
Dodaj tekst adnotacji do przewodnika po stylu: Indeksowanie tekstu zakotwiczenia
Opublikowany: 2019-02-22Prowadzenie przewodnika po stylach
Jedną z rzeczy, na które natknąłem się i którą poleciłem w przeszłości, było użycie przewodnika stylu. Po raz pierwszy usłyszałem koncepcję na uniwersytecie, dla którego robiłem SEO. Dziekanowi szkoły nie spodobała się jedna fraza i nalegał na inną, która była jednym z naszych głównych fraz kluczowych dla witryny. Dobrze jest mieć miejsce, w którym można śledzić takie preferencje i inne podejścia, które mogą mieć zastosowanie do witryny. Polecam przewodnik po stylu dla witryn, które zalecają takie rzeczy, jak przyszłe użycie wszystkich małych liter w adresach URL witryn. Go Fish Digital nie ma przewodnika po stylu, ale ma wiki, w której zawiera informacje o konkretnych technikach, których używamy w naszej witrynie, a także w witrynach klientów.
Zaktualizowano indeksowanie tekstu kotwicy w Google
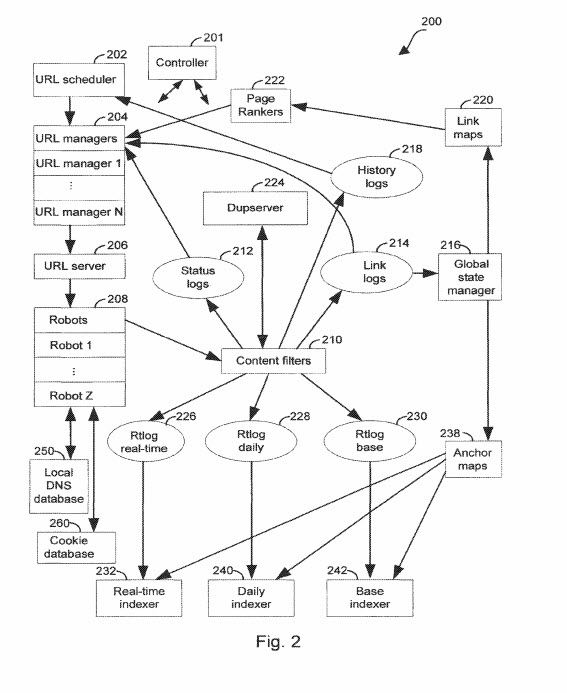
Dodałem kilka rzeczy do naszej wiki i mam jeszcze kilka rzeczy do dodania. Najnowszym dodatkiem będzie coś, co widziałem w patencie kontynuacyjnym, który właśnie wyszedł, aktualizując patent Google, który został pierwotnie zgłoszony przez wyszukiwarkę w 2003 r. (o którym pisałem pierwotnie w 2007 r., kiedy został przyznany po raz pierwszy). aspekt SEO, który jest znany większości osób zajmujących się SEO, dotyczący korzystania z indeksowania tekstu kotwicy. Słyszałem plotki, że Google używało tego nowego podejścia w przeszłości, ale nie widziałem nic na ten temat na piśmie do niedawna, w sekcji roszczeń tego nowego patentu. Omawiany patent to taki, który ma szefa zespołu Google Brain jako wynalazcę, Jeffa Deana. Jest także jednym z wynalazców patentu Reasonable Surfer, który zwraca większą uwagę na prawdopodobieństwo, że ktoś może kliknąć link, aby określić wagę PageRank
Najnowszą wersję tego zaktualizowanego patentu na indeksowanie tekstu kotwicy można znaleźć tutaj:
Zakotwiczenie indeksowania tagów w systemie robota sieciowego
Wynalazcy: Huican Zhu, Jeffrey Dean, Sanjay Ghemawat, Bwolen Po-Jen Yang i Anurag Acharya
Pełnomocnik: GOOGLE LLC
Patent USA: 10 210 256
Przyznano: 19 lutego 2019 r.
Złożony: 1 kwietnia 2016 r.
