
Cum ar putea Google să extragă informații despre relația dintre entități din paginile de întrebări și răspunsuri?
Publicat: 2019-10-30Cât de utile ar putea fi site-urile web cu întrebări și răspunsuri în furnizarea unui motor de căutare cu informații despre entități și informații despre relația dintre entități despre acele entități și alte entități și proprietăți ale entităților?
Un brevet recent acordat de Google analizează astfel de surse potențiale de informații și ne spune mai multe.
Unul dintre inventatorii acestui brevet, Evgeniy Gabrilovich, a lucrat la proiectul seifului de cunoștințe al Google, care vorbește despre lucruri precum extragerea de informații despre relații din textul de pe web despre entități. Merită să priviți o prezentare care a fost pregătită în timpul dezvoltării proiectului seifului cunoașterii pentru a vedea ce spune despre extragerea informațiilor entitate-relație de pe Web. Acesta poate fi găsit la: Constructing and Mining Web-scale Knowledge Graphs
Relațiile candidaților între entități
Acest brevet, acordat Google la 22 octombrie 2019, ne spune despre cum astfel de site-uri pot fi folosite ca resurse pentru a oferi informații despre relațiile dintre entități, cum ar fi „Cu cine este căsătorit Barack Obama?” Această pagină poate include, de asemenea, răspunsul „Michelle Obama”.
Brevetul subliniază că astfel de pagini pot identifica relațiile dintre entități analizând întrebarea implicată:
Un tip de relație este determinat pe baza textului întrebării, de exemplu, determinând că termenii „căsătorit cu” din textul întrebării indică probabil o relație de soț între o entitate indicată în textul întrebării și o entitate indicată în textul răspunsului. Entitățile sunt identificate și din textul întrebării și din textul răspunsului. De exemplu, sistemul informatic poate identifica entitatea „Barack Obama” din textul întrebării și entitatea „Michelle Obama” din textul răspunsului.
După identificarea unui tip de relație și a celor două entități identificate prin textul de întrebare și răspuns, se determină o relație candidat. De exemplu, relația de candidat determinată poate fi o relație de soț între entitățile „Barack Obama” și „Michelle Obama”.
Trecerea de la răspunsurile posibile la răspunsurile candidatului
Brevetul ne spune că un site de întrebări și răspunsuri poate indica un număr de răspunsuri potențiale la o întrebare despre o relație de soț cu Barack Obama, care ar putea include „Michelle Obama”, „Hillary Clinton” sau „Laura Bush”.
Cum ar putea Google să decidă ce răspuns candidat este cel mai probabil?
Google poate nota fiecare dintre relațiile candidate pe baza „frecvenței cu care relația candidatului a fost determinată din paginile web ale site-urilor web de întrebări și răspunsuri. Brevetul ne spune că:
Relația candidată care are cel mai mare punctaj este selectată ca relație validă cel mai probabil pentru tipul de relație și entitate particulară. De exemplu, pe baza determinării faptului că relația de soț candidat între „Barack Obama” și „Michelle Obama” este cea mai frecventă relație de soț pentru entitatea „Barack Obama”, sistemul informatic determină că între „Barack Obama” există o relație de soț. și „Michelle Obama”. Sistemul informatic poate stabili apoi, într-un model entitate-relație, o relație conjugală între entitatea „Barack Obama” și entitatea „Michelle Obama”.
Ce este inovator în procesul descris în acest brevet? Ne spune că acești pași sunt:
- Presupune actiunile de obtinere a unei resurse
- Identificarea primei porțiuni de text a resursei care este caracterizată ca întrebare
- A doua parte de text a resursei care este caracterizată ca răspuns la întrebare
- Identificarea unei entități la care se face referire prin unul sau mai mulți termeni din prima porțiune de text care este caracterizată ca întrebare
- Un tip de relație la care face referire unul sau mai mulți alți termeni ai primei părți a textului care este caracterizat ca întrebare
- O entitate la care face referire a doua porțiune de text care este caracterizată ca răspuns la întrebare
- Ajustarea unui scor asociat cu o relație de tipul relației pentru entitatea la care face referire unul sau mai mulți termeni din prima porțiune de text care este caracterizată ca întrebare și entitatea la care se face referire de a doua porțiune de text care este caracterizată ca răspuns la întrebare
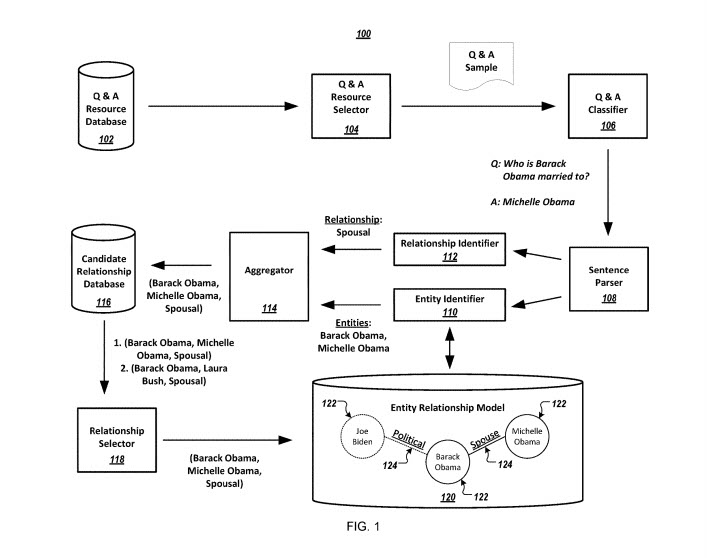
Acest proces folosește site-uri web cu întrebări și răspunsuri (Întrebări și răspunsuri).
