
Googleでの検索クエリのセマンティックトピックモデリング
公開: 2016-12-29
セマンティックトピックモデリングとは何ですか?
共有する価値があると思ったセマンティックトピックモデリングに関するGoogleResearchページでいくつかの興味深い論文に出くわしました。 ある人は、Googleがさまざまなクエリの上位ページでフレーズの共起を使用していることと、それを使用してサイトの主題モデリングをよりよく理解する方法を思い出しました。 これについては、Go Fish Digitalブログの投稿で、ドキュメントとアンカーテキストで関連する単語を使用したテーマ別モデリングと呼んでいます。
その投稿を思い出させた論文はこれでした:
単語の共起とバイグラフの共起による検索クエリのセマンティックトピッククラスタリングの改善。 論文は、Jing Kong、Alex Scott、Georg M.Goergによるものです。
セマンティックトピックモデリングの手法
この論文の要約は、次のように述べています。「検索クエリで意味的に意味のあるトピックを発見できる2つの新しい手法を紹介します。(i)単語の共起クラスタリングは、頻繁に一緒に出現する単語からトピックを生成します。 (ii)加重バイグラフクラスタリングは、Google検索結果のURLを使用して、クエリの類似性を誘導し、トピックを生成します。」
このペーパーは、リプトンブランドの製品に関する一連のページの例と、化粧品や化粧品に関する質問を提供します。
クエリ情報から学ぶ
クエリ情報は、興味深く有用なビジネス洞察を提供できます。 人々が特定の製品やブランドを検索する頻度を知ることで、それらの製品に興味を持っている人の数と、それらのブランドに関連する可能性のあるものを知ることができます。 たとえば、製品を「美容製品」などのカテゴリにクラスタリングすると、人気のあるトレンドで人々が何を探しているかについての洞察を得ることができます。
このように表示されるトピックから学習しようとするときに遭遇する可能性のある問題の1つは、ツイートやクエリなどの短縮されたコンテキストで表示されることです。つまり、近くに表示される他の用語から学習することはできません。彼らと一緒に。 たとえば、「リプトン」という単語は、「お茶」や「スープ」に関連する単語の近くに頻繁に表示される場合があります。
単語の共起とは、特定のクエリ用語で上位にランク付けされる可能性のあるドキュメントに同じ用語またはフレーズが頻繁に出現する場合です(ストップワードはカウントされません)。つまり、これらの単語は、上位にランク付けされる用語と意味的に関連している可能性があります。
二項クラスタリングアプローチでは、特定のクエリにランク付けされた多数のドキュメントから単語を取得し、それらをすべてまとめて、それらのドキュメントに表示される2語の用語を抽出します(そして、それらが表示される頻度でクラスタリングします)。
セマンティックトピックモデリング手法の目的
このホワイトペーパーでは、これらの単語の共起と加重バイグラフクラスタリングのアプローチ、およびそれらの使用方法について詳しく説明しています。
このホワイトペーパーのポイントは、これら2つの異なるアプローチが、いくらか関連している可能性のあるトピックが表示されていることをよりよく理解するのにどのように役立つかを説明することです。 「リプトン」が語られているとき、それは「お茶」または「スープ」の文脈でですか?
ブランド関連のさまざまなクエリで、それらのクエリに関連する可能性のあるトピックをアピールできます。 いくつかの例を示すために、この表を示します。
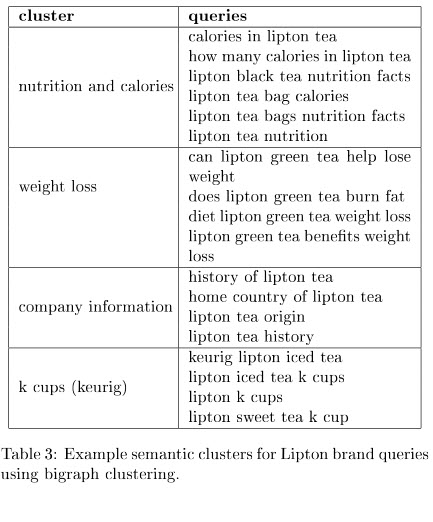
セマンティックトピックモデリングペーパーのディスカッションセクションでは、さまざまな状況でどのアプローチが最も効果的かを示しています。 それは興味深い結論であり、私はもっと研究をしたいと思っていました。
論文引用からの洞察
幸いなことに、この論文の引用は調査する価値があるように見えたので、それらのほとんどが表示されているページへのリンクと、それらの意味を示すものからの抜粋を見つけました。 これらのいくつかはしばらくの間存在していたように見えます、そしていくつかはあなたが過去に言及されたのを見たかもしれないトピックを議論しているように見えます。 それらのいくつかは、Twitterなどのテキストの量が少ないことでよく知られているソーシャルメディアに特に適用されます。 それらの多くは、私がそれらへのリンクを見つけて、もっと読みたいと思ったほど興味深いようでした(そしてそれらは共有する価値があると思いました)
検索エンジンクエリログの凝集的クラスタリング(2000)
ここで適用されるクラスタリング戦略は、2つの関連する観察から得られます。 まず、同じ情報ニーズを持つユーザーは、検索エンジン、チーター、野生の猫とは異なる言い回しをする可能性がありますが、そのニーズを満たすために提供されたものの中から同じURLを選択するという事実は、それらのクエリが関連していることを示唆しています。 次に、同じクエリを発行した後、ユーザーが2つの異なるURL www.funds.comとwww.mutualfunds.comにアクセスする可能性があるという事実は、URLが類似していることを示しています。
潜在的ディリクレの割り当て
この論文では、テキストコーパスやその他の離散データのコレクションをモデル化する問題について考察します。 目標は、分類、新規性の検出、要約、類似性と関連性の判断などの基本的なタスクに役立つ基本的な統計的関係を維持しながら、大規模なコレクションの効率的な処理を可能にするコレクションのメンバーの簡単な説明を見つけることです。

