다고 결정합니다. 그리고 "미셸 오바마." 그러면 컴퓨터 시스템은 엔터티 관계 모델에서 엔터티 "Barack Obama"와 엔터티 "Michelle Obama" 간의 배우자 관계를 설정할 수 있습니다.
이 특허에 설명된 프로세스에서 혁신적인 것은 무엇입니까? 이러한 단계는 다음과 같습니다.
- 자원을 획득하는 행위를 포함한다.
- 질문으로 특징지어지는 자원 텍스트의 첫 부분 식별
- 질문에 대한 답변으로 특징지어지는 리소스 텍스트의 두 번째 부분
- 질문으로 특징지어지는 텍스트의 첫 번째 부분의 하나 이상의 용어에 의해 참조되는 개체 식별
- 질문으로 특징지어지는 텍스트의 첫 번째 부분의 하나 이상의 다른 용어에 의해 참조되는 관계 유형
- 질문에 대한 답변으로 특징지어지는 텍스트의 두 번째 부분에 의해 참조되는 엔터티
- 질문으로 특성화되는 텍스트의 첫 번째 부분과 특성화되는 텍스트의 두 번째 부분에 의해 참조되는 엔티티의 하나 이상의 용어에 의해 참조되는 엔티티에 대한 관계 유형의 관계와 연관된 점수 조정 질문에 대한 답변으로
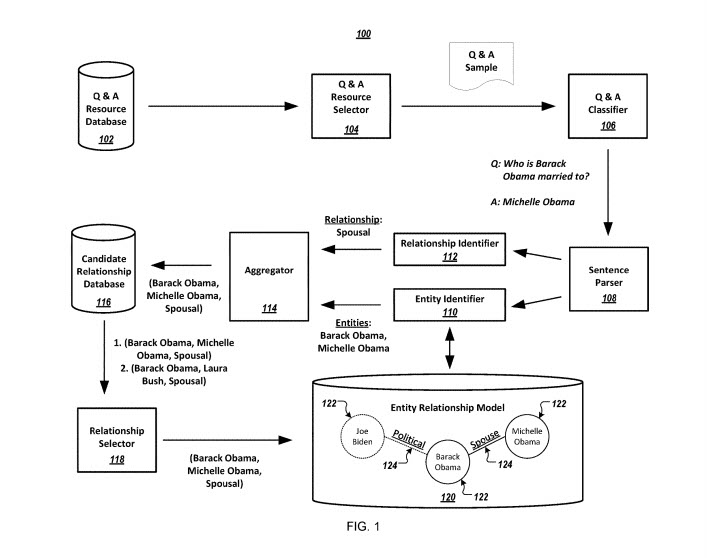
이 프로세스는 질문 및 답변(Q&A) 웹사이트를 사용합니다.
질문을 템플릿으로 확인하여 질문에 표시된 첫 번째 엔터티와 관계 유형을 식별합니다. Q&A 사이트의 각 템플릿은 특정 관계 유형과 연관될 수 있습니다.
이 엔티티 관계 정보 특허는 다음에서 찾을 수 있습니다.
질의응답 사이트에서 정보추출
발명가: Wei Lwun Lu, Denis Savenkov, Amarnag Subramanya, Jeffrey Dalton, Evgeniy Gabrilovich, Eugene Agichtein
양수인: Google LLC
미국 특허: 10,452,694
부여: 2019년 10월 22일
출원일: 2017년 12월 20일
추상적 인
리소스를 획득하기 위한 방법, 시스템 및 장치는 질문으로 특징지어지는 리소스의 텍스트의 첫 번째 부분과 질문에 대한 답변으로 특징지어지는 리소스의 텍스트의 두 번째 부분을 식별하고, 질문으로 특성화되는 텍스트의 하나 이상의 용어, 질문으로 특성화되는 텍스트의 하나 이상의 다른 용어에 의해 참조되는 관계 유형 및 다음과 같은 텍스트에 의해 참조되는 엔티티 질문에 대한 답변으로 특징지어지고, 질문으로 특징지어지는 텍스트의 하나 이상의 용어에 의해 참조되는 개체와 해당 텍스트에 의해 참조되는 개체에 대한 관계 유형의 관계에 대한 점수를 조정합니다. 라는 질문에 대한 답변으로 특징지어집니다.
