
Semantische Themenmodellierung für Suchanfragen bei Google
Veröffentlicht: 2016-12-29
Was ist Semantic Topic Modeling?
Ich bin auf den Google Research-Seiten auf einige interessante Artikel zur semantischen Topic-Modellierung gestoßen, von denen ich dachte, dass sie es wert sind, geteilt zu werden. Einer erinnerte mich an Googles Verwendung des gemeinsamen Vorkommens von Phrasen auf Seiten mit Top-Ranking für verschiedene Suchanfragen und wie dies verwendet werden könnte, um die thematische Modellierung auf einer Site besser zu verstehen. Darüber habe ich in einem Beitrag im Blog von Go Fish Digital geschrieben, den ich „Thematic Modeling Using Related Words in Documents and Anchor Text“ nannte
Das Papier, das mich an diesen Beitrag erinnerte, war dieses:
Verbessern des semantischen Topic Clustering für Suchanfragen mit Word Co-Occurrence und Bigraph Co-Clustering. Das Papier stammt von Jing Kong, Alex Scott und Georg M. Goerg
Techniken zur semantischen Themenmodellierung
In der Zusammenfassung des Artikels heißt es: „Wir stellen zwei neuartige Techniken vor, die semantisch bedeutsame Themen in Suchanfragen entdecken können: (i) Wort-Gruppierung generiert Themen aus häufig zusammen vorkommenden Wörtern; (ii) Beim gewichteten bigraphen Clustering werden URLs aus den Google-Suchergebnissen verwendet, um eine Ähnlichkeit der Abfragen zu erzeugen und Themen zu generieren.“
Der Artikel enthält Beispiele aus mehreren Seiten zu Produkten der Marke Lipton und Fragen zu Make-up und Kosmetik.
Aus Abfrageinformationen lernen
Abfrageinformationen können interessante und hilfreiche Geschäftseinblicke liefern. Wenn wir wissen, wie oft Leute nach bestimmten Produkten und Marken suchen, können wir sagen, wie viele Leute sich für diese Produkte interessieren und was die Leute mit diesen Marken in Verbindung bringen. Beispielsweise kann uns die Gruppierung von Produkten in Kategorien wie „Beauty-Produkte“ Einblicke in die Suchanfragen beliebter Trends geben.
Eine der Schwierigkeiten, auf die Sie stoßen können, wenn Sie versuchen, aus so erscheinenden Themen zu lernen, besteht darin, dass sie in verkürzten Kontexten wie Tweets und Abfragen angezeigt werden, was bedeutet, dass Sie nicht aus anderen Begriffen lernen, die in ihrer Nähe erscheinen oder mit ihnen. Zum Beispiel kann das Wort „Lipton“ häufig in der Nähe von Wörtern auftauchen, die mit „Tee“ und „Suppe“ verwandt sind.
Das gemeinsame Vorkommen von Wörtern liegt vor, wenn dieselben Begriffe oder Phrasen häufig (Stoppwörter nicht mitgezählt) in Dokumenten vorkommen, die für einen bestimmten Suchbegriff einen hohen Rang haben, was bedeutet, dass diese Wörter wahrscheinlich semantisch mit den Begriffen verwandt sind, für die sie einen hohen Rang haben.
Ein biterm-Clustering- Ansatz kann darin bestehen, Wörter aus vielen Dokumenten zu nehmen, die für eine bestimmte Abfrage ranken , und sie alle zusammenzufassen und Zwei-Wort-Begriffe herauszuziehen, die in diesen Dokumenten vorkommen (und sie nach ihrer Häufigkeit zu gruppieren).
Zweck semantischer Themenmodellierungstechniken
Der Artikel beschreibt diese Wort-Ko-Auftreten und gewichteten Bi-Graph-Clustering-Ansätze und wie sie verwendet werden.
Denken Sie daran, dass der Zweck dieses Dokuments darin besteht, zu beschreiben, wie diese beiden unterschiedlichen Ansätze dazu beitragen können, Themen, die in gewisser Weise miteinander verbunden sind, besser zu verstehen. Wenn von „Lipton“ die Rede ist, steht das im Zusammenhang mit „Tee“ oder „Suppe“?
