
Modellazione semantica degli argomenti per le query di ricerca su Google
Pubblicato: 2016-12-29
Che cos'è la modellazione semantica degli argomenti?
Mi sono imbattuto in alcuni articoli interessanti nelle pagine di Google Research sulla modellazione di argomenti semantici che ho pensato valesse la pena condividere. Uno mi ha ricordato l'uso da parte di Google della co-occorrenza di frasi nelle pagine di alto livello per diverse query e come potrebbe essere utilizzato per comprendere meglio la modellazione tematica su un sito. Ne ho scritto in un post sul blog di Go Fish Digital, che ho chiamato, Modellazione tematica utilizzando parole correlate nei documenti e nel testo di ancoraggio
Il foglio che mi ha ricordato quel post era questo:
Miglioramento del clustering di argomenti semantici per le query di ricerca con co-occorrenza di parole e co-clustering di caratteri bigrafici. Il documento è di Jing Kong, Alex Scott e Georg M. Goerg
Tecniche per la modellazione semantica di argomenti
L'abstract dell'articolo ci dice: “Vi presentiamo due nuove tecniche che possono scoprire argomenti semanticamente significativi nelle query di ricerca: (i) il raggruppamento di co-occorrenze di parole genera argomenti da parole che ricorrono frequentemente insieme; (ii) il clustering bigraph ponderato utilizza gli URL dei risultati di ricerca di Google per indurre la somiglianza delle query e generare argomenti".
Il documento fornisce esempi da serie di pagine sui prodotti del marchio Lipton e domande relative a trucco e cosmetici.
Imparare dalle informazioni sulla query
Le informazioni sulla query possono fornire informazioni aziendali interessanti e utili. Sapere con quale frequenza le persone cercano prodotti e marchi particolari può dirci quante persone sono interessate a quei prodotti e cosa le persone potrebbero associare a quei marchi. Ad esempio, raggruppare i prodotti in categorie come "prodotti di bellezza" può darci informazioni su ciò che le persone cercano nelle tendenze popolari.
Una delle difficoltà che potresti incontrare nel cercare di imparare da argomenti che appaiono in questo modo è che si presentano in contesti abbreviati, come tweet e query, il che significa che non imparerai da altri termini che appaiono vicino a loro o con loro. Ad esempio, la parola "Lipton" potrebbe apparire frequentemente accanto a parole correlate a "tè" e "zuppa".
La co-occorrenza di parole si verifica quando gli stessi termini o frasi compaiono frequentemente (senza contare le parole di arresto) in documenti che potrebbero essere classificati in alto per un particolare termine di query, il che significa che tali parole sono probabilmente correlate semanticamente ai termini per cui si classificano in alto.
Un approccio di clustering biterm può comportare l'acquisizione di parole da molti documenti che si classificano per una determinata query e la loro messa insieme e l'estrazione di termini di due parole che appaiono in quei documenti (e il loro raggruppamento in base alla frequenza con cui vengono visualizzati).
Scopo delle tecniche di modellazione di argomenti semantici
Il documento descrive in dettaglio questi approcci di co-occorrenza di parole e di clustering bi-grafico ponderato e il modo in cui vengono utilizzati.
Ricorda, lo scopo di questo documento è descrivere come questi due diversi approcci possono aiutare a comprendere meglio gli argomenti che potrebbero essere in qualche modo correlati. Quando si parla di "Lipton", è nel contesto di "tè" o "zuppa?"
Una serie di query relative al marchio può mostrare argomenti che potrebbero essere correlati a tali query. Ci viene mostrata questa tabella per darci alcuni esempi:
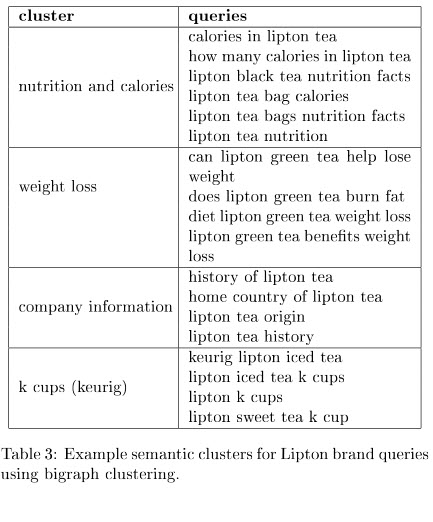
Nella sezione delle discussioni del documento sulla modellazione dell'argomento semantico, ci dicono quale approccio ha funzionato meglio in diverse circostanze. È stata una conclusione interessante e mi ha lasciato il desiderio di fare ulteriori ricerche.