Acesta privește întrebările ca șabloane pentru a identifica prima entitate și tipul de relație afișat în întrebare, fiecare șablon de pe site-ul de întrebări și răspunsuri poate fi asociat cu un anumit tip de relație.
Acest brevet de informații despre relația cu entitate poate fi găsit la:
Extragerea de informații de pe site-uri web cu întrebări și răspunsuri
Inventatori: Wei Lwun Lu, Denis Savenkov, Amarnag Subramanya, Jeffrey Dalton, Evgeniy Gabrilovich, Eugene Agichtein
Cesionar: Google LLC
Brevet SUA: 10.452.694
Acordat: 22 octombrie 2019
Depus: 20 decembrie 2017
Abstract
Metode, sisteme și aparate pentru obținerea unei resurse, identificând o primă porțiune de text a resursei care este caracterizată ca o întrebare și o a doua parte de text a resursei care este caracterizată ca răspuns la întrebare, identificând o entitate care este referit de unul sau mai mulți termeni ai textului care este caracterizat ca întrebare, un tip de relație care este referit de unul sau mai mulți alți termeni ai textului care este caracterizat ca întrebare și o entitate care este referită de textul care este caracterizat ca răspuns la întrebare și ajustarea unui scor pentru o relație de tipul relației pentru entitatea la care se face referire prin unul sau mai mulți termeni ai textului care este caracterizat ca întrebare și entitatea la care se face referire de textul care este caracterizat ca răspunsul la întrebare.
Modele de informații privind relațiile cu entitate
Accentul acestui brevet este pe construirea unui model entitate-relație care specifică relațiile care sunt determinate de resursele site-ului de întrebări și răspunsuri.
Acest sistem include:
O bază de date cu resurse de întrebări și răspunsuri
Un selector de resurse pentru întrebări și răspunsuri
Un clasificator de întrebări și răspunsuri
Un analizator de propoziții
Un identificator de entitate
Un identificator de relație
Un agregator
O bază de date cu relațiile candidaților
Un selector de relații
Un model entitate-relație.
Entitățile reprezentate în modelul entitate-relație pot fi reprezentate ca noduri, relațiile dintre entități fiind reprezentate ca margini. Scorurile de încredere cu privire la relațiile cu entitate sunt un indiciu al unei exactități probabile a acestor relații care sunt adevărate.
Atunci când extrage informații despre relația dintre entități din resursele site-ului Web de întrebări și răspunsuri, acest sistem poate analiza o bază de date de resurse de întrebări și răspunsuri care include mai multe resurse de pe site-urile Web de întrebări și răspunsuri.
Aceste resurse pot include:
- Un număr de pagini web de pe site-urile web de întrebări și răspunsuri0, cum ar fi versiunile arhivate ale paginilor web de pe site-urile web de întrebări și răspunsuri
- Metadate referitoare la paginile web ale site-urilor web de întrebări și răspunsuri
- Documente accesibile pe site-urile web de întrebări și răspunsuri
- Imagini accesibile pe site-urile web de întrebări și răspunsuri
- Videoclipuri accesibile pe site-urile web de întrebări și răspunsuri
- Audio accesibil pe site-urile Web de întrebări și răspunsuri
- Alte resurse asociate sau accesibile pe site-urile Web de întrebări și răspunsuri
Baza de date cu resurse de întrebări și răspunsuri poate include și resurse din alte surse decât site-urile web de întrebări și răspunsuri, cum ar fi:

- Una sau mai multe resurse de pe site-urile forumurilor
- Platforme de rețele sociale
- Site-uri web cu întrebări frecvente (FAQ) sau pagini web cu întrebări frecvente
- Site-uri web informative
- Alte surse în care sunt disponibile întrebări și răspunsuri
Atunci când acest identificator de întrebare caută întrebări și răspunsuri care identifică entitățile și relațiile dintre ele, poate începe să analizeze textul pe o pagină de întrebări și răspunsuri pentru a găsi prezența anumitor caractere sau șiruri de caractere, cum ar fi un semn de întrebare. De asemenea, poate căuta cuvinte sau întrebări care indică textul întrebării, cum ar fi:
- "Mă întrebam"
- "Intreb"
- "întrebare"
- "care"
- "ce"
- "Unde"
- "când"
- "De ce"
- "Cum"
- etc.
În același mod, atunci când se caută răspunsuri, textul de pe pagini poate fi analizat pentru a găsi cuvinte care ar putea indica textul răspunsului, cum ar fi:
- "Stiu"
- "Eu cred"
- "Cred că"
- "Raspunsul este"
- "Răspuns"
- etc.
