
Wie kann Google Informationen zu Entitätsbeziehungen aus Q&A-Seiten extrahieren?
Veröffentlicht: 2019-10-30Wie hilfreich könnten Frage-und-Antwort-Websites sein, um einer Suchmaschine Informationen über Entitäten und Entitätsbeziehungsinformationen über diese Entitäten und andere Entitäten und Eigenschaften von Entitäten bereitzustellen?
Ein kürzlich von Google erteiltes Patent untersucht solche potenziellen Informationsquellen und verrät uns mehr.
Einer der Erfinder dieses Patents, Evgeniy Gabrilovich, arbeitete an Googles Knowledge Vault-Projekt, das sich mit Dingen wie dem Extrahieren von Beziehungsinformationen aus Texten im Web über Entitäten befasst. Es lohnt sich, sich eine Präsentation anzusehen, die während der Entwicklung des Knowledge Vault-Projekts erstellt wurde, um zu sehen, was sie über das Extrahieren von Entitätsbeziehungsinformationen aus dem Web sagt. Diese finden Sie unter: Constructing and Mining Web-scale Knowledge Graphs
Kandidatenbeziehungen zwischen Entitäten
Dieses Patent, das Google am 22. Oktober 2019 erteilt wurde, sagt uns, wie solche Websites als Ressourcen verwendet werden können, um Informationen über Beziehungen zwischen Unternehmen bereitzustellen, wie zum Beispiel „Wer ist Barack Obama verheiratet?“ Diese Seite kann auch die Antwort „Michelle Obama“ enthalten.
Das Patent weist darauf hin, dass solche Seiten Entitätsbeziehungen identifizieren können, indem sie sich die damit verbundene Frage ansehen:
Ein Beziehungstyp wird basierend auf dem Fragetext bestimmt, zum Beispiel indem bestimmt wird, dass die Begriffe "verheiratet mit" im Fragetext wahrscheinlich eine eheliche Beziehung zwischen einer im Fragetext angegebenen Entität und einer im Antworttext angegebenen Entität angeben. Entitäten werden auch aus dem Fragetext und dem Antworttext identifiziert. Beispielsweise kann das Computersystem aus dem Fragetext die Entität „Barack Obama“ und aus dem Antworttext die Entität „Michelle Obama“ identifizieren.
Nachdem ein Beziehungstyp und die beiden durch den Frage- und Antworttext identifizierten Entitäten identifiziert wurden, wird eine Kandidatenbeziehung bestimmt. Beispielsweise kann es sich bei dem ermittelten Kandidatenverhältnis um ein Ehegattenverhältnis zwischen den Entitäten „Barack Obama“ und „Michelle Obama“ handeln.
Von möglichen Antworten zu Kandidatenantworten wechseln
Das Patent sagt uns, dass eine Q&A-Site möglicherweise eine Reihe potenzieller Antworten auf eine Frage zu einer Ehegattenbeziehung mit Barack Obama enthält, die „Michelle Obama“, „Hillary Clinton“ oder „Laura Bush“ umfassen könnte.
Wie könnte Google entscheiden, welche Kandidatenantwort am wahrscheinlichsten ist?
Google kann jede der Kandidatenbeziehungen basierend auf einer „Häufigkeit, mit der die Kandidatenbeziehung anhand der Webseiten der Q&A-Websites bestimmt wurde, bewerten. Das Patent sagt uns Folgendes:
Die Kandidatenbeziehung mit der höchsten Punktzahl wird als die wahrscheinlichste gültige Beziehung für den bestimmten Beziehungstyp und die Entität ausgewählt. Basierend auf der Feststellung, dass beispielsweise die anwärterliche Ehegattenbeziehung zwischen „Barack Obama“ und „Michelle Obama“ die am häufigsten vorkommende Ehegattenbeziehung für die Entität „Barack Obama“ ist, bestimmt das Computersystem, dass zwischen „Barack Obama“ eine Ehegatte besteht. und „Michelle Obama“. Das Computersystem kann dann in einem Entity-Relationship-Modell eine Ehegattenbeziehung zwischen der Entität „Barack Obama“ und der Entität „Michelle Obama“ herstellen.