엔터티 관계 정보 모델
이 특허의 초점은 Q&A 웹사이트 리소스를 결정하는 관계를 지정하는 엔티티 관계 모델을 구축하는 데 있습니다.
이 시스템에는 다음이 포함됩니다.
Q&A 리소스 데이터베이스
Q&A 리소스 선택기
Q&A 분류기
문장 파서
엔티티 식별자
관계 식별자
애그리게이터
후보 관계 데이터베이스
관계 선택자
엔터티 관계 모델입니다.
개체-관계 모델에서 표현되는 개체는 노드로 표현될 수 있으며 개체 간의 관계는 가장자리로 표현됩니다. 엔터티 관계에 대한 신뢰도 점수는 해당 관계가 사실일 가능성이 있는 정확도를 나타냅니다.
Q&A 웹사이트 리소스에서 엔티티 관계 정보를 추출할 때 이 시스템은 Q&A 웹사이트의 여러 리소스를 포함하는 Q&A 리소스 데이터베이스를 볼 수 있습니다.
이러한 리소스에는 다음이 포함될 수 있습니다.
- Q&A 웹사이트의 아카이브 버전과 같은 Q&A 웹사이트0의 여러 웹페이지
- Q&A 웹사이트의 웹페이지 관련 메타데이터
- Q&A 웹사이트에서 볼 수 있는 문서
- Q&A 웹사이트에서 액세스할 수 있는 이미지
- Q&A 웹사이트에서 볼 수 있는 비디오
- Q&A 웹사이트에서 오디오 액세스 가능
- Q&A 웹사이트와 관련되거나 액세스할 수 있는 기타 리소스
Q&A 리소스 데이터베이스에는 다음과 같은 Q&A 웹사이트가 아닌 소스의 리소스도 포함될 수 있습니다.

- 포럼 웹사이트의 하나 이상의 리소스
- 소셜 네트워크 플랫폼
- 자주 묻는 질문(FAQ) 웹사이트 또는 FAQ 웹사이트
- 정보 제공 웹사이트
- 질문과 답변이 가능한 기타 출처
이 질문 식별자가 엔터티와 이들 간의 관계를 식별하는 질문과 답변을 찾을 때 질문 및 답변 페이지의 텍스트 구문 분석을 시작하여 물음표와 같은 특정 문자 또는 문자열의 존재를 찾을 수 있습니다. 또한 다음과 같은 질문 텍스트를 나타내는 단어나 질문을 찾을 수도 있습니다.
- “궁금했어요”
- "나는 물어보고있어"
- "의문"
- "WHO"
- "무엇"
- "어디"
- "언제"
- "왜"
- "어떻게"
- 등.
같은 방식으로 답변을 찾을 때 페이지의 텍스트를 구문 분석하여 다음과 같이 답변 텍스트를 나타낼 수 있는 단어를 찾을 수 있습니다.
- "알아요"
- "나는 믿는다"
- "제 생각에는"
- "정답은"
- "대답"
- 등.
품사에 태그를 지정하는 자연어 처리 방식에서 페이지의 텍스트 구문 분석을 포함하는 이 프로세스의 일부:
예를 들어 문장 파서는 "Barack Obama는 누구와 결혼 했습니까?"라는 질문 텍스트를 수신 할 수 있습니다. 질문 텍스트를 "WHO/대명사 IS/동사 BARACK OBAMA/명사 결혼/형용사 TO/동사?"로 주석을 달 수 있습니다. 유사하게, 문장 파서는 "Michelle Obama"라는 답변 텍스트를 수신할 수 있고 답변 텍스트를 "MICHELLE OBAMA/명사"로 주석 처리할 수 있습니다. 문장 파서는 주석이 달린 텍스트에서 하나 이상의 문법 단위의 클래스 또는 상위어를 추가로 결정할 수 있어, 예를 들어 "버락 오바마"라는 용어가 "인물" 명사 클래스를 구성하고 "미셸 오바마"라는 용어도 다음을 구성한다는 것을 결정할 수 있습니다. "사람" 명사 클래스.
