
谷歌如何從問答頁面中提取實體關係信息?
已發表: 2019-10-30問答網站在向搜索引擎提供有關實體的信息以及有關這些實體和其他實體以及實體的屬性的實體關係信息方面有多大幫助?
谷歌最近授予的一項專利研究了這些潛在的信息來源,並告訴我們更多信息。
該專利的發明者之一 Evgeniy Gabrilovich 參與了 Google 的知識庫項目,該項目討論了諸如從網絡上關於實體的文本中提取關係信息之類的事情。 值得一看在知識庫項目開發期間準備的演示文稿,以了解它關於從 Web 中提取實體關係信息的內容。 可以在以下位置找到:構建和挖掘 Web 級知識圖譜
實體之間的候選關係
該專利於 2019 年 10 月 22 日授予谷歌,告訴我們如何將此類網站用作資源來提供有關實體之間關係的信息,例如“巴拉克奧巴馬嫁給了誰?” 該頁面上也可能包含答案“米歇爾·奧巴馬”。
該專利指出,此類頁面可以通過查看所涉及的問題來識別實體關係:
基於疑問句確定關係類型,例如確定疑問句中的“已婚”一詞可能表示疑問句中指示的實體與回答文本中指示的實體之間存在配偶關係。 實體也可以從問題文本和答案文本中識別出來。 例如,計算機系統可以從問題文本中識別出實體“Barack Obama”,從答案文本中識別出實體“Michelle Obama”。
在識別了關係類型和由問答文本識別的兩個實體之後,確定候選關係。 例如,確定的候選人關係可以是實體“Barack Obama”和“Michelle Obama”之間的配偶關係。
從可能的答案轉移到候選答案
該專利告訴我們,問答網站可能會針對與巴拉克·奧巴馬的配偶關係問題提供多個潛在答案,其中可能包括“米歇爾·奧巴馬”、“希拉里·克林頓”或“勞拉·布什”。
Google 如何決定最有可能的候選答案?
Google 可能會根據“從問答網站的網頁中確定候選關係的頻率”對每個候選關係進行評分。 該專利告訴我們:
對於特定的關係類型和實體,具有最高分數的候選關係被選為最可能的有效關係。 例如,基於確定“Barack Obama”和“Michelle Obama”之間的候選配偶關係是實體“Barack Obama”最常出現的配偶關係,計算機系統確定“Barack Obama”之間存在配偶關係。和“米歇爾奧巴馬”。 然後,計算機系統可以在實體關係模型中建立實體“Barack Obama”和實體“Michelle Obama”之間的配偶關係。
該專利中描述的工藝有何創新之處? 它告訴我們這些步驟是:
- 它涉及獲取資源的動作
- 識別資源文本的第一部分,其特徵為問題
- 資源文本的第二部分,其特徵是對問題的回答
- 識別被特徵為問題的文本第一部分的一個或多個術語所引用的實體
- 被特徵為問題的文本第一部分的一個或多個其他術語引用的關係類型
- 由文本的第二部分引用的實體,其特徵是問題的答案
- 調整與被表徵為問題的文本的第一部分的一個或多個術語引用的實體和被表徵的文本的第二部分引用的實體的關係類型的關係相關聯的分數作為問題的答案
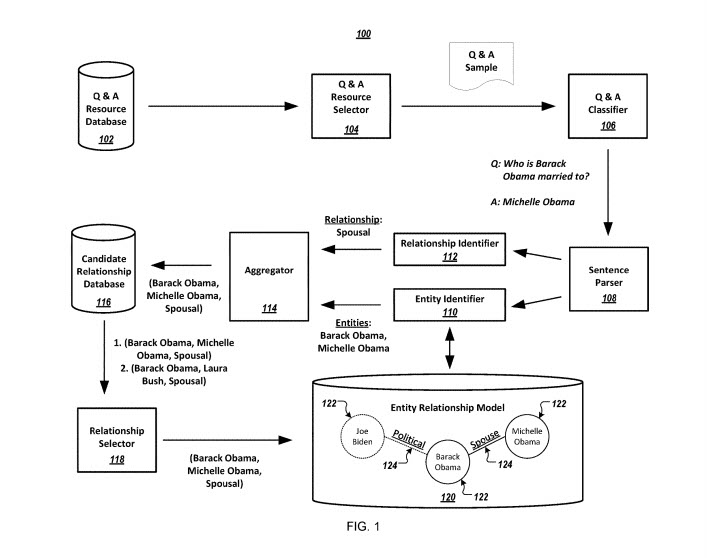
此過程使用問答 (Q&A) 網站
它將問題視為模板,以識別問題中顯示的第一個實體和關係類型,問答站點上的每個模板都可能與特定的關係類型相關聯。
該實體關係信息專利可在以下網址找到:
從問答網站中提取信息
發明人:Wei Lwun Lu、Denis Savenkov、Amarnag Subramanya、Jeffrey Dalton、Evgeniy Gabrilovich、Eugene Agichtein
受讓人:谷歌有限責任公司
美國專利:10,452,694
授予時間:2019 年 10 月 22 日
提交時間:2017 年 12 月 20 日
抽象的
用於獲取資源的方法、系統和裝置,用於識別資源的文本的被表徵為問題的第一部分,以及資源的文本的被表徵為對問題的答案的第二部分,識別實體被表徵為問題的文本的一個或多個術語引用,被表徵為問題的文本的一個或多個其他術語引用的關係類型,以及被表徵為問題的文本引用的實體被表徵為問題的答案,並且為被表徵為問題的文本的一個或多個術語所引用的實體和被該文本引用的實體調整關係類型的關係的分數被表徵為問題的答案。
實體關係信息模型
該專利的重點是構建實體關係模型,該模型指定由問答網站資源確定的關係。
該系統包括:
問答資源庫
問答資源選擇器
問答分類器
一個句子解析器
實體標識符
關係標識符
聚合器
候選關係數據庫
關係選擇器
實體關係模型。
實體關係模型中表示的實體可以表示為節點,實體之間的關係表示為邊。 關於實體關係的置信度分數表明這些關係可能為真的準確性。