Was ist das Innovative an dem in diesem Patent beschriebenen Verfahren? Es sagt uns, dass diese Schritte sind:
- Es beinhaltet die Aktionen des Erhaltens einer Ressource
- Identifizieren des ersten Textabschnitts der Ressource, der als Frage gekennzeichnet ist
- Der zweite Textteil der Ressource, der als Antwort auf die Frage gekennzeichnet ist
- Identifizieren einer Entität, auf die durch einen oder mehrere Begriffe des ersten Textabschnitts verwiesen wird, der als Frage gekennzeichnet ist
- Ein Beziehungstyp, auf den von einem oder mehreren anderen Begriffen des ersten Teils des Textes verwiesen wird, der als Frage bezeichnet wird
- Eine Entität, auf die durch den zweiten Textabschnitt verwiesen wird, der als Antwort auf die Frage gekennzeichnet ist
- Anpassen einer Bewertung, die einer Beziehung des Beziehungstyps für die Entität zugeordnet ist, auf die durch den einen oder die mehreren Begriffe des ersten Textabschnitts verwiesen wird, der als Frage gekennzeichnet ist, und die Entität, auf die durch den zweiten gekennzeichneten Textabschnitt verwiesen wird als Antwort auf die Frage
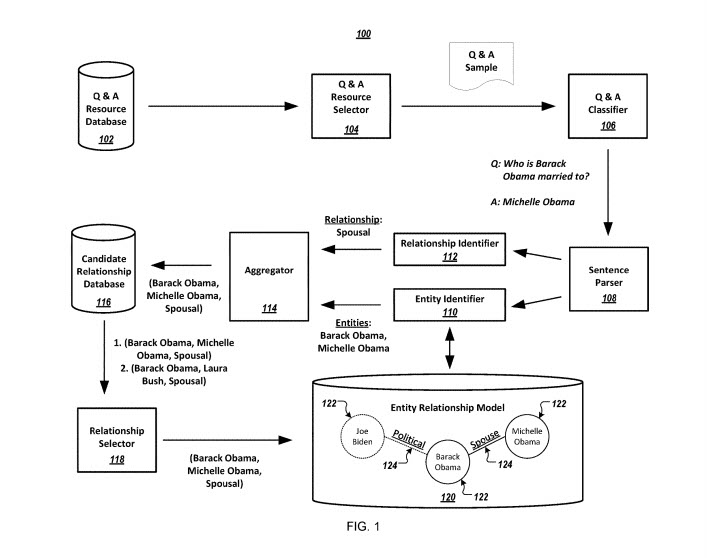
Dieser Prozess verwendet Frage-und-Antwort-(Q&A)-Websites
Es betrachtet Fragen als Vorlagen, um die erste Entität und den in der Frage angezeigten Beziehungstyp zu identifizieren, wobei jede Vorlage auf der Q&A-Site einem bestimmten Beziehungstyp zugeordnet werden kann.
Dieses Patent für Informationen über Entitätsbeziehungen finden Sie unter:
Informationsextraktion aus Frage-und-Antwort-Websites
Erfinder: Wei Lwun Lu, Denis Savenkov, Amarnag Subramanya, Jeffrey Dalton, Evgeniy Gabrilovich, Eugene Agichtein
Rechtsnachfolger: Google LLC
US-Patent: 10.452.694
Bewilligt: 22. Oktober 2019
Gespeichert: 20. Dezember 2017
Abstrakt
Verfahren, Systeme und Vorrichtungen zum Erhalten einer Ressource, die einen ersten Textteil der Ressource identifiziert, der als Frage gekennzeichnet ist, und einen zweiten Textteil der Ressource, der als Antwort auf die Frage gekennzeichnet ist, der eine Entität identifiziert, die wird von einem oder mehreren Begriffen des Textes referenziert, der als Frage gekennzeichnet ist, einem Beziehungstyp, der von einem oder mehreren anderen Begriffen des Textes referenziert wird, der als Frage gekennzeichnet ist, und einer Entität, auf die von dem Text verwiesen wird, der ist gekennzeichnet als die Antwort auf die Frage, und Anpassen einer Bewertung für eine Beziehung des Beziehungstyps für die Entität, auf die durch den einen oder die mehreren Begriffe des Textes verwiesen wird, der als Frage gekennzeichnet ist, und die Entität, auf die durch den Text verwiesen wird, der wird als Antwort auf die Frage charakterisiert.
Informationsmodelle für Entitätsbeziehungen
Der Schwerpunkt dieses Patents liegt auf dem Aufbau eines Entity-Relationship-Modells, das Beziehungen spezifiziert, die bestimmte Q&A-Website-Ressourcen sind.