Eine Reihe von markenbezogenen Abfragen kann Themen aufzeigen, die mit diesen Abfragen zusammenhängen könnten. Diese Tabelle zeigt uns einige Beispiele:
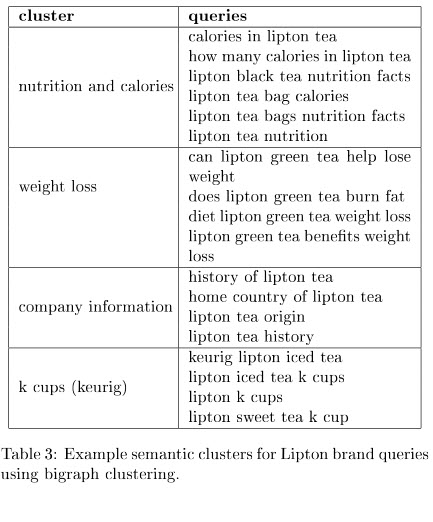
Im Diskussionsabschnitt des Papiers zur semantischen Themenmodellierung sagen sie uns, welcher Ansatz unter verschiedenen Umständen am besten funktioniert hat. Es war eine interessante Schlussfolgerung und machte Lust auf mehr Forschung.
Erkenntnisse aus Paper Citations
Glücklicherweise sahen die Zitate in diesem Papier so aus, als ob sie es wert wären, untersucht zu werden, daher habe ich Links zu den Seiten gefunden, auf denen die meisten von ihnen erscheinen, und einige Auszüge aus denen, die einen Eindruck davon vermitteln. Einige von ihnen scheinen schon eine Weile auf dem Markt zu sein, und einige scheinen Themen zu diskutieren, auf die Sie in der Vergangenheit möglicherweise Bezug genommen haben. Einige von ihnen gelten speziell für soziale Medien, die für ihre geringen Textmengen bekannt sind, wie z. B. Twitter. Viele davon schienen interessant genug, dass ich Links zu ihnen finden und mehr lesen wollte (und dachte, sie seien es wert, sie geteilt zu haben).
Agglomeratives Clustering eines Suchmaschinen-Abfrageprotokolls (2000)
Die hier angewandte Clustering-Strategie folgt aus zwei verwandten Beobachtungen. Erstens, die Tatsache, dass Benutzer mit demselben Informationsbedürfnis ihre Anfrage möglicherweise anders formulieren als eine Suchmaschine, Geparden und Wildkatzen, aber dieselbe URL aus den angebotenen URLs auswählen, um dieses Bedürfnis zu erfüllen, deutet darauf hin, dass diese Anfragen miteinander verwandt sind. Zweitens ist die Tatsache, dass Benutzer nach der gleichen Abfrage zwei verschiedene URLs www.funds.com und www.mutualfunds.com besuchen können, offensichtlich, dass die URLs ähnlich sind.
Latente Dirichlet-Zuweisung
In diesem Papier betrachten wir das Problem der Modellierung von Textkorpora und anderen Sammlungen diskreter Daten. Ziel ist es, kurze Beschreibungen der Mitglieder einer Sammlung zu finden, die eine effiziente Verarbeitung großer Sammlungen ermöglichen und gleichzeitig die wesentlichen statistischen Beziehungen erhalten, die für grundlegende Aufgaben wie Klassifikation, Neuheitserkennung, Zusammenfassung sowie Ähnlichkeits- und Relevanzbeurteilungen nützlich sind.

Syntaktische Themenmodelle
Wir illustrieren diese Idee an einem konkreten Beispiel. Betrachten Sie eine Reisebroschüre mit dem Satz „In
in naher Zukunft könnten Sie sich in ” wiederfinden.“ Sowohl der syntaktische Kontext auf niedriger Ebene eines Wortes als auch sein Dokumentkontext schränken die Möglichkeiten des Wortes ein, das als nächstes erscheinen kann. Syntaktisch wird es ein Nomen sein, das als Objekt der Präposition „von“ konsistent ist. Thematisch würden wir, weil es in einem Reiseprospekt steht, erwarten, Wörter wie „Acapulco“, „Costa Rica“ oder „Australien“ mehr zu sehen als „Küche“, „Schulden“ oder „Tasche“. Unser Modell kann solche Regelmäßigkeiten erfassen und in Vorhersageproblemen ausnutzen.
Co-Clustering von Dokumenten und Wörtern mit bipartite Spectral Graph Partitioning.
In diesem Beitrag betrachten wir das Problem der gleichzeitigen oder gemeinsamen Anhäufung von Dokumenten und Wörtern. Die meisten der bestehenden Arbeiten beziehen sich auf Einweg-Clustering, dh entweder auf Dokumenten- oder Wort-Clustering. Ein gemeinsames Thema unter existierenden Algorithmen besteht darin, Dokumente basierend auf ihren Wortverteilungen zu gruppieren, während die Wortgruppierung durch das gemeinsame Vorkommen in Dokumenten bestimmt wird. Dies weist auf eine Dualität zwischen Dokumenten- und Begriffs-Clustering hin.
Probabilistische latente semantische Indizierung
Die probabilistische latente semantische Analyse ist eine neuartige statistische Technik für die Analyse von Zweimodus- und Kookkurrenzdaten, die Anwendungen in der Informationsabfrage und -filterung, der Verarbeitung natürlicher Sprache, dem maschinellen Lernen aus Text und in verwandten Bereichen findet.
