
Generazione di pattern di query su Google
Pubblicato: 2019-11-14In che modo le query possono determinare i classificatori di intenti
Quando qualcuno sta cercando qualcosa, digiterà alcune parole chiave in una casella di ricerca in un motore di ricerca.
A Google è stato recentemente concesso un brevetto relativo ai modelli che le query potrebbero essere visualizzate nelle ricerche.
Normalmente le parole chiave utilizzate in una ricerca possono indicare un intento dietro una ricerca e possono "indicare l'estensione delle informazioni desiderate dall'utente e possono essere catturate utilizzando un classificatore per catturare un contesto per una o più azioni eseguite dall'utente".
Questo è il focus di questo nuovo brevetto.
Ci dice di più su quel classificatore e su come potrebbe essere dedotto da un motore di ricerca come Google, per capire meglio lo scopo di una ricerca e per "assegnare un contesto alla ricerca usando il classificatore".
Il brevetto ne fornisce un esempio. Ci dice che l'intento (ad esempio, classificatore) può dire di più su uno o più argomenti che un ricercatore potrebbe desiderare di vedere visualizzato in risposta alla query nei risultati di ricerca e qualcosa su quanto specifiche potrebbero essere tali informazioni su quegli argomenti.
In altre parole, Google esaminerebbe l'input dell'utente relativo alla ricerca per decidere le categorie di argomenti per rispondere a una query.
Esempi di query e intenti
Un paio di esempi correlati di query di ricerca nel brevetto: [Barack Obama] e [Discorso alla convention di Obama 2004]. Queste domande mostrano la necessità di informazioni su Barack Obama che coprono argomenti leggermente diversi con diversi livelli di specificità.
Google esaminerà la query per decidere quale sia l'intento dietro. Quindi assegnerà un classificatore in base a tale intento.
Questo brevetto funziona per analizzare query di ricerca, modelli di query e documenti di query al fine di generare query aggiuntive, modelli di query e grafici di query che possono essere utili per fornire contenuti di ricerca che corrispondano a uno o più intenti indicati dagli utenti che inseriscono le query di ricerca.
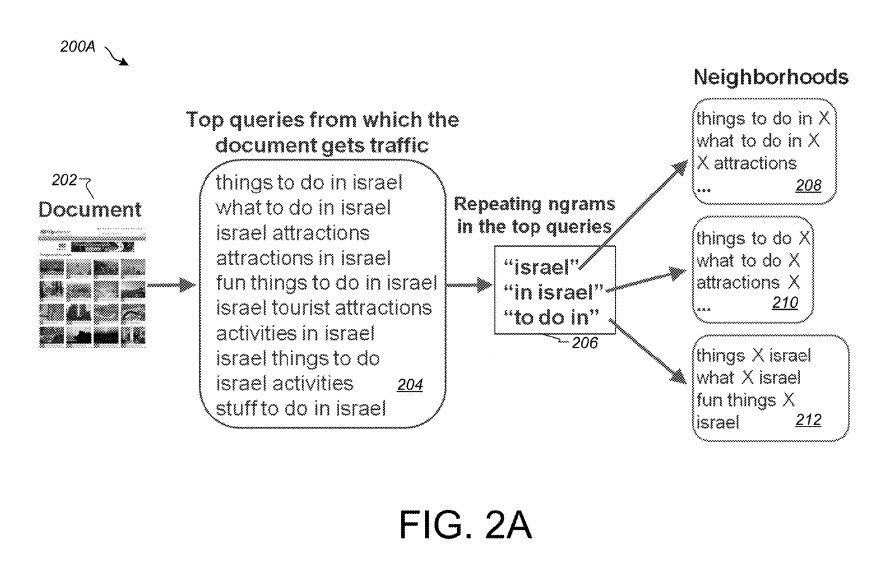
Ci viene detto che le query di ricerca e i documenti di ricerca possono avere diverse risoluzioni dell'intento dell'utente. Google può esaminare i documenti che potrebbero essere restituiti per una query per avere un'idea di quale potrebbe essere l'intento dell'utente in risposta a tale query.
Il brevetto ci dice che il vantaggio di guardare quei documenti è:
In questo modo, è possibile utilizzare algoritmi che sfruttano esattamente la separazione degli intenti implicita nei documenti e l'intento può essere proiettato sulle query utilizzando il classificatore. Questa mappatura può essere utilizzata per generare e abbinare modelli di query, che possono essere utilizzati per abbinare i risultati di ricerca alle query di ricerca immesse dall'utente.
Brevetto da asporto
Pensando a questo approccio, mi suggerisce che se stai eseguendo ricerche per parole chiave dovresti cercare le parole chiave che stai considerando di ottimizzare e guardare attentamente i documenti che Google sta restituendo in risposta ad essa, per avere un'idea di quale intento Google sta determinando quelle parole chiave suggeriscono.
