
Modelado de temas semánticos para consultas de búsqueda en Google
Publicado: 2016-12-29
¿Qué es el modelado de temas semánticos?
Encontré algunos artículos interesantes en las páginas de investigación de Google sobre modelado de temas semánticos que pensé que valía la pena compartir. Uno me recordó el uso de Google de la co-ocurrencia de frases en las páginas de alto rango para diferentes consultas y cómo eso podría usarse para comprender mejor el modelado temático en un sitio. Escribí sobre eso en una publicación en el blog Go Fish Digital, al que llamé Modelado temático con palabras relacionadas en documentos y texto de anclaje.
El papel que me recordó esa publicación fue este:
Mejora de la agrupación semántica de temas para consultas de búsqueda con co-ocurrencia de palabras y agrupación conjunta de bigraph. El artículo es de Jing Kong, Alex Scott y Georg M. Goerg.
Técnicas para el modelado de temas semánticos
El resumen del artículo nos dice: “Presentamos dos técnicas novedosas que pueden descubrir temas semánticamente significativos en consultas de búsqueda: (i) el agrupamiento de co-ocurrencia de palabras genera temas a partir de palabras que ocurren juntas con frecuencia; (ii) la agrupación en clústeres de bigrafines ponderados utiliza las URL de los resultados de búsqueda de Google para inducir la similitud de consultas y generar temas ".
El documento proporciona ejemplos de conjuntos de páginas sobre productos de la marca Lipton y consultas relacionadas con maquillaje y cosméticos.
Aprendiendo de la información de la consulta
La información de consulta puede proporcionar información empresarial interesante y útil. Saber con qué frecuencia las personas buscan productos y marcas en particular nos puede decir cuántas personas están interesadas en esos productos, así como qué personas podrían asociar con esas marcas. Por ejemplo, agrupar productos en categorías como "productos de belleza" puede brindarnos información sobre lo que las personas buscan en las tendencias populares.
Una de las dificultades con las que podría encontrarse al tratar de aprender de temas que aparecen así es que aparecen en contextos abreviados, como tweets y consultas, lo que significa que no aprenderá de otros términos que aparezcan cerca de ellos o con ellos. Por ejemplo, la palabra "Lipton" puede aparecer con frecuencia cerca de palabras relacionadas con "té" y "sopa".
La co-ocurrencia de palabras ocurre cuando los mismos términos o frases aparecen con frecuencia (sin contar las palabras vacías) en documentos que pueden tener una clasificación alta para un término de consulta en particular, lo que significa que esas palabras probablemente estén relacionadas semánticamente con los términos para los que tienen una clasificación alta.
Un enfoque de agrupamiento biterm puede implicar tomar palabras de muchos documentos que se clasifican para una determinada consulta, juntarlos todos y extraer términos de dos palabras que aparecen en esos documentos (y agruparlos por la frecuencia con la que aparecen).
Propósito de las técnicas de modelado de temas semánticos
El documento detalla estos enfoques de agrupación de agrupaciones de bi-gráficos ponderados y de co-ocurrencia de palabras y cómo se utilizan.
Recuerde, el objetivo de este documento es describir cómo estos dos enfoques diferentes pueden ayudar a comprender mejor los temas que podrían estar relacionados de alguna manera. Cuando se habla de "Lipton", ¿es en el contexto de "té" o "sopa"?
Una variedad de consultas relacionadas con la marca pueden mostrar temas que podrían estar relacionados con esas consultas. Se nos muestra esta tabla para darnos algunos ejemplos:
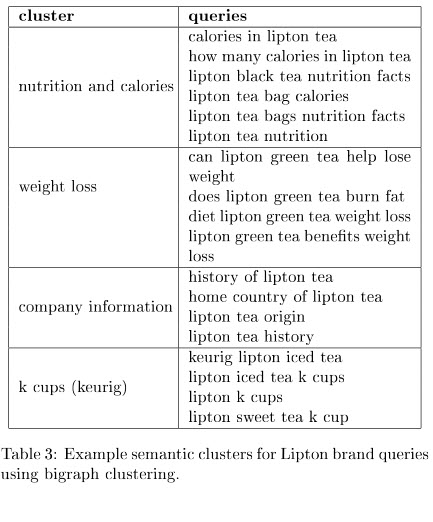
En la sección de discusiones del documento de modelado de temas semánticos, nos dicen qué enfoque funcionó mejor en diferentes circunstancias. Fue una conclusión interesante y me dejó con ganas de investigar más.
Perspectivas de las citas en papel
Afortunadamente, parecía que valdría la pena explorar las citas en este artículo, así que encontré enlaces a las páginas en las que aparecen la mayoría de ellas y algunos extractos de las que dan una idea de ellas. Algunos de estos parecen haber existido por un tiempo, y algunos parecen discutir temas a los que puede haber visto aludidos en el pasado. Algunos de ellos se aplican específicamente a las redes sociales que son bien conocidas por tener escasa cantidad de texto, como Twitter. Muchos de ellos parecían lo suficientemente interesantes como para que quisiera encontrar enlaces a ellos y leer más (y pensé que valía la pena compartirlos).
Aglomeración agrupada de un registro de consultas del motor de búsqueda (2000)
La estrategia de agrupación aplicada aquí se deriva de dos observaciones relacionadas. Primero, el hecho de que los usuarios con la misma necesidad de información puedan formular su consulta de manera diferente a un motor de búsqueda, guepardos y gatos salvajes, pero seleccionar la misma URL entre las que se ofrecen para satisfacer esa necesidad sugiere que esas consultas están relacionadas. En segundo lugar, el hecho de que después de realizar la misma consulta, los usuarios pueden visitar dos URL diferentes www.funds.com y www.mutualfunds.com, es evidente que las URL son similares.
