
谷歌搜索查询的语义主题建模
已发表: 2016-12-29
什么是语义主题建模?
我在谷歌研究页面上看到了一些关于语义主题建模的有趣论文,我认为这些论文值得分享。 其中一个让我想起了谷歌在不同查询的排名靠前的页面中使用短语的共现以及如何使用它来更好地理解网站上的主题建模。 我在 Go Fish Digital 博客上的一篇文章中写到了这一点,我称之为“使用文档和锚文本中的相关词进行主题建模”
让我想起那篇文章的论文是这样的:
使用 Word Co-Occurrence 和 bigraph co-clustering 改进搜索查询的语义主题聚类。 该论文由 Jing Kong、Alex Scott 和 Georg M. Goerg 撰写
语义主题建模技术
该论文的摘要告诉我们,“我们提出了两种新技术,可以在搜索查询中发现语义上有意义的主题:(i)单词共现聚类从频繁出现的单词中生成主题; (ii) 加权双图聚类使用来自 Google 搜索结果的 URL 来诱导查询相似性并生成主题。”
该论文提供了有关 Lipton Brand 产品的页面集以及涉及化妆品和化妆品的查询的示例。
从查询信息中学习
查询信息可以提供有趣且有用的业务洞察。 了解人们搜索特定产品和品牌的频率可以告诉我们有多少人对这些产品感兴趣,以及人们可能会与这些品牌相关联的内容。 例如,将产品分类为“美容产品”等类别可以让我们深入了解人们在流行趋势中搜索的内容。
在尝试从看起来像这样的主题中学习时可能遇到的困难之一是它们出现在缩短的上下文中,例如推文和查询,这意味着您不会从出现在它们附近的其他术语或跟他们。 例如,“Lipton”这个词可能经常出现在与“tea”和“soup”相关的词附近。
单词共现是指相同的术语或短语在文档中频繁出现(不包括停用词),对于特定的查询术语可能排名靠前,这意味着这些词可能与它们排名靠前的术语在语义上相关。
双词聚类方法可能涉及从大量文档中对某个查询进行排名的词,并将它们放在一起,然后提取出现在这些文档中的两个词词(并根据它们出现的频率对它们进行聚类)。
语义主题建模技术的目的
该论文详细介绍了这些词共现和加权双图聚类方法以及它们的使用方式。
请记住,本文的重点是描述这两种不同的方法如何帮助更好地理解正在显示的可能有些相关的主题。 当谈论“立顿”时,是在“茶”还是“汤”的上下文中?
一系列与品牌相关的查询可以展示可能与这些查询相关的主题。 我们看到这张表是为了给我们一些例子:
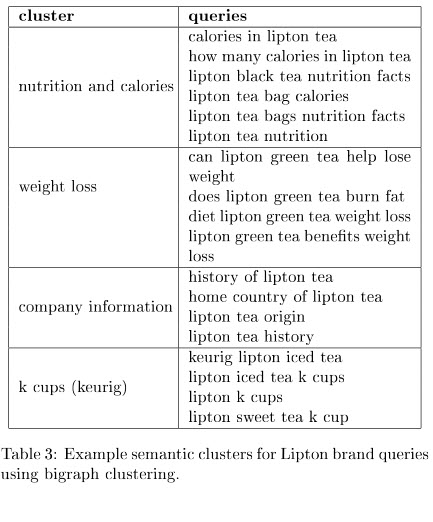
在语义主题建模论文的讨论部分,他们告诉我们哪种方法在不同情况下效果最好。 这是一个有趣的结论,让我想做更多的研究。
论文引用的见解
幸运的是,这篇论文中的引文看起来可能值得探索,所以我找到了其中大部分页面的链接,以及一些从中给出了一些含义的摘录。 其中一些似乎已经存在了一段时间,而另一些似乎讨论了您过去可能已经看到的主题。 其中一些特别适用于以文本量很少而闻名的社交媒体,例如 Twitter。 其中许多看起来很有趣,我想找到它们的链接,并阅读更多(并认为它们值得分享)
搜索引擎查询日志的凝聚聚类 (2000)
这里应用的聚类策略来自两个相关的观察结果。 首先,具有相同信息需求的用户可能会针对搜索引擎、猎豹和野猫用不同的方式表达他们的查询,但从为满足该需求而提供的 URL 中选择相同的 URL 表明这些查询是相关的。 其次,用户发出相同的查询后,可能会访问两个不同的URL www.funds.com 和www.mutualfunds.com,可见这两个URL 是相似的。
潜在狄利克雷分配

