
In che modo Google può estrarre le informazioni sulle relazioni tra entità dalle pagine di domande e risposte?
Pubblicato: 2019-10-30Quanto possono essere utili i siti Web di domande e risposte nel fornire a un motore di ricerca informazioni sulle entità e informazioni sulle relazioni tra entità su tali entità e altre entità e proprietà delle entità?
Un brevetto recentemente concesso da Google esamina tali potenziali fonti di informazioni e ci dice di più.
Uno degli inventori di questo brevetto, Evgeniy Gabrilovich, ha lavorato al progetto knowledge vault di Google che parla di cose come l'estrazione di informazioni sulle relazioni dal testo sul web sulle entità. Vale la pena guardare una presentazione che è stata preparata durante lo sviluppo del progetto Knowledge Vault per vedere cosa dice sull'estrazione di informazioni sulla relazione tra entità dal Web. Può essere trovato in: Costruzione ed estrazione di grafici della conoscenza su scala Web
Rapporti candidati tra entità
Quel brevetto, concesso a Google il 22 ottobre 2019, ci dice come tali siti possono essere utilizzati come risorse per fornire informazioni sulle relazioni tra entità, come "Con chi è sposato Barack Obama?" Quella pagina potrebbe anche includere la risposta "Michelle Obama".
Il brevetto sottolinea che tali pagine possono identificare le relazioni tra entità esaminando la domanda in questione:
Un tipo di relazione viene determinato in base al testo della domanda, ad esempio determinando che i termini "sposato con" nel testo della domanda probabilmente indicano una relazione coniugale tra un'entità indicata nel testo della domanda e un'entità indicata nel testo della risposta. Le entità sono identificate anche dal testo della domanda e dal testo della risposta. Ad esempio, il sistema informatico può identificare l'entità "Barack Obama" dal testo della domanda e l'entità "Michelle Obama" dal testo della risposta.
Dopo aver identificato un tipo di relazione e le due entità identificate dal testo della domanda e della risposta, viene determinata una relazione candidata. Ad esempio, la relazione del candidato determinato potrebbe essere una relazione coniugale tra le entità "Barack Obama" e "Michelle Obama".
Passare dalle risposte possibili alle risposte candidate
Il brevetto ci dice che un sito di domande e risposte potrebbe indicare una serie di potenziali risposte a una domanda su una relazione coniugale con Barack Obama, che potrebbe includere "Michelle Obama", "Hillary Clinton" o "Laura Bush".
In che modo Google potrebbe decidere quale risposta candidata è più probabile?
Google può assegnare un punteggio a ciascuna delle relazioni del candidato in base a una "frequenza con cui è stata determinata la relazione del candidato dalle pagine Web dei siti Web di domande e risposte. Il brevetto ci dice che:
La relazione candidata con il punteggio più alto viene selezionata come relazione valida più probabile per il particolare tipo di relazione ed entità. Ad esempio, basandosi sulla determinazione che la relazione coniugale del candidato tra "Barack Obama" e "Michelle Obama" è la relazione coniugale più frequente per l'entità "Barack Obama", il sistema informatico determina che esiste una relazione coniugale tra "Barack Obama" e "Michelle Obama". Il sistema informatico può quindi stabilire, in un modello entità-relazione, una relazione sponsale tra l'entità "Barack Obama" e l'entità "Michelle Obama".
Cosa c'è di innovativo nel processo descritto in questo brevetto? Ci dice che questi passaggi sono:
- Implica le azioni per ottenere una risorsa
- Identificare la prima porzione di testo della risorsa che si caratterizza come domanda
- La seconda parte del testo della risorsa che si caratterizza come risposta alla domanda
- Identificare un'entità a cui fa riferimento uno o più termini della prima porzione di testo caratterizzata come domanda
- Un tipo di relazione a cui fa riferimento uno o più altri termini della prima parte del testo caratterizzata come domanda
- Un'entità a cui fa riferimento la seconda porzione di testo che si caratterizza come la risposta alla domanda
- Regolazione di un punteggio associato a una relazione del tipo di relazione per l'entità a cui fa riferimento uno o più termini della prima porzione di testo caratterizzata come domanda e l'entità a cui fa riferimento la seconda porzione di testo caratterizzata come risposta alla domanda
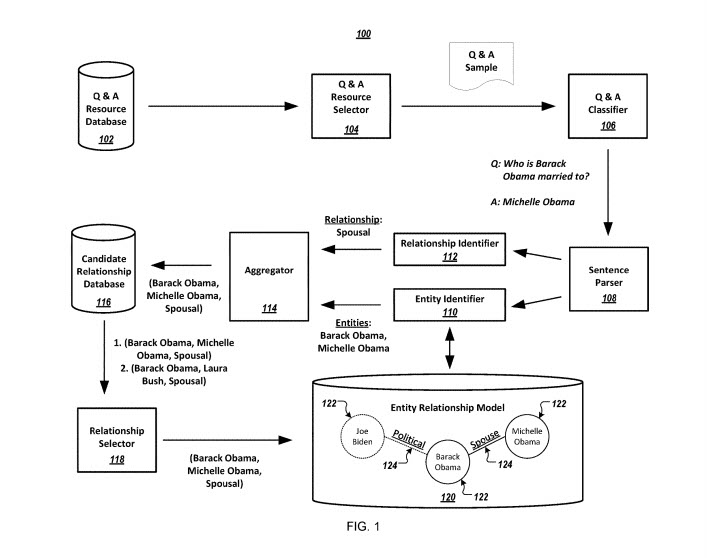
Questo processo utilizza siti Web di domande e risposte (Q&A)
Considera le domande come modelli per identificare la prima entità e il tipo di relazione visualizzati nella domanda, che ogni modello sul sito di domande e risposte può essere associato a un particolare tipo di relazione.