Dieses System beinhaltet:
Eine Q&A-Ressourcendatenbank
Eine Q&A-Ressourcenauswahl
Ein Q&A-Klassifikator
Ein Satzparser
Eine Entitätskennung
Eine Beziehungskennung
Ein Aggregator
Eine Datenbank mit Kandidatenbeziehungen
Ein Beziehungswähler
Ein Entity-Relationship-Modell.
Im Entity-Relationship-Modell repräsentierte Entitäten können als Knoten dargestellt werden, wobei Beziehungen zwischen Entitäten als Kanten dargestellt werden. Die Konfidenzbewertungen zu den Entitätsbeziehungen sind ein Hinweis auf eine wahrscheinliche Genauigkeit dieser Beziehungen.
Beim Extrahieren von Entitätsbeziehungsinformationen aus Q&A-Website-Ressourcen kann dieses System eine Q&A-Ressourcendatenbank einsehen, die mehrere Ressourcen von Q&A-Websites enthält.

Diese Ressourcen können umfassen:
- Eine Reihe von Webseiten von Q&A-Websites0, z. B. archivierte Versionen der Webseiten von Q&A-Websites
- Metadaten zu Webseiten von Q&A-Websites
- Dokumente, auf die auf Q&A-Websites zugegriffen werden kann
- Bilder, die auf Q&A-Websites zugänglich sind
- Videos, auf die auf Q&A-Websites zugegriffen werden kann
- Audio verfügbar auf Q&A-Websites
- Andere Ressourcen, die mit Q&A-Websites verbunden oder auf diesen zugänglich sind
Die Q&A-Ressourcendatenbank kann auch Ressourcen aus anderen Quellen als Q&A-Websites enthalten, wie zum Beispiel:
- Eine oder mehrere Ressourcen von Foren-Websites
- Soziale Netzwerkplattformen
- Websites mit häufig gestellten Fragen (FAQ) oder FAQ-Websites
- Informationsseiten
- Andere Quellen, in denen Fragen und Antworten verfügbar sind
Wenn dieser Fragenbezeichner nach Fragen und Antworten sucht, die Entitäten und Beziehungen zwischen ihnen identifizieren, beginnt er möglicherweise mit dem Parsen von Text auf einer Q&A-Seite, um das Vorhandensein bestimmter Zeichen oder Zeichenfolgen, wie z. B. ein Fragezeichen, zu finden. Es kann auch nach Wörtern oder Fragen gesucht werden, die auf den Fragetext hinweisen, wie zum Beispiel:
- "Ich frage mich"
- "Ich frage"
- "Frage"
- "Wer"
- "was"
- "wo"
- "Wenn"
- "warum"
- "wie"
- etc.
Auf die gleiche Weise kann bei der Suche nach Antworten der Text auf den Seiten analysiert werden, um Wörter zu finden, die auf einen Antworttext hinweisen könnten, wie zum Beispiel:
- "Ich weiss"
- "Ich glaube"
- "Ich denke"
- "Die Antwort ist"
- "Antworten"
- etc.
Der Teil dieses Prozesses, der das Parsen von Text auf einer Seite mit einem Ansatz zur Verarbeitung natürlicher Sprache beinhaltet, der Wortarten markiert:
Als Beispiel kann der Satzparser den Fragetext „Wer ist Barack Obama verheiratet?“ erhalten. und kann den Fragetext als „WHO/Pronomen IS/Verb BARACK OBAMA/Substantiv VERHEIRATET/Adjektiv TO/Verb?“ annotieren. Ebenso kann der Satzparser den Antworttext „Michelle Obama“ empfangen und den Antworttext als „MICHELLE OBAMA/Substantiv“ kommentieren. Der Satzparser kann ferner eine Klasse oder ein Hypernym einer oder mehrerer grammatikalischer Einheiten in den annotierten Texten bestimmen, um beispielsweise zu bestimmen, dass die Begriffe „Barack Obama“ eine Substantivklasse „Person“ darstellen und dass die Begriffe „Michelle Obama“ auch bilden eine "Person"-Substantivklasse.