當從問答網站資源中提取實體關係信息時,該系統可能會查看包含來自問答網站的多個資源的問答資源數據庫。
這些資源可以包括:
- 來自問答網站的許多網頁0,例如來自問答網站的網頁的存檔版本
- 與問答網站的網頁相關的元數據
- 可在問答網站上訪問的文件
- 可在問答網站上訪問的圖像
- 可在問答網站上訪問的視頻
- 在問答網站上可訪問的音頻
- 與問答網站相關或可訪問的其他資源
問答資源數據庫還可以包括來自問答網站以外的資源,例如:

- 來自論壇網站的一項或多項資源
- 社交網絡平台
- 常見問題 (FAQ) 網站或常見問題網頁
- 信息網站
- 提供問題和答案的其他來源
當此問題標識符正在尋找標識實體及其之間關係的問題和答案時,它可能會開始解析問答頁面上的文本以查找某些字符或字符串的存在,例如問號。 它還可能查找指示問題文本的單詞或問題,例如:
- “我想知道”
- “我在問”
- “問題”
- “誰”
- “什麼”
- “在哪裡”
- “什麼時候”
- “為什麼”
- “如何”
- 等等。
同樣,在尋找答案時,頁面上的文本可能會被解析以找到可能指示答案文本的單詞,例如:
- “我知道”
- “我相信”
- “我認為”
- “答案是”
- “回答”
- 等等。
此過程的一部分涉及使用標記詞性的自然語言處理方法解析頁面上的文本:
例如,句子解析器可能會收到問題文本“巴拉克奧巴馬嫁給了誰?” 並且可以將問題文本註釋為“WHO/代詞 IS/動詞 BARACK OBAMA/名詞已婚/形容詞 TO/動詞?” 類似地,句子解析器可能會收到答案文本“Michelle Obama”,並且可能會將答案文本註釋為“MICHELLE OBAMA/noun”。 句子解析器可以進一步確定註釋文本中一個或多個語法單元的類或上位詞,例如確定詞條“Barack Obama”構成“person”名詞類,詞條“Michelle Obama”也構成一個“人”名詞類。
句子解析器解析了問答文本後,將標註後的問答文本提供給實體標識和關係標識。 在替代實施方式中,問題文本和/或答案文本可以被提供給實體標識符和關係標識符而無需由句子解析器處理。 在這樣的實現中,實體標識符和/或關係標識符可以執行與句子解析器執行的操作類似的操作,或者可以從問題文本和/或答案文本中識別實體或關係,而無需註釋問題文本或答案文本。 在這種情況下,問答分類器可以向實體標識符和關係標識符提供問答文本。
被識別的問題文本和答案文本可以識別在問答頁面上被詢問和回答的實體關係的類型。
另一個如何從問題文本和答案文本中解析答案的示例:
例如,實體標識符可能會收到問題文本“巴拉克奧巴馬嫁給了誰?” 並識別實體“Barack Obama”,並且可能會收到答案文本“他與妻子米歇爾奧巴馬住在白宮”,並識別實體“米歇爾奧巴馬”和“白宮”。 實體標識符可以確定實體“Barack Obama”和“Michelle Obama”均屬於“person”名詞類,而實體“White House”屬於“place”名詞類。 實體標識符可以選擇實體“Barack Obama”和“Michelle Obama”作為潛在相關實體,因為這兩個實體都屬於“person”名詞類,因此比特定人更可能以某種方式相關與特定地點有關。
使用這樣的方法可以找到哪些其他類型的實體關係信息?
- 配偶關係
- 家庭關係
- 政治關係
- 業務關係
- 所有權關係
- 居住關係
- 出生地關係
- 僱員/雇主關係
- 職業關係
- 人、地或物之間的其他關係
一些其他類型的實體關係信息
在特定實體和數值或日期之間。 此類數值可能包括:
- 一個人的年齡
- 淨值
- 球衣號碼
- 高度
- 出生日期
- 結婚日期
- 死亡的日期
- 創辦企業的日期
- 人口規模的城市
- 等等。
“匹配器”可以確定特定問題是否適合可通過關係標識符訪問的特定模板,從而製作諸如“[PERSON] 與誰結婚?”之類的模板。 收集有關信息的關係。
該專利試圖通過提供示例告訴我們,這些模板將嘗試將正確類型的實體與模板匹配,因此可能指示地點的實體可能無法與確定配偶關係類型的關係標識符一起使用:“美國嫁給了誰?”
所以我嘗試了那個查詢,並得到了一個意想不到的答案:

結論
谷歌剛剛宣布它正在使用一種稱為 BERT 的自然語言處理方法。 早在 5 月份,我在谷歌寫了一篇文章語義框架和詞嵌入時就提到了這種方法。 該專利提供了一個很好的示例,說明如何使用自然語言處理來理解問答頁面上的問題和答案,以及這些問題和答案是否適合某些已知模板來識別實體和實體屬性之間的關係。
該專利確實提供了一些其他示例,說明它可能如何嘗試對實體之間的關係或這些實體的屬性獲得更多信心。 但該專利相當描述瞭如何從問答網站中提取實體關係信息。