Questo brevetto sulle informazioni sulle relazioni tra entità può essere trovato all'indirizzo:
Estrazione di informazioni da siti Web di domande e risposte
Inventori: Wei Lwun Lu, Denis Savenkov, Amarnag Subramanya, Jeffrey Dalton, Evgeniy Gabrilovich, Eugene Agichtein
Assegnatario: Google LLC
Brevetto USA: 10.452.694
Concesso: 22 ottobre 2019
Archiviato: 20 dicembre 2017
Astratto
Metodi, sistemi e apparati per ottenere una risorsa, individuando una prima porzione di testo della risorsa che si caratterizza come domanda, e una seconda parte di testo della risorsa che si caratterizza come risposta alla domanda, individuando un'entità che è referenziato da uno o più termini del testo caratterizzato come domanda, un tipo di relazione referenziato da uno o più altri termini del testo caratterizzato come domanda e un'entità referenziata dal testo caratterizzato come la risposta alla domanda e aggiustando un punteggio per una relazione del tipo di relazione per l'entità a cui fa riferimento uno o più termini del testo che è caratterizzato come domanda e l'entità a cui fa riferimento il testo che si caratterizza come la risposta alla domanda.
Modelli di informazioni sulle relazioni tra entità
L'obiettivo di questo brevetto è la costruzione di un modello di relazione tra entità che specifichi le relazioni che sono determinate risorse del sito Web di domande e risposte.
Questo sistema include:
Un database di risorse di domande e risposte
Un selettore di risorse per domande e risposte
Un classificatore di domande e risposte
Un analizzatore di frasi
Un identificatore di entità
Un identificatore di relazione
Un aggregatore
Un database di relazioni tra candidati
Un selezionatore di relazioni
Un modello entità-relazione.
Le entità rappresentate nel modello entità-relazione possono essere rappresentate come nodi, con le relazioni tra entità rappresentate come bordi. I punteggi di confidenza sulle relazioni tra entità sono un'indicazione della probabile accuratezza di tali relazioni.
Quando si estrae informazioni sulle relazioni tra entità dalle risorse del sito Web di domande e risposte, questo sistema può esaminare un database di risorse di domande e risposte che include più risorse dai siti Web di domande e risposte.
Tali risorse possono includere:
- Un certo numero di pagine Web da siti Web di domande e risposte0, come le versioni archiviate delle pagine Web da siti Web di domande e risposte
- Metadati relativi alle pagine Web dei siti Web di domande e risposte
- Documenti accessibili sui siti web di domande e risposte
- Immagini accessibili sui siti web di domande e risposte
- Video accessibili sui siti web di domande e risposte
- Audio accessibile sui siti web di domande e risposte
- Altre risorse associate o accessibili sui siti Web di domande e risposte
Il database delle risorse di domande e risposte può anche includere risorse provenienti da fonti diverse dai siti Web di domande e risposte, come ad esempio:

- Una o più risorse dai siti Web del forum
- Piattaforme di social network
- Siti web di domande frequenti (FAQ) o pagine web di FAQ
- Siti informativi
- Altre fonti dove sono disponibili domande e risposte
Quando questo identificatore di domanda cerca domande e risposte che identificano entità e relazioni tra di loro, può iniziare ad analizzare il testo in una pagina di domande e risposte per trovare la presenza di determinati caratteri o stringhe di caratteri, come un punto interrogativo. Può anche cercare parole o domande che indicano il testo della domanda come:
- "Mi stavo chiedendo"
- "Sto chiedendo"
- "domanda"
- "chi"
- "che cosa"
- "dove"
- "quando"
- "perché"
- "come"
- eccetera.
Allo stesso modo, quando si cercano risposte, il testo sulle pagine può essere analizzato per trovare parole che potrebbero indicare il testo della risposta, come:
- "Lo so"
- "Credo"
- "Penso"
- "La risposta è"
- "Rispondere"
- eccetera.