Nach dem Parsen der Frage- und Antworttexte stellt der Satzparser die annotierten Frage- und Antworttexte an die Entitätskennung und Beziehungskennung bereit. In alternativen Implementierungen können der Fragetext und/oder der Antworttext dem Entitätsidentifizierer und dem Beziehungsidentifizierer ohne Verarbeitung durch den Satzparser bereitgestellt werden. In solchen Implementierungen kann der Entitätsidentifizierer und/oder der Beziehungsidentifizierer Operationen ähnlich denen durchführen, die vom Satzparser durchgeführt werden, oder kann Entitäten oder Beziehungen aus dem Fragetext und/oder Antworttext identifizieren, ohne dass der Fragetext oder Antworttext kommentiert wird. In solchen Fällen kann der Q&A-Klassifikator die Frage- und Antworttexte zur Entitätskennung und Beziehungskennung bereitstellen.
Der Fragetext und der Antworttext, die identifiziert werden, können die Art der Entity-Relation identifizieren, nach der gefragt und auf einer Q&A-Seite beantwortet wird.
Ein weiteres Beispiel dafür, wie eine Antwort aus Fragetext und Antworttext geparst werden könnte:
Die Entitätskennung kann beispielsweise den Fragetext „Wer ist Barack Obama verheiratet?“ erhalten. und identifizieren Sie die Entität „Barack Obama“ und erhalten Sie möglicherweise den Antworttext „Er lebt mit seiner Frau Michelle Obama im Weißen Haus“ und identifizieren Sie die Entitäten „Michelle Obama“ und „Weißes Haus“. Der Entitätsidentifikator kann bestimmen, dass die Entitäten „Barack Obama“ und „Michelle Obama“ jeweils einer Substantivklasse „Person“ angehören und dass die Entität „White House“ einer Substantivklasse „Ort“ angehört. Die Entitätskennung kann die Entitäten „Barack Obama“ und „Michelle Obama“ als potenziell verwandte Entitäten auswählen, basierend darauf, dass beide Entitäten der Nomenklasse „Person“ angehören und daher eher in irgendeiner Weise verwandt sind als eine bestimmte Person auf einen bestimmten Ort bezogen sein.
Welche anderen Arten von Entitäts-Beziehungs-Informationen können mit einem solchen Ansatz gefunden werden?
- Ehegattenbeziehungen
- Familiäre Beziehungen
- Politische Beziehungen
- Geschäftsbeziehungen
- Eigentumsverhältnisse
- Wohnverhältnisse
- Beziehungen zum Geburtsort
- Arbeitnehmer/Arbeitgeber-Beziehungen
- Berufliche Beziehungen
- Andere Beziehungen zwischen Menschen, Orten oder Dingen
Einige andere Arten von Entitätsbeziehungsinformationen
Zwischen bestimmten Entitäten und numerischen Werten oder Daten. Solche numerischen Werte können umfassen:
- Das Alter einer Person
- Reinvermögen
- Trikot-Nummer
- Höhe
- Geburtsdatum
- Hochzeitsdatum
- Sterbedatum
- Datum der Unternehmensgründung
- Stadt mit einer Einwohnerzahl
- etc.
Ein „Matcher“ kann feststellen, ob eine bestimmte Frage zu einer bestimmten Vorlage passt, auf die durch die Beziehungskennung zugegriffen werden kann, und eine Vorlage erstellen, z. B. „Wer ist [PERSON] verheiratet?“ eine Beziehung, um Informationen zu sammeln.
Das Patent versucht, uns klarzumachen, dass diese Vorlagen versuchen würden, die richtigen Arten von Entitäten mit Vorlagen abzugleichen : „Mit wem ist Amerika verheiratet?“
Also habe ich diese Abfrage ausprobiert und eine unerwartete Antwort erhalten:

Fazit
Google hat gerade angekündigt, dass es einen Ansatz zur Verarbeitung natürlicher Sprache namens BERT verwendet. Ich habe diesen Ansatz erwähnt, als ich im Mai den Beitrag Semantic Frames and Word Embeddings bei Google geschrieben habe. Dieses Patent bietet ein gutes Beispiel dafür, wie die Verarbeitung natürlicher Sprache verwendet werden könnte, um Fragen und Antworten auf Q&A-Seiten zu verstehen, und ob diese zu einigen bekannten Vorlagen passen, um Beziehungen zwischen Entitäten und Eigenschaften von Entitäten zu identifizieren.
Das Patent bietet einige zusätzliche Beispiele dafür, wie es versuchen könnte, mehr Vertrauen in die Beziehungen zwischen Entitäten oder Eigenschaften dieser Entitäten zu gewinnen. Dieses Patent beschreibt jedoch ziemlich gut, wie Informationen zu Entitätenbeziehungen aus Q&A-Websites extrahiert werden können.