在本文中,我们考虑建模文本语料库和其他离散数据集合的问题。 目标是找到集合成员的简短描述,从而能够有效处理大型集合,同时保留对基本任务(例如分类、新颖性检测、摘要以及相似性和相关性判断)有用的基本统计关系。
句法主题模型
我们用一个具体的例子来说明这个想法。 考虑一本旅行手册,上面写着“在
在不久的将来,你会发现自己身处其中。” 单词的低级句法上下文及其文档上下文都限制了接下来出现的单词的可能性。 在句法上,它将是一个与介词“of”的宾语一致的名词。 从主题上讲,因为它在旅行手册中,我们希望看到诸如“阿卡普尔科”、“哥斯达黎加”或“澳大利亚”之类的词,而不是“厨房”、“债务”或“口袋”。 我们的模型可以捕捉到这些规律,并在预测问题中利用它们。
使用二部谱图分区对文档和单词进行共聚类。
在本文中,我们考虑了文档和单词的同时或协同聚类问题。 大多数现有工作是关于单向聚类,即文档或单词聚类。 现有算法的一个共同主题是根据文档的单词分布对文档进行聚类,而单词聚类是由文档中的共现决定的。 这表明文档和术语聚类之间存在二元性。
概率潜在语义索引
概率潜在语义分析是一种用于分析双模式和共现数据的新型统计技术,它在信息检索和过滤、自然语言处理、文本机器学习以及相关领域都有应用。
Twitter主题建模的实证研究
在 Twitter 中,社区认为重要的流行信息通过网络传播。 研究消息中的内容特征对于多项任务变得很重要,例如突发新闻检测、个性化消息推荐、朋友推荐、情感分析等。 虽然许多研究人员希望使用标准的文本挖掘工具来理解 Twitter 上的消息,但这些消息的长度限制使他们无法充分发挥其潜力。
用于自动索引的向量空间模型
在其他文档匹配环境的文档检索中,存储的实体(文档)相互比较或与传入的模式(搜索请求)进行比较,似乎最好的索引属性空间是每个实体与其他实体的距离为可能的; 在这些情况下,索引系统的值可以表示为对象空间密度的函数; 特别是,检索性能可能与空间密度成反比。 使用基于空间密度计算的方法为文档集合选择最佳索引词汇。 显示了典型的评估结果,证明了模型的有用性。 关键词和短语:自动信息检索、自动索引、内容分析、文档
信息的数学理论
通信的基本问题是在某一点精确地或近似地再现另一点选择的消息。 通常这些信息是有意义的; 也就是说,它们指代或根据某些系统与某些物理或概念实体相关联。 通信的这些语义方面与工程问题无关。 重要的方面是实际消息是从一组可能的消息中选出的。 系统必须设计为针对每种可能的选择进行操作,而不仅仅是将要选择的选择,因为这在设计时是未知的。
主题随时间变化:主题趋势的非马尔可夫连续时间模型
我们展示了 9 个月的个人电子邮件、17 年的 NIPS 研究论文和 200 多年的总统国情咨文的结果,展示了改进的主题、更好的时间戳预测和可解释的趋势。
Twitter-rank:寻找对话题敏感的有影响力的 Twitterers
本文重点研究微博服务有影响力用户的识别问题。 Twitter 是最著名的微博服务之一,它采用了一种称为“关注”的社交网络模式,其中每个用户都可以选择她想要“关注”的人来接收推文,而无需后者先给予许可
基于标题的社会新闻聚类的判别双项主题模型
社会新闻正变得越来越流行。 新闻机构和大众记者开始越来越多地使用社交媒体来广播新闻。 社交新闻聚类的主要挑战在于文本内容只是一个标题,比全文短得多
短文本的双项主题模型
发现短文本中的主题,例如推文和即时消息,已成为许多内容分析应用程序的重要任务。 然而,在这样的短文本上直接应用传统的主题模型(例如 LDA 和 PLSA)可能效果不佳。 其根本原因在于传统的主题模型隐含地捕获文档级单词共现模式来揭示主题,从而遭受短文档中严重的数据稀疏性。