La parte di questo processo che prevede l'analisi del testo su una pagina con un approccio di elaborazione del linguaggio naturale che etichetta parti del discorso:
Ad esempio, il parser di frasi può ricevere il testo della domanda "Con chi è sposato Barack Obama?" e può annotare il testo della domanda come "CHI/pronome È/verbo BARACK OBAMA/nome SPOSATO/aggettivo TO/verbo?" Allo stesso modo, il parser di frasi può ricevere il testo di risposta "Michelle Obama" e può annotare il testo di risposta come "MICHELLE OBAMA/sostantivo". Il parser di frasi può inoltre determinare una classe o un ipernimo di una o più unità grammaticali nei testi annotati, ad esempio, per determinare che i termini "Barack Obama" costituiscono una classe sostantivo "persona" e che i termini "Michelle Obama" costituiscono anche una classe di sostantivi "persona".
Dopo aver analizzato i testi di domanda e risposta, il parser di frase fornisce i testi di domanda e risposta annotati all'identificatore di entità e all'identificatore di relazione. In implementazioni alternative, il testo della domanda e/o il testo della risposta possono essere forniti all'identificatore di entità e all'identificatore di relazione senza elaborazione da parte del parser di frase. In tali implementazioni, l'identificatore di entità e/o l'identificatore di relazione possono eseguire operazioni simili a quelle eseguite dal parser di frase o possono identificare entità o relazioni dal testo della domanda e/o del testo della risposta senza che il testo della domanda o il testo della risposta sia annotato. In tali casi, il classificatore di domande e risposte può fornire i testi di domanda e risposta all'identificatore di entità e all'identificatore di relazione.
Il testo della domanda e il testo della risposta identificati possono identificare il tipo di relazione tra entità a cui si chiede e si risponde in una pagina di domande e risposte.
Un altro esempio di come una risposta potrebbe essere analizzata dal testo della domanda e dal testo della risposta:
Ad esempio, l'identificatore dell'entità può ricevere il testo della domanda "Con chi è sposato Barack Obama?" e identificare l'entità "Barack Obama" e può ricevere il testo di risposta "Vive con sua moglie Michelle Obama alla Casa Bianca" e identificare le entità "Michelle Obama" e "Casa Bianca". L'identificatore dell'entità può determinare che le entità "Barack Obama" e "Michelle Obama" sono ciascuna di una classe di nomi di "persona" e che l'entità "Casa Bianca" è di una classe di nomi di "luogo". L'identificatore dell'entità può selezionare le entità "Barack Obama" e "Michelle Obama" come entità potenzialmente correlate in base al fatto che entrambe le entità appartengono alla classe del sostantivo "persona", e quindi è più probabile che siano correlate in qualche modo rispetto a una particolare persona essere in relazione con un luogo particolare.
Quali altri tipi di informazioni sulle relazioni tra entità possono essere trovate utilizzando un approccio come questo?
- Relazioni di coppia
- Relazioni familiari
- Relazioni politiche
- Relazioni commerciali
- Rapporti di proprietà
- Relazioni di residenza
- Relazioni con il luogo di nascita
- Rapporti dipendente/datore di lavoro
- Rapporti di lavoro
- Altre relazioni tra persone, luoghi o cose
Alcuni altri tipi di informazioni sulle relazioni tra entità
Tra entità particolari e valori numerici o date. Tali valori numerici possono includere:
- L'età di una persona
- Valore netto
- Numero di maglia
- Altezza
- Data di nascita
- Data del matrimonio
- Data di morte
- Data di fondazione di un'impresa
- Città con una dimensione della popolazione
- eccetera.
Un "matcher" può determinare se una particolare domanda si adatta a un particolare modello accessibile dall'identificatore di relazione, creando un modello come "Con chi è [PERSON] sposata?" una relazione su cui raccogliere informazioni.
Il brevetto cerca di fare un punto dicendoci che questi modelli cercherebbero di abbinare i giusti tipi di entità con i modelli, quindi un'entità che potrebbe indicare un luogo potrebbe non funzionare con un identificatore di relazione che determina un tipo di relazione coniugale, fornendo l'esempio : "Con chi è sposata l'America?"
Quindi ho provato quella query e ho ottenuto una risposta inaspettata:

Conclusione
Google ha appena annunciato che stava utilizzando un approccio di elaborazione del linguaggio naturale chiamato BERT. Ho menzionato questo approccio quando ho scritto il post Semantic Frames and Word Embeddings su Google a maggio. Questo brevetto fornisce un buon esempio di come l'elaborazione del linguaggio naturale potrebbe essere utilizzata per comprendere le domande e le risposte nelle pagine di domande e risposte e se queste si adattano ad alcuni modelli noti per identificare le relazioni tra le entità e le proprietà delle entità.
Il brevetto fornisce alcuni esempi aggiuntivi di come potrebbe tentare di acquisire maggiore fiducia nelle relazioni tra le entità o le proprietà di tali entità. Ma questo brevetto è abbastanza descrittivo di come le informazioni sulle relazioni tra entità possono essere estratte dai siti Web di domande e risposte.