
スタイルガイドに追加注釈テキスト:アンカーテキストのインデックス作成
公開: 2019-02-22スタイルガイドの実行
私が過去に出くわし、推奨したことの1つは、スタイルガイドの使用です。 私がSEOを行っていた大学で最初にその概念を聞いた。 学校の学部長は、あるフレーズが気に入らず、別のフレーズを主張しました。これは、サイトの主要なキーワードフレーズの1つでした。 そのような好みや、サイトに適用される可能性のある他のアプローチを追跡する場所があると便利です。 サイトのURLでのすべての小文字の将来の使用などを推奨するサイトのスタイルガイドをお勧めします。 Go Fish Digitalにはスタイルガイドはありませんが、私たちのサイトやクライアントサイトで使用している特定のテクニックに関する情報が含まれているwikiがあります。
Googleで更新されたアンカーテキストの索引付け
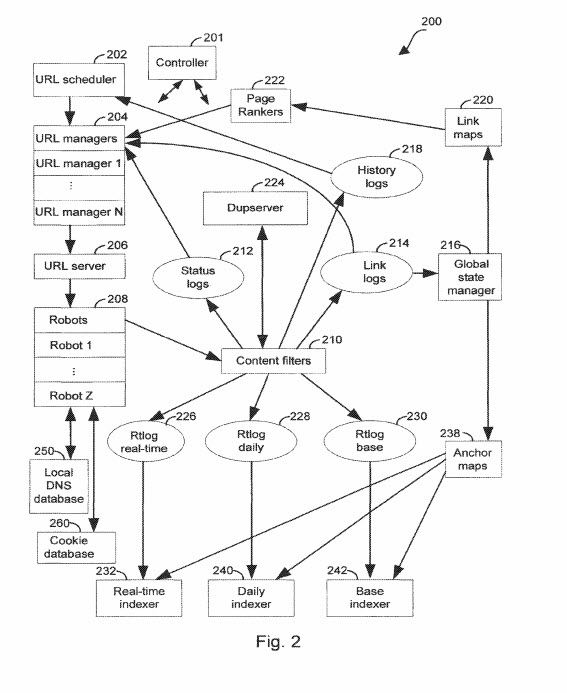
ウィキにいくつか追加しましたが、さらにいくつか追加する必要があります。 最新の追加は、2003年に検索エンジンによって最初に提出されたGoogle特許(最初に付与された2007年に最初に書いた)を更新する、ちょうど出たばかりの継続特許で見たものです。アンカーテキストのインデックス作成の使用について、SEOを行うほとんどの人によく知られているSEOの側面。 Googleが過去にこの新しいアプローチを使用していたという噂を聞いたことがありますが、この新しい特許のクレームセクションで、ごく最近まで書面でそれについて何も見ていませんでした。 問題の特許は、発明者としてGoogle BrainTeamの責任者であるJeffDeanがいる特許です。 彼はまた、誰かがリンクをクリックしてPageRankの重みを決定する可能性にもっと注意を払った、ReasonableSurfer特許の背後にある発明者の1人です。
アンカーテキストの索引付けに関するこの更新された特許の最新バージョンは、次の場所にあります。
Webクローラーシステムでのアンカータグのインデックス作成
発明者:Huican Zhu、Jeffrey Dean、Sanjay Ghemawat、Bwolen Po-Jen Yang、およびAnurag Acharya
譲受人:GOOGLE LLC
米国特許:10,210,256
付与:2019年2月19日
提出日:2016年4月1日
概要
リンクされたドキュメントのコレクション内のドキュメントにインデックスを付けるための方法とシステムが提供されます。 ソースドキュメントとターゲットドキュメントの1つ以上のペアを含むリンクログにアクセスします。 1つ以上のターゲットドキュメントとソースドキュメントのペアを含む、並べ替えられたアンカーマップが生成されます。 ソートされたアンカーマップのペアリングは、ターゲットドキュメント識別子に基づいて並べ替えられます。
アンカーテキストの近くの注釈テキストこの特許の新機能
この継続特許のクレームで新しい注目すべき点の1つは、リンクのアンカーテキストから一定の距離内にある注釈テキストの言及です。これは、リンクされているページの内容に影響を与える可能性があります。 この特許の最新バージョンには、注釈テキストを参照するこれらの新しいクレームの一部を含めます。
主張されているのは:
1.少なくとも1つのプロセッサを含むシステム。 ドキュメントを検索するためのインデックス。ドキュメントに関連付けられた用語を含むインデックス。 少なくとも1つのプロセッサによって実行されると、ウェブクローラーを介してソースドキュメントを取得し、ソースドキュメント内で注釈テキストを識別し、注釈テキストが所定の距離内のテキストであることを含む操作を実行するメモリ記憶命令。ターゲットドキュメントおよび少なくとも1つの用語を含む注釈テキストへのアウトバウンドリンク、用語とソースドキュメント間の関連付けをインデックスに格納し、インデックスに格納し、注釈テキストの識別に応答して、用語とターゲット間の関連付けドキュメント、識別、インデックス内の用語に関連付けられた用語、ソースドキュメント、およびターゲットドキュメントを含むクエリの受信に応答し、応答するドキュメントのリスト内のソースドキュメントとターゲットドキュメントを含む関連付けの識別に応答します。クエリに応答し、クエリに応答するドキュメントのリストをクエリの検索結果として返します。
前記ターゲット文書がまだクロールされていない、請求項1に記載のシステム。
前記アウトバウンドリンクは、前記ソースドキュメント内のアンカータグであり、前記注釈は、前記アンカータグに関連付けられた前記アンカーテキストである、請求項1に記載のシステム。
インデクサによってアクセスされるアンカーマップをさらに含み、アンカーマップは、以下を識別する少なくとも1つのエントリを含む、請求項1に記載のシステム。 複数のソースドキュメント識別子。ここで、ソースドキュメントは、それぞれのターゲットドキュメントへのアウトバウンドリンクを含む。 各ソースドキュメント識別子に対して少なくとも1つの注釈であり、注釈は、それぞれのソースドキュメントから抽出されたテキストパッセージを含み、テキストパッセージは、それぞれのアウトバウンドリンクの所定の距離内にある。
前記アンカーマップは、少なくとも1つの注釈の属性をさらに識別する、請求項4に記載のシステム。
前記注釈は、前記ソース文書からのテキストの連続ブロックである、請求項1に記載のシステム。
前記注釈が、前記ソース文書内の前記アンカータグの外側のテキストを含む、請求項1に記載のシステム。
前記メモリは、少なくとも1つのプロセッサによって実行されると、以下を含む動作を実行する命令をさらに記憶する、請求項1に記載のシステム。ターゲットドキュメントへのアウトバウンドリンクを含む各ソースドキュメントからの部分的なクエリに依存しない関連性メトリックの寄与の。

このアンカーテキスト索引特許の最も古いバージョン
私は2007年にアンカーテキスト特許の最も初期のバージョンについて、アンカーテキストとさまざまなクロール速度に関するGoogle特許の投稿に書きました。 Googleがどのようにウェブページをクロールし、さまざまなレートでインデックスを作成し、さまざまなタイプのリダイレクトを処理したかについて、非常に有益でした。
特許の最新バージョンには、12年前に書いた投稿で、以前のバージョンでは書いていなかった更新されたプロセスが含まれています。
アンカーテキストの近くに関連テキストに言及しているクレームの一部を含めたので、特許の最も古いバージョンであるWebクローラーシステムのアンカーテキストインデックス(2003年7月3日提出)からのクレームを示す必要があります。 そのバージョンの特許からの最初の8つのクレームは次のとおりです(これらを最新バージョンの上記の8つと比較してください)。
主張されているのは:
リンクされたドキュメントのコレクション内のドキュメントに関連する情報を処理する方法。リンクログへのアクセス、複数のリンクレコードを含むリンクログ、ソースドキュメントを識別する各リンクレコード、および1つまたは複数のリストを含む方法。ソースドキュメント内の1つ以上のアウトバウンドリンクによってポイントされるより多くのターゲットドキュメント。 識別されたソースドキュメントのソースドキュメント識別子と、識別されたターゲットドキュメントのリストの1つ以上のターゲットドキュメント識別子を含むリンクレコード。 リンクレコードは、リンクされたドキュメントのコレクション内のクロールされたドキュメントから抽出された情報に少なくとも部分的に基づいています。 