Generazione automatizzata di modelli di query
Oltre a poter determinare l'intento, questo sembra essere il fulcro del processo alla base di questo brevetto:
… i sistemi e i metodi qui descritti possono rilevare un modello di query associato a una query di ricerca immessa dall'utente e generare automaticamente modelli di query simili in base al modello di query rilevato. In particolare, i sistemi e i metodi qui descritti possono accedere a documenti di ricerca che corrispondono a un pattern di query rilevato per generare uno o più pattern di query che possono essere utilizzati per trovare documenti simili ai documenti di ricerca a cui si accede. L'utilizzo di documenti di ricerca per determinare l'intento in una query può fornire il vantaggio di sfruttare gli intenti e/o gli intenti secondari impliciti nei documenti e proiettare quegli intenti e/o gli intenti secondari sulle query di ricerca ricevute.
Quindi, oltre a comprendere meglio l'intento dietro una query, Google potrebbe lavorare per identificare i modelli dietro le query. Il brevetto riporta alcuni esempi:
Come qui utilizzato, un modello di query rappresenta una frase di query che include parti di query (ad es. sottofrasi) e supporto per specificare parti di sostituzione. Ad esempio, il modello di query [meteo in X] può essere utilizzato per rappresentare query come [meteo a Parigi], [meteo a New York] e [meteo a New York]. La "X" rappresenta le parti di sostituzione, mentre i termini "meteo", "NYC" e "Parigi" rappresentano le parti di query.
Quindi, si potrebbe dire che un modello di query che può avere più esempi sia un modello di query. Un modello di query come [meteo in X] può rappresentare tutte le query che includono il termine "meteo" e un termine che identifica una posizione geografica, come [meteo a Parigi], [meteo a New York], [meteo nella costa orientale ] e [tempo vicino a me].
Un modello di query può includere:
- Una o più regole predefinite per abbinare una query ricevuta e interpretare la query corrispondente
- Un identificatore di lingua (ad es. francese)
- Un paese o un dominio (ad es. Francia)
- Stopword (che possono essere ignorati)
- Un connettore
- Un valore di fiducia
- Una query divide la strategia di filtro
Un annotatore di query può essere utilizzato anche nella generazione di pattern di query.
Un annotatore di query determina quali entità vengono visualizzate in una determinata query, dove ciascuna di tali entità ha una rappresentazione canonica indipendente dalla lingua, ad esempio, l'applicazione di un annotatore di query sulla query "meteo a Parigi" può annotare la stringa "Parigi" con un identificatore univoco (ad es. “/m/05qtj”) che rappresenta la rappresentazione canonica di “Parigi”, la capitale della Francia. Potresti notare che l'identificatore univoco del brevetto è un numero ID macchina, da Freebase, che Google ha utilizzato altrove nella ricerca per identificare le entità (vedi: Ricerca di immagini e tendenze nella ricerca di Google utilizzando i numeri di entità di FreeBase)

Utilizzando tali modelli di query, modelli di query e annotatori di query, Google potrebbe trovare o generare altri modelli di query che probabilmente esprimono lo stesso intento dell'utente.
Ad esempio, un modello di query come [meteo in X] include anche:
[X tempo]
[che tempo fa a X]
[com'è il tempo a X]
[qual è la temperatura in X]
[piove in X]
eccetera.
Questo perché qualcuno che cerca [meteo a Parigi] e qualcun altro che cerca [meteo a Parigi] probabilmente hanno lo stesso intento di vedere lo stesso tipo di informazioni.
La scala della generazione automatica di modelli di query
Leggendo un brevetto come questo, potresti chiederti con quale frequenza potrebbe essere utilizzato. A volte siamo abbastanza fortunati da ricevere dichiarazioni come la seguente in un brevetto (notare i "miliardi di documenti Web" descritti qui:
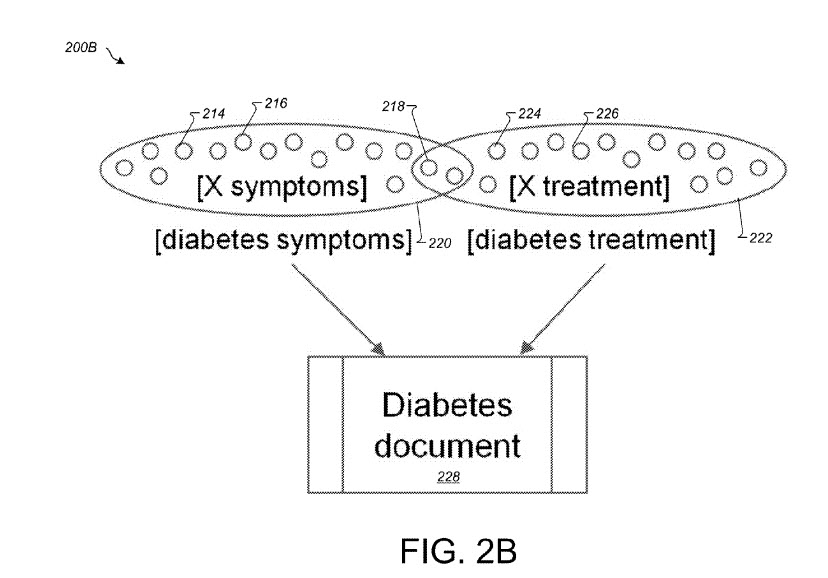