Approfondimenti da citazioni su carta
Fortunatamente, le citazioni in questo articolo sembravano valere la pena di essere esplorate, quindi ho trovato i collegamenti alle pagine in cui appaiono la maggior parte di esse e alcuni estratti da quelle che ne danno un senso. Alcuni di questi sembrano essere in circolazione da un po', e alcuni sembrano discutere di argomenti a cui potresti aver visto fare riferimento in passato. Alcuni di questi si applicano specificamente ai social media che sono ben noti per avere scarse quantità di testo, come Twitter. Molti di questi sembravano abbastanza interessanti da voler trovare collegamenti a loro e leggere di più (e ho pensato che valesse la pena condividerli)
Clustering aggregato di un log di query del motore di ricerca (2000)
La strategia di clustering qui applicata deriva da due osservazioni correlate. In primo luogo, il fatto che gli utenti con la stessa esigenza informativa possano formulare la propria query in modo diverso da un motore di ricerca, ghepardi e gatti selvatici, ma selezionare lo stesso URL tra quelli offerti per soddisfare tale esigenza suggerisce che tali query sono correlate. In secondo luogo, il fatto che dopo aver emesso la stessa query, gli utenti possano visitare due URL diversi www.funds.com e www.mutualfunds.com, è evidente che gli URL sono simili.
Allocazione di Dirichlet latente
In questo articolo consideriamo il problema della modellazione di corpora di testo e altre raccolte di dati discreti. L'obiettivo è trovare brevi descrizioni dei membri di una raccolta che consentano un'elaborazione efficiente di grandi raccolte preservando le relazioni statistiche essenziali utili per attività di base come la classificazione, il rilevamento di novità, il riepilogo e i giudizi di somiglianza e pertinenza.
Modelli tematici sintattici
Illustriamo questa idea con un esempio concreto. Considera un opuscolo di viaggio con la frase "In
nel prossimo futuro, potresti ritrovarti in .” Sia il contesto sintattico di basso livello di una parola che il contesto del suo documento limitano le possibilità della parola che può apparire successivamente. Dal punto di vista sintattico, sarà un sostantivo coerente come oggetto della preposizione "di". Tematicamente, poiché è in una brochure di viaggio, ci aspetteremmo di vedere parole come "Acapulco", "Costa Rica" o "Australia" più di "cucina", "debito" o "tasca". Il nostro modello può catturare questo tipo di regolarità e sfruttarle nei problemi predittivi.

Co-clustering di documenti e parole utilizzando il partizionamento di grafi spettrali bipartiti.
In questo articolo, consideriamo il problema del simultaneo o co-clustering di documenti e parole. La maggior parte del lavoro esistente riguarda il clustering unidirezionale, ovvero il clustering di documenti o di parole. Un tema comune tra gli algoritmi esistenti è quello di raggruppare i documenti in base alle loro distribuzioni di parole, mentre il raggruppamento di parole è determinato dalla co-occorrenza nei documenti. Ciò indica una dualità tra il raggruppamento di documenti e di termini.
Indicizzazione semantica latente probabilistica
L'analisi semantica latente probabilistica è una nuova tecnica statistica per l'analisi di dati bimodali e di co-occorrenza, che ha applicazioni nel recupero e nel filtraggio delle informazioni, nell'elaborazione del linguaggio naturale, nell'apprendimento automatico dal testo e in aree correlate.