질문 및 답변 텍스트를 구문 분석한 문장 파서는 엔티티 식별자 및 관계 식별자에 주석이 달린 질문 및 답변 텍스트를 제공합니다. 대안적인 구현에서, 질문 텍스트 및/또는 답변 텍스트는 문장 파서에 의한 처리 없이 엔티티 식별자 및 관계 식별자에 제공될 수 있다. 그러한 구현에서, 엔티티 식별자 및/또는 관계 식별자는 문장 파서에 의해 수행되는 것과 유사한 동작을 수행할 수 있거나, 질문 텍스트 또는 답변 텍스트에 주석을 달지 않고 질문 텍스트 및/또는 답변 텍스트로부터 엔티티 또는 관계를 식별할 수 있다. 이러한 경우 Q&A 분류기는 엔터티 식별자 및 관계 식별자에 질문 및 답변 텍스트를 제공할 수 있습니다.
식별된 질문 텍스트와 답변 텍스트는 Q&A 페이지에서 질문되고 답변되는 엔티티 관계의 유형을 식별할 수 있습니다.
질문 텍스트 및 답변 텍스트에서 답변을 구문 분석하는 방법의 또 다른 예:
예를 들어 엔티티 식별자는 "버락 오바마는 누구와 결혼했습니까?"라는 질문 텍스트를 수신할 수 있습니다. 엔티티 "Barack Obama"를 식별하고 "그는 백악관에서 아내 Michelle Obama와 함께 살고 있습니다"라는 응답 텍스트를 수신하고 엔티티 "Michelle Obama" 및 "White House"를 식별할 수 있습니다. 엔티티 식별자는 엔티티 "버락 오바마" 및 "미셸 오바마"가 각각 "인" 명사 클래스이고 엔티티 "백악관"이 "장소" 명사 클래스임을 결정할 수 있다. 엔터티 식별자는 "사람" 명사 클래스에 속하는 두 엔터티를 기반으로 "Barack Obama" 및 "Michelle Obama" 엔터티를 잠재적으로 관련된 엔터티로 선택할 수 있으므로 특정 사람보다 어떤 방식으로든 관련될 가능성이 더 높습니다. 특정 장소와 관련이 있습니다.
이와 같은 접근 방식을 사용하여 찾을 수 있는 다른 종류의 엔터티 관계 정보는 무엇입니까?
- 배우자 관계
- 가족 관계
- 정치적 관계
- 비즈니스 관계
- 소유권 관계
- 거주 관계
- 출생지 관계
- 직원/고용주 관계
- 직업 관계
- 사람, 장소 또는 사물 간의 기타 관계
다른 유형의 엔터티 관계 정보
특정 엔터티와 숫자 값 또는 날짜 사이. 이러한 숫자 값에는 다음이 포함될 수 있습니다.
- 사람의 나이
- 순 가치
- 저지 번호
- 키
- 생일
- 결혼 날짜
- 사망일
- 창업일
- 인구 규모의 도시
- 등.
"매처"는 특정 질문이 관계 식별자로 액세스할 수 있는 특정 템플릿에 맞는지 판단하여 "[PERSON]은 누구와 결혼했습니까?"와 같은 템플릿을 만들 수 있습니다. 에 대한 정보를 수집하는 관계.
이 특허는 이러한 템플릿이 올바른 유형의 엔터티를 템플릿과 일치시키려고 시도하므로 장소를 나타낼 수 있는 엔터티가 배우자 관계 유형을 결정하는 관계 식별자와 작동하지 않을 수 있음을 알려줍니다. : “미국은 누구와 결혼했습니까?”
그래서 그 쿼리를 시도했고 예상치 못한 대답을 얻었습니다.

결론
Google은 BERT라는 자연어 처리 방식을 사용하고 있다고 발표했습니다. 지난 5월 Google에서 Semantic Frames and Word Embeddings라는 게시물을 작성할 때 그 접근 방식을 언급했습니다. 이 특허는 자연어 처리가 Q&A 페이지의 질문과 답변을 이해하는 데 어떻게 사용될 수 있는지, 그리고 이것이 엔터티와 엔터티 속성 간의 관계를 식별하기 위해 알려진 템플릿에 맞는지 여부에 대한 좋은 예를 제공합니다.
이 특허는 엔티티 간의 관계 또는 해당 엔티티의 속성에 대해 더 많은 확신을 얻으려고 시도하는 방법에 대한 몇 가지 추가 예를 제공합니다. 그러나 이 특허는 Q&A 웹사이트에서 엔티티 관계 정보를 추출하는 방법을 상당히 설명하고 있습니다.