
Abfragemustergenerierung bei Google
Veröffentlicht: 2019-11-14Wie Abfragen Absichtsklassifikatoren bestimmen können
Wenn jemand nach etwas sucht, gibt er einige Schlüsselwörter in ein Suchfeld einer Suchmaschine ein.
Google hat vor kurzem ein Patent erhalten, das die Muster beinhaltet, die Abfragen in Suchanfragen sehen können.
Normalerweise können die in einer Suche verwendeten Schlüsselwörter eine Absicht hinter einer Suche angeben und können „den Umfang der vom Benutzer gewünschten Informationen angeben und können mithilfe eines Klassifikators erfasst werden, um einen Kontext für eine oder mehrere vom Benutzer ausgeführte Aktionen zu erfassen“.
Das ist der Fokus dieses neuen Patents.
Es sagt uns mehr über diesen Klassifikator und wie er von einer Suchmaschine wie Google abgeleitet werden könnte, um den Zweck einer Suche besser zu verstehen und „der Suche mithilfe des Klassifikators einen Kontext zuzuweisen“.
Ein Beispiel dafür liefert das Patent. Es sagt uns, dass die Absicht (z. B. Klassifikator) mehr über ein oder mehrere Themen sagen kann, die ein Suchender als Antwort auf die Abfrage in den Suchergebnissen angezeigt sehen möchte, und etwas darüber, wie spezifisch diese Informationen zu diesen Themen sein könnten.
Mit anderen Worten, Google würde die Benutzereingaben bezüglich der Suche prüfen, um über Themenkategorien zu entscheiden, um eine Anfrage zu beantworten.
Beispiele für Abfragen und Absichten
Einige verwandte Beispiele für Suchanfragen im Patent: [Barack Obama] und [Obama 2004 Convention Rede]. Diese Anfragen zeigen, dass Informationen über Barack Obama benötigt werden, die leicht unterschiedliche Themen mit unterschiedlicher Spezifität abdecken.
Google wird sich die Abfrage ansehen, um zu entscheiden, welche Absicht dahinter steckt. Es wird dann basierend auf dieser Absicht einen Klassifikator zuweisen.
Dieses Patent arbeitet zum Analysieren von Suchanfragen, Abfragemustern und Abfragedokumenten, um zusätzliche Abfragen, Abfragemuster und Abfragediagramme zu generieren, die für die Bereitstellung von Suchinhalten nützlich sein können, die einer oder mehreren Absichten entsprechen, die von Benutzern angegeben werden, die Suchanfragen eingeben.
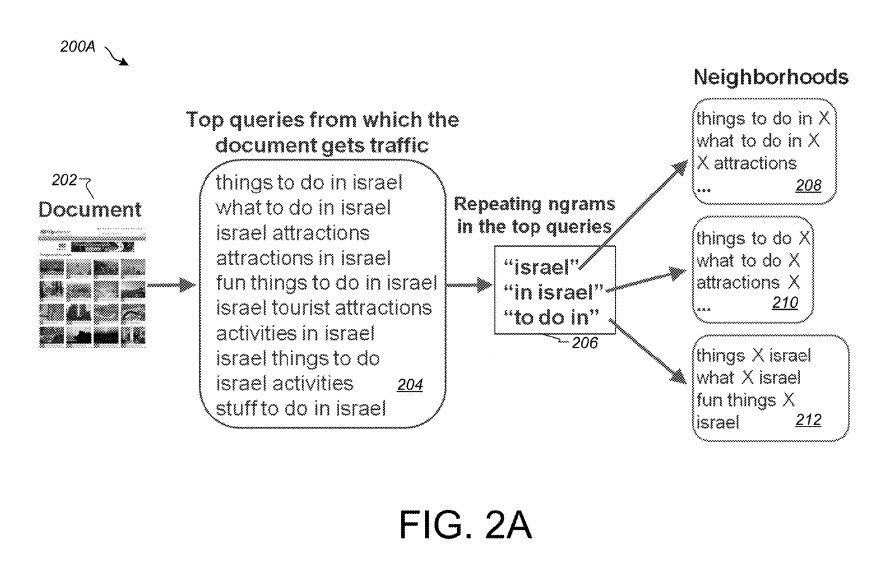
Uns wird gesagt, dass Suchanfragen und Suchdokumente unterschiedliche Auflösungen der Benutzerabsicht haben können. Google kann sich die Dokumente ansehen, die für eine Abfrage möglicherweise zurückgegeben werden, um ein Gefühl dafür zu bekommen, welche Absichten der Nutzer auf diese Abfrage haben könnte.