Abstrakcyjny
Provided to metoda i system indeksowania dokumentów w zbiorze powiązanych dokumentów. Dostęp do dziennika łączy, zawierającego co najmniej jedną parę dokumentów źródłowych i dokumentów docelowych. Generowana jest posortowana mapa zakotwiczenia, zawierająca jeden lub więcej par dokumentu docelowego z dokumentem źródłowym. Pary w posortowanej mapie kotwic są uporządkowane na podstawie identyfikatorów dokumentów docelowych.
Tekst adnotacji w pobliżu tekstu kotwicy Nowość w tym patencie
Jedną z zauważalnych rzeczy, która jest nowością w zastrzeżeniach tego patentu kontynuacyjnego, jest wzmianka o tekście adnotacji w pewnej odległości od tekstu zakotwiczenia linku, co może mieć wpływ na to, do czego może być linkowana strona. W najnowszej wersji tego patentu uwzględnię niektóre z tych nowych zastrzeżeń, które odnoszą się do tekstu adnotacji:
Twierdzi się, że:
1. System zawierający: co najmniej jeden procesor; indeks do wyszukiwania dokumentów, indeks zawierający terminy związane z dokumentami; oraz instrukcje przechowywania w pamięci, które po wykonaniu przez co najmniej jeden procesor wykonują operacje, w tym uzyskiwanie, za pośrednictwem przeszukiwacza sieci, dokumentu źródłowego, identyfikowanie w dokumencie źródłowym tekstu adnotacji, przy czym tekst adnotacji jest tekstem w określonej odległości od łącze wychodzące do dokumentu docelowego i tekstu adnotacji zawierające co najmniej jeden termin, przechowywanie w indeksie powiązania między terminem a dokumentem źródłowym, przechowywanie w indeksie, reagowanie na identyfikację tekstu adnotacji, powiązanie między terminem a celem dokument, identyfikujący, reagujący na otrzymanie zapytania, które zawiera termin, dokument źródłowy i dokument docelowy skojarzone z terminem w indeksie , reagujący na identyfikację powiązań, w tym dokument źródłowy i dokument docelowy na liście reagujących dokumentów do zapytania i zwrócenie listy dokumentów odpowiadających na zapytanie jako wyniku wyszukiwania zapytania.
2. System według zastrzeżenia 1, w którym dokument docelowy nie został jeszcze przeszukany.
3. System według zastrzeżenia 1, w którym łącze wychodzące jest znacznikiem zakotwiczenia w dokumencie źródłowym, a adnotacja jest tekstem zakotwiczenia powiązanym ze znacznikiem zakotwiczenia.
4. System według zastrzeżenia 1, zawierający ponadto mapę kotwic, do której uzyskuje dostęp indeksator, przy czym mapa kotwic zawiera co najmniej jeden wpis, który identyfikuje: odpowiedni dokument docelowy; wiele identyfikatorów dokumentu źródłowego, przy czym dokument źródłowy zawiera łącze wychodzące do odpowiedniego dokumentu docelowego; i co najmniej jedną adnotację dla każdego identyfikatora dokumentu źródłowego, adnotacja zawiera fragment tekstu wyodrębniony z odpowiedniego dokumentu źródłowego, przy czym fragment tekstu znajduje się w określonej z góry odległości od odpowiedniego łącza wychodzącego .
5. System według zastrzeżenia 4, mapa zakotwiczenia dodatkowo identyfikuje atrybut co najmniej jednej adnotacji.
6. System według zastrzeżenia 1, w którym adnotacja jest ciągłym blokiem tekstu z dokumentu źródłowego.
7. System według zastrzeżenia 1, w którym adnotacja zawiera tekst poza znacznikiem kotwicy w dokumencie źródłowym.
8. System według zastrzeżenia 1, w którym pamięć dodatkowo przechowuje instrukcje, które po wykonaniu przez co najmniej jeden procesor wykonują operacje obejmujące: obliczanie metryki trafności niezależnej od zapytania dla dokumentu docelowego, przy czym metryka trafności niezależnej od zapytania zawiera sumę częściowego, niezależnego od zapytania wkładu metryki istotności z każdego dokumentu źródłowego, który zawiera łącze wychodzące do dokumentu docelowego.