構文トピックモデル
このアイデアを具体的な例で説明します。 「In
近い将来、あなたは自分自身を見つけることができるでしょう。」 単語の低レベルの構文コンテキストとそのドキュメントコンテキストの両方が、次に表示される可能性のある単語の可能性を制約します。 構文的には、前置詞「of」の目的語として一貫した名詞になります。 テーマ的には、旅行パンフレットにあるので、「キッチン」、「借金」、「ポケット」よりも「アカプルコ」、「コスタリカ」、「オーストラリア」などの単語が表示されると予想されます。 私たちのモデルは、これらの種類の規則性をキャプチャし、予測問題でそれらを利用することができます。
2部スペクトルグラフ分割を使用したドキュメントと単語の共同クラスタリング。
この論文では、文書と単語の同時または同時クラスタリングの問題について考察します。 既存の作業のほとんどは、一方向のクラスタリング、つまりドキュメントまたは単語のクラスタリングに関するものです。 既存のアルゴリズムに共通するテーマは、単語の分布に基づいてドキュメントをクラスタリングすることですが、単語のクラスタリングはドキュメント内の共起によって決定されます。 これは、ドキュメントと用語のクラスタリングの二重性を示しています。
確率的潜在意味索引付け
確率的潜在意味解析は、2つのモードと共起データを分析するための新しい統計手法であり、情報検索とフィルタリング、自然言語処理、テキストからの機械学習、および関連分野に適用されます。
Twitterでのトピックモデリングの実証的研究
Twitterでは、コミュニティが重要と見なす人気のある情報がネットワークを介して伝播します。 メッセージのコンテンツの特性を調査することは、ニュース速報の検出、パーソナライズされたメッセージの推奨、友人の推奨、感情分析など、いくつかのタスクで重要になります。 多くの研究者は、Twitterのメッセージを理解するために標準のテキストマイニングツールを使用したいと考えていますが、メッセージの長さが制限されているため、メッセージを最大限に活用することはできません。
自動索引付けのためのベクトル空間モデル
保存されたエンティティ(ドキュメント)が相互に比較される、または着信パターン(検索要求)と比較される他のドキュメントマッチング環境のドキュメント検索では、最適なインデックスプロパティスペースは、各エンティティが他のエンティティから遠く離れているスペースであるように見えます。可能; このような状況では、インデックスシステムの値は、オブジェクト空間の密度の関数として表現できる場合があります。 特に、検索パフォーマンスはスペース密度と逆相関する場合があります。 スペース密度の計算に基づくアプローチを使用して、ドキュメントのコレクションに最適なインデックス語彙を選択します。 典型的な評価結果が示され、モデルの有用性が示されています。 キーワードとフレーズ:自動情報検索、自動索引付け、内容分析、文書
情報の数学的理論
通信の基本的な問題は、ある時点で、別の時点で選択されたメッセージを正確にまたはほぼ複製することです。 多くの場合、メッセージには意味があります。 つまり、それらは、特定の物理的または概念的なエンティティを参照するか、システムに従って相互に関連付けられます。 コミュニケーションのこれらの意味論的側面は、工学的問題とは無関係です。 重要な側面は、実際のメッセージが一連の可能なメッセージから選択されることです。 システムは、設計時には不明であるため、選択されるものだけでなく、可能な選択ごとに動作するように設計する必要があります。
時間の経過に伴うトピック:トピックトレンドの非マルコフ連続時間モデル
9か月の個人的な電子メール、17年のNIPS研究論文、および200年を超える大統領の一般教書演説で結果を提示し、改善されたトピック、より優れたタイムスタンプ予測、および解釈可能な傾向を示します。
Twitterランク:トピックに敏感な影響力のあるTwitterユーザーを見つける
このホワイトペーパーでは、マイクロブログサービスの影響力のあるユーザーを特定する問題に焦点を当てています。 最も有名なマイクロブログサービスの1つであるTwitterは、「フォロー」と呼ばれるソーシャルネットワーキングモデルを採用しています。このモデルでは、各ユーザーが「フォロー」する相手を選択して、最初に許可を与えることなくツイートを受信できます。
ヘッドラインベースのソーシャルニュースクラスタリングのための差別的なバイタームトピックモデル
ソーシャルニュースはますます人気が高まっています。 ニュース組織や人気のジャーナリストは、ニュースを放送するためにソーシャルメディアをますます頻繁に使用し始めています。 ソーシャルニュースクラスタリングの主な課題は、テキストコンテンツが見出しにすぎず、全文よりもはるかに短いという事実にあります。
ショートテキストのバイタームトピックモデル
ツイートやインスタントメッセージなどの短いテキスト内のトピックを明らかにすることは、多くのコンテンツ分析アプリケーションにとって重要なタスクになっています。 ただし、このような短いテキストに従来のトピックモデル(LDAやPLSAなど)を直接適用すると、うまく機能しない場合があります。 基本的な理由は、従来のトピックモデルがドキュメントレベルの単語の共起パターンを暗黙的にキャプチャしてトピックを明らかにするため、短いドキュメントではデータが大幅に不足することにあります。