リンクログに対応し、複数のアンカーレコードを含むソートされたアンカーマップを出力します。各アンカーレコードは、それぞれのターゲットドキュメントとインバウンドリンクのリストを識別します。インバウンドリンクのリストは、それぞれへのリンクを含むソースドキュメントを識別します。ターゲットドキュメント; それぞれのターゲットドキュメント識別子を含むアンカーレコード。 ここで、複数のアンカーレコードは、少なくとも部分的に、それらのそれぞれのターゲットドキュメント識別子に基づいて、ソートされたアンカーマップ内で順序付けられる。 ここで、複数のアンカーレコード内のそれぞれのターゲットドキュメント識別子は、リンクログ内の1つまたは複数のターゲットドキュメント識別子のうちの1つに対応する。
ソートされたアンカーマップ内の各アンカーレコードが、注釈のそれぞれのリストをさらに含む、請求項1に記載の方法。
【請求項3】それぞれのアンカーレコードの注釈のそれぞれのリストに含まれる各注釈は、それぞれのターゲット文書へのリンクを含むそれぞれのソース文書を識別するそれぞれのインバウンドリンクに対応する、請求項2に記載の方法。
前記ソートされたアンカーマップ内の前記アンカーレコードの注釈のそれぞれのリストにおける少なくとも1つのエントリは、テキストパッセージおよびテキストパッセージの属性のリストを含む、請求項2に記載の方法。
前記テキストパッセージは、前記アンカーレコードのソース文書内のそれぞれのソース文書内の前記アンカータグの所定の距離内のテキストから決定される、請求項4に記載の方法。
前記アクセスおよび出力を繰り返して、ソートされたアンカーマップの階層化されたセットを生成することをさらに含む、請求項1に記載の方法。
前記マージ条件が満たされたときに、前記ソートされたアンカーマップの階層化されたセットのサブセットをマージして、前記マージされたアンカーマップを生成することをさらに含む、請求項6に記載の方法。 ここで、マージされたアンカーマップは、複数のマージされたアンカーレコードを含み、各マージされたアンカーレコードは、ソートされたアンカーマップの階層化されたセットのサブセットからの少なくとも1つのアンカーレコードに対応し、マージされたアンカーレコードは、以下に基づいてマージされたアンカーマップで順序付けられる。それぞれのターゲットドキュメント識別子。
ソートされたリンクマップを出力することをさらに含み、ソートされたリンクマップは複数のリンクマップレコードを含み、各リンクマップレコードはソースドキュメント識別子および関連するリンクレコード内のターゲットドキュメント識別子のリストを含む。
注釈テキストをアンカーテキストの索引付けに導入する
この特許の新しいクレームでの注釈テキストの言及に注意してください。 特許が保護することを目的としたプロセスを反映するように特許が更新され、他の検索エンジンの使用を除外することを考えると、アンカーテキストの近くに注釈テキストを追加するというアイデアは私にとって非常に興味深いものです。 この特許は、リンク付きの注釈テキストの使用方法に関する正確なロードマップを提供していませんが、実験する価値のあるものとしてそれを面白くするのに十分な情報を提供しています。
また、コンテンツ作成者が、その注釈テキストに含まれる用語でランク付けしたい他のページへのリンクを含むコンテンツを作成するときに使用することを検討するためのスタイルガイドに追加します。
SEOは、スキーマとナレッジパネルを含むよりセマンティックなプロセスに向かって進化している可能性がありますが、アンカーテキストの使用法など、2003年に特許に最初に提出されたものも更新される可能性があります。
あなたへの良いリンク。