Das Patent sagt uns, dass die Betrachtung dieser Dokumente folgende Vorteile hat:
Auf diese Weise können die Algorithmen verwendet werden, die genau die durch die Dokumente implizierte Intent-Trennung nutzen, und der Intent kann mithilfe des Klassifikators auf die Abfragen projiziert werden. Diese Zuordnung kann verwendet werden, um Abfragemuster zu generieren und abzugleichen, die verwendet werden können, um Suchergebnisse mit vom Benutzer eingegebenen Suchanfragen abzugleichen.
Patent zum Mitnehmen
Wenn ich über diesen Ansatz nachdenke, schlägt es mir vor, dass Sie, wenn Sie eine Keyword-Recherche durchführen, nach den Keywords suchen sollten, für die Sie eine Optimierung in Betracht ziehen, und sich die Dokumente, die Google als Antwort darauf zurückgibt, sorgfältig ansehen, um eine Vorstellung davon zu bekommen welche Absicht Google diese Keywords vorschlägt.
Automatische Generierung von Abfragemustern
Abgesehen davon, dass die Absicht bestimmt werden kann, scheint dies der Schwerpunkt des Prozesses hinter diesem Patent zu sein:
… können die hierin beschriebenen Systeme und Verfahren ein Abfragemuster erkennen, das mit einer vom Benutzer eingegebenen Suchabfrage verbunden ist, und basierend auf dem erkannten Abfragemuster automatisch ähnliche Abfragemuster erzeugen. Insbesondere können die hierin beschriebenen Systeme und Verfahren auf Suchdokumente zugreifen, die einem erkannten Abfragemuster entsprechen, um ein oder mehrere Abfragemuster zu erzeugen, die verwendet werden können, um Dokumente zu finden, die den Suchdokumenten ähnlich sind, auf die zugegriffen wurde. Die Verwendung von Suchdokumenten zum Bestimmen der Absicht in einer Abfrage kann den Vorteil bieten, die von den Dokumenten implizierten Absichten und/oder Unterabsichten zu nutzen und diese Absichten und/oder Unterabsichten auf die empfangenen Suchabfragen zu projizieren.
Neben einem besseren Verständnis der Absicht hinter einer Abfrage kann Google also daran arbeiten, Muster hinter Abfragen zu identifizieren. Das Patent weist auf einige Beispiele hin:
Wie hierin verwendet, stellt eine Abfragevorlage eine Abfragephrase dar, die Abfrageabschnitte (z. B. Unterphrasen) umfasst und unterstützt, Ersetzungsabschnitte zu spezifizieren. Beispielsweise kann die Abfragevorlage [Wetter in X] verwendet werden, um Abfragen wie [Wetter in Paris], [Wetter in NYC] und [NYC-Wetter] darzustellen. Das „X“ steht für Ersatzanteile, während die Begriffe „Wetter“, „NYC“ und „Paris“ für Abfrageanteile stehen.
Ein Abfragemuster, das mehrere Beispiele haben kann, könnte also als Abfragevorlage bezeichnet werden. Ein Abfragemuster wie [Wetter in X] kann alle Abfragen darstellen, die den Begriff „Wetter“ und einen Begriff enthalten, der einen geografischen Standort identifiziert, wie [Wetter in Paris], [Wetter in NYC], [Wetter an der Ostküste ] und [Wetter in meiner Nähe].
Ein Abfragemuster kann Folgendes umfassen:
- Eine oder mehrere vordefinierte Regeln zum Abgleichen einer empfangenen Abfrage und zum Interpretieren der übereinstimmenden Abfrage
- Eine Sprachkennung (z. B. Französisch)
- Ein Land oder eine Domäne (z. B. Frankreich)
- Stoppwörter (die ignoriert werden können)
- Ein Stecker
- Ein Vertrauenswert
- Eine Abfrage teilt die Filterstrategie
Ein Abfrage-Annotator kann auch bei der Abfragemuster-Erzeugung verwendet werden.
Ein Abfrage-Annotator bestimmt, welche Entitäten in einer bestimmten Abfrage erscheinen, wobei jede dieser Entitäten eine kanonische Darstellung hat, die von der Sprache unabhängig ist. Beispielsweise kann die Anwendung eines Abfrage-Annotators auf die Abfrage „Wetter in Paris“ die Zeichenfolge „Paris“ annotieren. mit einer eindeutigen Kennung (z. B. „/m/05qtj“), die die kanonische Darstellung von „Paris“, der Hauptstadt Frankreichs, darstellt. Beachten Sie, dass die eindeutige Kennung aus dem Patent eine Maschinen-ID-Nummer von Freebase ist, die Google an anderer Stelle bei der Suche verwendet hat, um Entitäten zu identifizieren (siehe: Bildsuche und Trends in der Google-Suche mit FreeBase-Entitätsnummern).