Studio empirico del topic modeling in Twitter
In Twitter, le informazioni popolari ritenute importanti dalla comunità si propagano attraverso la rete. Lo studio delle caratteristiche del contenuto nei messaggi diventa importante per diverse attività, come il rilevamento delle ultime notizie, la raccomandazione di messaggi personalizzati, la raccomandazione degli amici, l'analisi del sentimento e altre. Sebbene molti ricercatori desiderino utilizzare strumenti di estrazione di testo standard per comprendere i messaggi su Twitter, la lunghezza limitata di tali messaggi impedisce loro di essere utilizzati al massimo delle loro potenzialità.
Un modello di spazio vettoriale per l'indicizzazione automatica
In un Document Retrieval di un altro ambiente di corrispondenza dei documenti in cui le entità memorizzate (documenti) vengono confrontate tra loro o con modelli in entrata (richieste di ricerca), sembra che lo spazio delle proprietà di indicizzazione migliore sia quello in cui ogni entità si trova il più lontano possibile dalle altre possibile; in queste circostanze, il valore di un sistema di indicizzazione può essere esprimibile in funzione della densità dello spazio degli oggetti; in particolare, le prestazioni di recupero possono essere correlate inversamente alla densità dello spazio. Un approccio basato sui calcoli della densità spaziale viene utilizzato per scegliere un vocabolario di indicizzazione ottimale per una raccolta di documenti. Vengono mostrati i risultati tipici della valutazione, a dimostrazione dell'utilità del modello. Parole chiave e frasi: recupero automatico delle informazioni, indicizzazione automatica, analisi dei contenuti, documenti
La teoria matematica dell'informazione
Il problema fondamentale della comunicazione è quello di riprodurre in un punto esattamente o approssimativamente un messaggio selezionato in un altro punto. Spesso i messaggi hanno un significato; cioè si riferiscono o sono correlati secondo un sistema con determinate entità fisiche o concettuali. Questi aspetti semantici della comunicazione sono irrilevanti per il problema ingegneristico. L'aspetto significativo è che il messaggio effettivo è selezionato da un insieme di possibili messaggi. Il sistema deve essere progettato per funzionare per ogni possibile selezione, non solo per quella che verrà scelta poiché questa non è nota al momento della progettazione.
Temi nel tempo: un modello a tempo continuo non-Markov delle tendenze attuali
Presentiamo i risultati su nove mesi di e-mail personali, 17 anni di documenti di ricerca NIPS e oltre 200 anni di indirizzi presidenziali sullo stato dell'Unione, mostrando argomenti migliorati, previsioni di timestamp migliori e tendenze interpretabili.
Classifica Twitter: trovare Twitterer influenti e sensibili all'argomento
Questo articolo si concentra sul problema dell'identificazione degli utenti influenti dei servizi di micro-blogging. Twitter, uno dei più importanti servizi di micro-blogging, utilizza un modello di social network chiamato "follow", in cui ogni utente può scegliere da chi vuole "seguire" per ricevere i tweet senza che quest'ultimo debba prima dare il permesso
Modello di argomento discriminatorio a due termini per il raggruppamento di notizie sociali basato sui titoli
Le notizie sociali stanno diventando sempre più popolari. Organizzazioni giornalistiche e giornalisti popolari stanno iniziando a utilizzare sempre più i social media per trasmettere notizie. La sfida principale nel raggruppamento di notizie sociali risiede nel fatto che il contenuto testuale è solo un titolo, che è molto più breve del testo completo
Un modello di argomento Biterm per testi brevi
Scoprire gli argomenti all'interno di testi brevi, come tweet e messaggi istantanei, è diventato un compito importante per molte applicazioni di analisi dei contenuti. Tuttavia, l'applicazione diretta di modelli tematici convenzionali (ad es. LDA e PLSA) su testi così brevi potrebbe non funzionare bene. La ragione fondamentale risiede nel fatto che i modelli tematici convenzionali catturano implicitamente i modelli di co-occorrenza delle parole a livello di documento per rivelare argomenti, e quindi soffrono della grave scarsità di dati nei documenti brevi.