Partea acestui proces care implică analizarea textului de pe o pagină printr-o abordare de procesare a limbajului natural care etichetează părți de vorbire:
De exemplu, analizatorul de propoziții poate primi textul întrebării „Cu cine este căsătorit Barack Obama?” și poate adnota textul întrebării ca „CINE/pronume ESTE/verb BARACK OBAMA/substantiv CĂSATORIT/adjectiv TO/verb?” În mod similar, analizatorul de propoziții poate primi textul de răspuns „Michelle Obama” și poate adnota textul de răspuns ca „MICHELLE OBAMA/substantiv”. Analizatorul de propoziții poate determina în continuare o clasă sau un hipernim al uneia sau mai multor unități gramaticale în textele adnotate, de exemplu, pentru a determina că termenii „Barack Obama” constituie o clasă de substantive „persoană” și că termenii „Michelle Obama” constituie, de asemenea, o clasă de substantive „persoană”.
După ce a analizat textele de întrebare și răspuns, analizatorul de propoziții furnizează textele de întrebare și răspuns adnotate identificatorului de entitate și identificatorului de relație. În implementări alternative, textul întrebării și/sau textul răspunsului pot fi furnizate identificatorului de entitate și identificatorului de relație fără procesare de către analizatorul de propoziții. În astfel de implementări, identificatorul de entitate și/sau identificatorul de relație poate efectua operații similare cu cele efectuate de analizatorul de propoziții sau poate identifica entități sau relații din textul întrebării și/sau textul răspunsului fără ca textul întrebării sau textul răspunsului să fie adnotat. În astfel de cazuri, clasificatorul de întrebări și răspunsuri poate furniza textele de întrebare și răspuns la identificatorul de entitate și identificatorul de relație.
Textul întrebării și textul răspunsului care sunt identificate pot identifica tipul de entitate-relație despre care este întrebat și răspuns pe o pagină de întrebări și răspunsuri.
Un alt exemplu despre modul în care un răspuns poate fi analizat din textul întrebării și textul răspunsului:
De exemplu, identificatorul entității poate primi textul de întrebare „Cu cine este căsătorit Barack Obama?” și identificați entitatea „Barack Obama” și poate primi textul de răspuns „El locuiește cu soția lui Michelle Obama la Casa Albă” și identificați entitățile „Michelle Obama” și „Casa Albă”. Identificatorul de entitate poate determina că entitățile „Barack Obama” și „Michelle Obama” sunt fiecare dintr-o clasă de substantive „persoană” și că entitatea „Casa Albă” este dintr-o clasă de substantive „loc”. Identificatorul de entitate poate selecta entitățile „Barack Obama” și „Michelle Obama” ca entități potențial înrudite, pe baza faptului că ambele entități aparțin clasei substantive „persoană” și, prin urmare, este mai probabil să fie înrudite într-un fel decât o anumită persoană. fie legat de un anumit loc.
Ce alte tipuri de informații entitate-relație pot fi găsite folosind o abordare ca aceasta?
- Relațiile conjugale
- Relații familiale
- Relații politice
- Relații de afaceri
- Relații de proprietate
- Relații de rezidență
- Relații cu locul nașterii
- Relații angajat/angajator
- Relații profesionale
- Alte relații între oameni, locuri sau lucruri
Alte tipuri de informații despre relația cu entitate
Între anumite entități și valori numerice sau date. Astfel de valori numerice pot include:
- Vârsta unei persoane
- Valoarea netă
- Numărul de jerseu
- Înălţime
- Data de nastere
- Data nunții
- Data mortii
- Data înființării unei afaceri
- Oraș cu o dimensiune a populației
- etc.
Un „potrivitor” poate determina dacă o anumită întrebare se potrivește cu un anumit șablon accesibil prin identificatorul de relație, creând un șablon precum „Cu cine este [PERSOANA] căsătorită?” o relație pentru a colecta informații despre.
Brevetul încearcă să ne spună că aceste șabloane ar încerca să potrivească tipurile potrivite de entități cu șabloane, astfel încât o entitate care poate indica un loc ar putea să nu funcționeze cu un identificator de relație care determină un tip de relație de soț, oferind exemplul : „Cu cine este căsătorită America?”
Așa că am încercat acea interogare și am primit un răspuns neașteptat:

Concluzie
Google tocmai a anunțat că folosește o abordare de procesare a limbajului natural numită BERT. Am menționat această abordare când am scris postarea Semantic Frames and Word Embeddings la Google în luna mai. Acest brevet oferă un exemplu bun despre modul în care procesarea limbajului natural ar putea fi utilizată pentru a înțelege întrebările și răspunsurile din paginile de întrebări și răspunsuri și dacă acestea se potrivesc unor șabloane cunoscute pentru a identifica relațiile dintre entități și proprietățile entităților.
Brevetul oferă câteva exemple suplimentare despre cum ar putea încerca să câștige mai multă încredere în relațiile dintre entități sau proprietăți ale acelor entități. Dar acest brevet este destul de descriptiv despre modul în care informațiile dintre entitate-relația pot fi extrase de pe site-urile web de întrebări și răspunsuri.