Empirische Studie zur Themenmodellierung in Twitter
Bei Twitter verbreiten sich populäre Informationen, die von der Community als wichtig erachtet werden, über das Netzwerk. Das Studium der Inhaltsmerkmale in den Nachrichten ist für verschiedene Aufgaben wichtig, z. B. für die Erkennung von Eilmeldungen, personalisierte Nachrichtenempfehlungen, Empfehlungen von Freunden, Stimmungsanalysen und andere. Während viele Forscher Standard-Text-Mining-Tools verwenden möchten, um Nachrichten auf Twitter zu verstehen, verhindert die begrenzte Länge dieser Nachrichten, dass sie ihr volles Potenzial nutzen können.
Ein Vektorraummodell für die automatische Indizierung
In einer Dokumentenabrufumgebung einer anderen Dokumentenabgleichsumgebung, in der gespeicherte Entitäten (Dokumente) miteinander oder mit eingehenden Mustern (Suchanfragen) verglichen werden, scheint es, dass der beste Indizierungseigenschaftsraum derjenige ist, in dem jede Entität so weit wie möglich von den anderen entfernt liegt möglich; unter diesen Umständen kann der Wert eines Indexierungssystems als Funktion der Dichte des Objektraums ausgedrückt werden; insbesondere kann die Abrufleistung umgekehrt mit der Raumdichte korrelieren. Ein auf Raumdichteberechnungen basierender Ansatz wird verwendet, um ein optimales Indexierungsvokabular für eine Sammlung von Dokumenten auszuwählen. Es werden typische Bewertungsergebnisse gezeigt, die die Nützlichkeit des Modells demonstrieren. Schlüsselwörter und Phrasen: automatische Informationsbeschaffung, automatische Indexierung, Inhaltsanalyse, Dokumente
Die mathematische Theorie der Information
Das grundlegende Problem der Kommunikation besteht darin, an einem Punkt eine an einem anderen Punkt ausgewählte Nachricht entweder genau oder ungefähr wiederzugeben. Häufig haben die Botschaften Bedeutung; das heißt, sie beziehen sich auf bestimmte physikalische oder begriffliche Entitäten oder sind gemäß einem System mit diesen korreliert. Diese semantischen Aspekte der Kommunikation sind für das Engineering-Problem irrelevant. Der wesentliche Aspekt besteht darin, dass die eigentliche Nachricht aus einer Menge möglicher Nachrichten ausgewählt wird. Das System muss so ausgelegt sein, dass es für jede mögliche Auswahl funktioniert, nicht nur für die, die ausgewählt wird, da dies zum Zeitpunkt der Auslegung nicht bekannt ist.
Themen im Zeitverlauf: ein zeitkontinuierliches Nicht-Markov-Modell aktueller Trends
Wir präsentieren Ergebnisse aus neun Monaten persönlicher E-Mails, 17 Jahren NIPS-Forschungsarbeiten und über 200 Jahren Präsidentschaftsreden zur Lage der Union, die verbesserte Themen, bessere Zeitstempelvorhersagen und interpretierbare Trends aufzeigen.
Twitter-Rang: Themensensible einflussreiche Twitterer finden
Dieser Beitrag konzentriert sich auf das Problem der Identifizierung einflussreicher Nutzer von Microblogging-Diensten. Twitter, einer der bekanntesten Mikroblogging-Dienste, verwendet ein Social-Networking-Modell namens „Folgen“, bei dem jeder Benutzer wählen kann, wem er „folgen“ möchte, um Tweets zu erhalten, ohne dass dieser zuerst seine Zustimmung geben muss
Diskriminatives Zwei-Term-Themenmodell für schlagzeilenbasiertes Clustering von sozialen Nachrichten
Soziale Nachrichten werden immer beliebter. Nachrichtenorganisationen und populäre Journalisten nutzen soziale Medien immer stärker für die Verbreitung von Nachrichten. Die große Herausforderung beim Clustering von Social News besteht darin, dass Textinhalte nur eine Überschrift sind, die viel kürzer ist als der Volltext
Ein biterm-Themenmodell für kurze Texte
Das Aufdecken der Themen in kurzen Texten wie Tweets und Instant Messages ist für viele Anwendungen der Inhaltsanalyse zu einer wichtigen Aufgabe geworden. Die direkte Anwendung konventioneller Themenmodelle (zB LDA und PLSA) auf solche kurzen Texte kann jedoch nicht gut funktionieren. Der grundlegende Grund liegt darin, dass herkömmliche Themenmodelle implizit die Muster des gemeinsamen Vorkommens von Wörtern auf Dokumentebene erfassen, um Themen aufzudecken, und somit unter der starken Datenknappheit in kurzen Dokumenten leiden.