Mithilfe solcher Abfragevorlagen, Abfragemuster und Abfrageannotatoren könnte Google andere Abfragemuster finden oder generieren, die wahrscheinlich dieselbe Nutzerabsicht zum Ausdruck bringen.
Ein Abfragemuster wie [Wetter in X] enthält beispielsweise auch:
[X-Wetter]
[wie ist das Wetter in X]
[wie ist das Wetter in X]
[wie ist die Temperatur in X]
[regnet es in X]
etc.
Dies liegt daran, dass jemand, der nach [Wetter in Paris] sucht, und jemand anderes, der nach [Wetter in Paris] sucht, wahrscheinlich ähnliche Absichten hat, dieselbe Art von Informationen zu sehen.
Der Umfang der automatischen Generierung von Abfragemustern
Wenn Sie ein Patent wie dieses lesen, fragen Sie sich vielleicht, wie oft es verwendet werden könnte. Manchmal haben wir das Glück, Aussagen wie die folgende in einem Patent zu erhalten (man beachte die hier beschriebenen „Milliarden von Webdokumenten“:
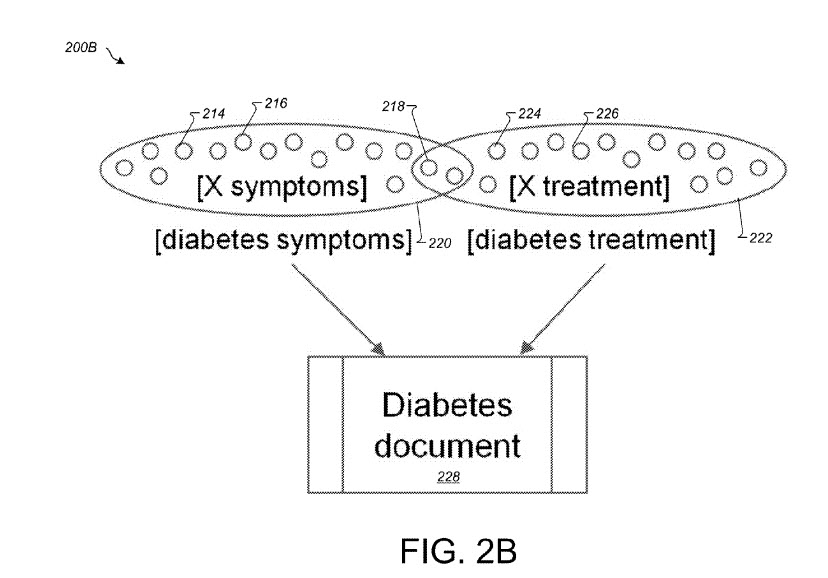
Der Mustergenerator kann so konfiguriert werden, dass er einen Satz ähnlicher Suchabfragen in einen Satz von Mustern umwandelt, indem er sich wiederholende Unterphrasen aus den Suchabfragen verwendet. Der Satz von Mustern kann basierend auf Milliarden von Webdokumenten, die im Intranet verfügbar sind, zu einem Musterdiagramm zusammengefasst werden. Im Allgemeinen kann jedes Dokument im Internet mehrere Paare von Abfragemustern beitragen, die ähnlich sein können. Diese Paare sind die Grundlage des aggregierten Mustergraphen. Im aggregierten Musterdiagramm stellt jedes Abfragemuster einen Knoten dar und alle zwei ähnlichen Knoten sind an einer Kante des Diagramms verbunden. Die Ähnlichkeit zwischen zwei verbundenen Knoten kann durch eine Ähnlichkeitsbewertung für die Kante, die die beiden Knoten verbindet, quantifiziert werden. Ein Paar ähnlicher Knoten kann als ähnliche Nachbarn bezeichnet werden. Die Verwendung ähnlicher Nachbarn zum Filtern von nicht zum Thema gehörenden Kandidatenmustern kann den Vorteil bieten, das Auftreten von ungenauen Suchergebnissen durch einen Benutzer in Beispielen zu verringern, in denen zwei Muster basierend auf den beiden Mustern, die ähnliche Suchergebnisse zurückgeben, als ähnlich angesehen werden, obwohl der Benutzer Die Absicht der beiden Muster ist tatsächlich nicht ähnlich (zB für die Abfragemuster [X Behandlung] und [X Symptome]). Dies liegt daran, dass viele Dokumente Datenverkehr von beiden Mustern erhalten. Unter Verwendung von Kriterien für ähnliche Nachbarn können die im System 100 verwendeten Algorithmen bestimmen, dass bestimmte Muster nicht wirklich ähnlich sind, selbst wenn verwandte Dokumente in denselben Suchergebnissen auftauchen.