Asignación de Dirichlet latente
En este artículo consideramos el problema de modelar corpus de texto y otras colecciones de datos discretos. El objetivo es encontrar descripciones breves de los miembros de una colección que permitan el procesamiento eficiente de colecciones grandes al tiempo que preservan las relaciones estadísticas esenciales que son útiles para tareas básicas como clasificación, detección de novedades, resumen y juicios de similitud y relevancia.
Modelos de temas sintácticos
Ilustramos esta idea con un ejemplo concreto. Considere un folleto de viajes con la frase "En
en el futuro cercano, podrías encontrarte ". Tanto el contexto sintáctico de bajo nivel de una palabra como el contexto del documento limitan las posibilidades de la palabra que puede aparecer a continuación. Sintácticamente, será un sustantivo consistente como objeto de la preposición "de". Temáticamente, debido a que está en un folleto de viaje, esperaríamos ver palabras como "Acapulco", "Costa Rica" o "Australia" más que "cocina", "deuda" o "bolsillo". Nuestro modelo puede capturar este tipo de regularidades y explotarlas en problemas predictivos.

Agrupación conjunta de documentos y palabras mediante particiones de gráficos espectrales bipartitos.
En este artículo, consideramos el problema de la agrupación simultánea o conjunta de documentos y palabras. La mayor parte del trabajo existente se centra en la agrupación unidireccional, es decir, agrupación de documentos o palabras. Un tema común entre los algoritmos existentes es agrupar documentos en función de sus distribuciones de palabras, mientras que la agrupación de palabras está determinada por la co-ocurrencia en los documentos. Esto apunta a una dualidad entre la agrupación de documentos y términos.
Indexación semántica latente probabilística
El análisis semántico latente probabilístico es una técnica estadística novedosa para el análisis de datos de dos modos y co-ocurrencia, que tiene aplicaciones en la recuperación y filtrado de información, procesamiento de lenguaje natural, aprendizaje automático a partir de texto y en áreas relacionadas.
Estudio empírico del modelado de temas en Twitter
En Twitter, la información popular que la comunidad considera importante se propaga a través de la red. Estudiar las características del contenido de los mensajes se vuelve importante para varias tareas, como la detección de noticias de última hora, la recomendación de mensajes personalizados, la recomendación de amigos, el análisis de sentimientos y otras. Si bien muchos investigadores desean utilizar herramientas de minería de texto estándar para comprender los mensajes en Twitter, la longitud restringida de esos mensajes impide que se utilicen en todo su potencial.
Un modelo de espacio vectorial para indexación automática
En una recuperación de documentos de otro entorno de coincidencia de documentos donde las entidades almacenadas (documentos) se comparan entre sí o con patrones entrantes (solicitudes de búsqueda), parece que el mejor espacio de propiedad de indexación es aquel en el que cada entidad se encuentra tan lejos de las demás como posible; en estas circunstancias, el valor de un sistema de indexación puede expresarse en función de la densidad del espacio de objetos; en particular, el rendimiento de la recuperación puede tener una correlación inversa con la densidad del espacio. Se utiliza un enfoque basado en cálculos de densidad espacial para elegir un vocabulario de indexación óptimo para una colección de documentos. Se muestran los resultados típicos de la evaluación, que demuestran la utilidad del modelo. Palabras y frases clave: recuperación automática de información, indexación automática, análisis de contenido, documentos
La teoría matemática de la información
El problema fundamental de la comunicación es el de reproducir en un punto de forma exacta o aproximada un mensaje seleccionado en otro punto. Con frecuencia los mensajes tienen significado; es decir, se refieren o se correlacionan según algún sistema con determinadas entidades físicas o conceptuales. Estos aspectos semánticos de la comunicación son irrelevantes para el problema de la ingeniería. El aspecto significativo es que el mensaje real se selecciona de un conjunto de mensajes posibles. El sistema debe estar diseñado para operar para cada posible selección, no solo la que se elegirá, ya que esta se desconoce en el momento del diseño.
Temas a lo largo del tiempo: un modelo de tiempo continuo que no es de Markov de tendencias tópicas
Presentamos los resultados de nueve meses de correo electrónico personal, 17 años de trabajos de investigación de NIPS y más de 200 años de direcciones presidenciales sobre el estado de la unión, que muestran temas mejorados, una mejor predicción de la marca de tiempo y tendencias interpretables.
Clasificación en Twitter: encontrar tuiteros influyentes y sensibles al tema
Este artículo se centra en el problema de identificar a los usuarios influyentes de los servicios de microblogs. Twitter, uno de los servicios de microblogging más destacados, emplea un modelo de redes sociales llamado "siguiente", en el que cada usuario puede elegir a quién quiere "seguir" para recibir tweets sin necesidad de que este último dé permiso primero.
Modelo de tema discriminativo de dos términos para la agrupación de noticias sociales basadas en titulares
Las noticias sociales son cada vez más populares. Las organizaciones de noticias y los periodistas populares están comenzando a usar las redes sociales cada vez más para transmitir noticias. El mayor desafío en la agrupación de noticias sociales radica en el hecho de que el contenido textual es solo un titular, que es mucho más corto que el texto completo.
Un modelo de tema Biterm para textos breves
Descubrir los temas en textos breves, como tweets y mensajes instantáneos, se ha convertido en una tarea importante para muchas aplicaciones de análisis de contenido. Sin embargo, la aplicación directa de modelos de temas convencionales (por ejemplo, LDA y PLSA) en textos tan breves puede no funcionar bien. La razón fundamental radica en que los modelos de temas convencionales capturan implícitamente los patrones de co-ocurrencia de palabras a nivel de documento para revelar temas y, por lo tanto, adolecen de la escasez de datos en documentos cortos.