Il generatore di pattern può essere configurato per convertire un insieme di query di ricerca simili in un insieme di pattern, utilizzando frasi secondarie ripetute dalle query di ricerca. L'insieme di modelli può essere aggregato in un grafico di modelli basato su miliardi di documenti Web disponibili su Intranet. In generale, ogni documento su Internet può fornire diverse coppie di modelli di query che possono essere simili. Queste coppie sono la base del grafico del modello aggregato. Nel grafico del modello aggregato, ogni modello di query rappresenta un nodo e ogni due nodi simili sono collegati su un bordo del grafico. La somiglianza tra due nodi connessi può essere quantificata da un punteggio di similarità per il bordo che connette i due nodi. Una coppia di nodi simili può essere conosciuta come vicini simili. L'uso di vicini simili per filtrare modelli candidati fuori tema può fornire il vantaggio di ridurre la frequenza con cui un utente riceve risultati di ricerca imprecisi in esempi in cui due modelli sono considerati simili in base ai due modelli che restituiscono risultati di ricerca simili, anche se l'utente l'intento dei due modelli in realtà non è simile (ad esempio, per i modelli di query [trattamento X] e [sintomi X]). Questo perché molti documenti ricevono traffico da entrambi i modelli. Usando criteri di vicini simili, gli algoritmi utilizzati nel sistema 100 possono determinare che particolari modelli non sono effettivamente simili anche se documenti correlati vengono visualizzati negli stessi risultati di ricerca.
Abbiamo visto anche brevetti che descrivono modelli di query per snippet in primo piano. Ne ho scritto uno nel post Snippet in primo piano – Risultati della ricerca in linguaggio naturale per le query di intenti. Quello cerca di identificare i modelli di query a cui si potrebbe idealmente rispondere con frammenti in primo piano. Non vedo la frase "frammenti in primo piano" in questo brevetto, ma ha una serie di esempi di modelli di query.
Ad esempio, i documenti associati all'argomento "cose da fare in California" possono essere forniti e selezionati da utenti che utilizzano query come:
(a) “cose da fare in California”
(b) “cosa fare in California”
(c) “Attrazioni della California”
(d) "cose migliori da fare in California"
eccetera.
Query simili possono scambiare l'entità "California" con una come "Ohio".
Conclusioni dal brevetto per la generazione automatica di modelli di query
Lavorando su questo brevetto, mi sono ricordato della ricerca per parole chiave che ho svolto in passato, trovando modelli e modelli di query e aggiungendo annotatori di query a loro utilizzando una funzione di concatenazione in Excel.
Spesso quando scriviamo sull'intento nelle query, vediamo che le persone menzionano le query di navigazione, informative e transazionali. Una delle ultime volte che ho scritto sull'intento nelle query è stata nel post Come Google può identificare le query e le risorse di navigazione. Questo brevetto che esamina i modelli di query per comprendere meglio l'intento alla base di una query può fornire informazioni più precise sull'intento di una ricerca rispetto al semplice fatto che una ricerca sia informativa, di navigazione o transazionale.
nel 2014 Google aveva avviato il progetto Biperpedia, che utilizzava le informazioni del registro delle query per creare un'ontologia di ricerca, che includeva query canoniche, ad esempio se si desidera raccogliere informazioni se si decide di eseguire operazioni con modelli di query e modelli di query. Abbiamo visto gli ID macchina delle entità a cui si fa riferimento in questo brevetto per i numeri freebase come potrebbero essere trovati nel grafico della conoscenza di Google. Quindi fonti come Biperpedia e il grafico della conoscenza sarebbero luoghi in cui potrebbero essere raccolte informazioni sui modelli di query, da utilizzare per rispondere a query con intenti diversi.
Questo brevetto per la generazione automatica di modelli di query è disponibile all'indirizzo:
Generazione automatica di modelli di query
Inventori: Tomer Shmiel, Dvir Keysar e Vered Cohen
Assegnatario: GOOGLE LLC
Brevetto USA: 10.467.256
Concesso: 5 novembre 2019
Archiviato: 3 agosto 2016
Astratto
Viene descritto un aspetto generale che include un metodo implementato da computer per generare un grafico di pattern. Il metodo può includere l'accesso a dati relativi a un corpus di documenti web. I dati possono includere una pluralità di coppie query-documento. Il metodo può anche includere l'identificazione di almeno un pattern di query nella pluralità di coppie di query-documento e il pattern di query può essere associato a una porzione di documenti web nel corpus. Il metodo può anche includere l'identificazione di una pluralità di sottofrasi nell'almeno un modello di query, la determinazione, nel corpus di documenti web, una pluralità di altri modelli di query che includono almeno una della pluralità di sottofrasi e l'assegnazione un classificatore per almeno un modello di query e ciascuno della pluralità di altri modelli di query che includono almeno una delle sottofrasi.