Wir haben auch Patente gesehen, die Abfragevorlagen für Featured Snippets beschreiben. Ich habe darüber im Beitrag Featured Snippets – Natural Language Search Results for Intent Queries geschrieben. Dieser versucht, Abfragemuster zu identifizieren, die idealerweise mit Featured Snippets beantwortet werden können. Ich sehe in diesem Patent nicht den Begriff „Featured Snippets“, aber er enthält eine Reihe von Beispielen für Abfragemuster.
Beispielsweise können Dokumente zum Thema „Aktivitäten in Kalifornien“ von Suchenden bereitgestellt und ausgewählt werden, die Abfragen verwenden wie:
(a) „Aktivitäten in Kalifornien“
(b) „was in Kalifornien zu tun ist“
(c) „Sehenswürdigkeiten Kaliforniens“
(d) „Die besten Dinge, die man in Kalifornien tun kann“
etc.
Ähnliche Abfragen können die Entität "Kalifornien" mit einer wie "Ohio" austauschen.
Erkenntnisse aus dem Patent für die automatische Abfragemustergenerierung
Beim Durcharbeiten dieses Patents wurde ich an die Keyword-Recherche erinnert, die ich in der Vergangenheit durchgeführt habe, um Abfragemuster und Vorlagen zu finden und ihnen mithilfe einer Verkettungsfunktion in Excel Abfrageannotatoren hinzuzufügen.
Wenn wir über Absichten in Abfragen schreiben, sehen wir oft, dass Nutzer Navigations-, Informations- und Transaktionsabfragen erwähnen. Eines der letzten Male, in dem ich über Absichten in Abfragen geschrieben habe, war in dem Beitrag How Google May Identify Navigational Queries and Resources. Dieses Patent, das Abfragemuster untersucht, um die Absicht hinter einer Abfrage besser zu verstehen, kann genauere Informationen über die Absicht einer Suche liefern, als nur, ob eine Suche informations-, navigations- oder transaktionsbezogen ist.
2014 hatte Google das Biperpedia-Projekt am Laufen, das Abfrageprotokollinformationen verwendet, um eine Suchontologie zu erstellen, die kanonische Abfragen umfasst – wie Sie vielleicht Informationen darüber sammeln möchten, ob Sie sich entschieden haben, Abfragemuster und Abfragevorlagen zu verwenden. Wir haben die in diesem Patent erwähnten Entitäts-Rechner-IDs für Freebase-Nummern gesehen, wie sie in Googles Knowledge Graph zu finden sind. Quellen wie Biperpedia und der Wissensgraph wären also Orte, an denen Informationen über Abfragevorlagen gesammelt werden könnten, um auf Abfragen mit unterschiedlichen Absichten zu antworten.
Dieses Patent zur automatischen Abfragemustergenerierung finden Sie unter:
Automatische Generierung von Abfragemustern
Erfinder: Tomer Shmiel, Dvir Keysar und Vered Cohen
Rechtsnachfolger: GOOGLE LLC
US-Patent: 10.467.256
Bewilligt: 5. November 2019
Gespeichert: 3. August 2016
Abstrakt
Es wird ein allgemeiner Aspekt beschrieben, der ein computerimplementiertes Verfahren zum Erzeugen eines Mustergraphen umfasst. Das Verfahren kann das Zugreifen auf Daten umfassen, die sich auf einen Korpus von Webdokumenten beziehen. Die Daten können mehrere Abfrage-Dokument-Paare umfassen. Das Verfahren kann auch das Identifizieren mindestens eines Abfragemusters in der Vielzahl von Abfrage-Dokument-Paaren umfassen, und das Abfragemuster kann einem Teil von Webdokumenten im Korpus zugeordnet sein. Das Verfahren kann auch das Identifizieren einer Vielzahl von Untersätzen in dem mindestens einen Abfragemuster, das Bestimmen mehrerer anderer Abfragemuster, die mindestens einen der Vielzahl von Untersätzen enthalten, im Korpus von Webdokumenten und das Zuweisen von einen Klassifizierer für das mindestens eine Abfragemuster und jedes der Vielzahl von anderen Abfragemustern, die mindestens eine der Unterphrasen enthalten.