Najstarsza wersja tego patentu na indeksowanie tekstu kotwicy
O najwcześniejszej wersji patentu na tekst zakotwiczenia pisałem w 2007 r. w poście Patent Google na tekst zakotwiczenia i różne wskaźniki indeksowania. Było to bardzo pouczające o tym, jak Google indeksowało strony internetowe i indeksowało je z różnymi szybkościami oraz obsługiwało przekierowania różnych typów.
Najnowsza wersja patentu zawiera zaktualizowany proces, o którym nie pisałem we wcześniejszej wersji w poście, który napisałem 12 lat temu.
Ponieważ w pobliżu tekstu zakotwiczenia umieściłem niektóre zastrzeżenia wspominające tekst skojarzeń, powinienem pokazać zastrzeżenia z najstarszej wersji patentu, Anchor Text Indexing in a Web Crawler System (złożonej 3 lipca 2003 r.). Oto pierwsze 8 roszczeń z tej wersji patentu (porównaj je z 8 powyżej z najnowszej wersji):
Twierdzi się, że:
1. Sposób przetwarzania informacji związanych z dokumentami w zbiorze powiązanych dokumentów, który to sposób obejmuje: dostęp do dziennika dowiązań, dziennika dowiązań, który zawiera wiele rekordów dowiązań, przy czym każdy rekord dowiązania identyfikuje dokument źródłowy i listę jednego lub więcej dokumentów docelowych, na które wskazuje co najmniej jedno łącze wychodzące w dokumencie źródłowym; rekord łącza zawierający identyfikator dokumentu źródłowego dla zidentyfikowanego dokumentu źródłowego i jeden lub więcej identyfikatorów dokumentu docelowego dla zidentyfikowanej listy dokumentów docelowych; przy czym rekordy linków opierają się, przynajmniej częściowo, na informacjach pobranych z przeszukanych dokumentów w zbiorze dokumentów, do których prowadzą linki; i wyprowadzanie posortowanej mapy zakotwiczenia, która odpowiada dziennikowi łączy i zawiera wiele rekordów zakotwiczenia, każdy rekord zakotwiczenia identyfikuje odpowiedni dokument docelowy i listę linków przychodzących, lista linków przychodzących identyfikuje dokumenty źródłowe, które zawierają linki do odpowiednich dokument docelowy; rekord kotwicy zawierający odpowiedni identyfikator dokumentu docelowego; przy czym wiele rekordów zakotwiczeń jest uporządkowanych w posortowanej mapie zakotwiczeń na podstawie, przynajmniej częściowo, ich odpowiednich identyfikatorów dokumentów docelowych; i w którym każdy odpowiedni identyfikator dokumentu docelowego w wielu rekordach zakotwiczenia odpowiada jednemu z jednego lub większej liczby identyfikatorów dokumentu docelowego w dzienniku łączy.
2. Sposób według zastrzeżenia 1, w którym każdy rekord kotwicy w posortowanej mapie kotwic zawiera ponadto odpowiednią listę adnotacji.
3. Sposób według zastrzeżenia 2, w którym każda adnotacja zawarta na odpowiedniej liście adnotacji dla odpowiedniego rekordu kotwicy odpowiada odpowiedniemu łączu przychodzącemu identyfikującemu odpowiedni dokument źródłowy, który zawiera łącze do odpowiedniego dokumentu docelowego.
4. Sposób według zastrzeżenia 2, w którym co najmniej jeden wpis na odpowiedniej liście adnotacji rekordu zakotwiczenia w posortowanej mapie zakotwiczenia zawiera fragment tekstu i listę atrybutów fragmentu tekstu.
5. Sposób według zastrzeżenia 4, w którym fragment tekstu jest określany na podstawie tekstu w określonej odległości od znacznika zakotwiczenia w odpowiednim dokumencie źródłowym w dokumentach źródłowych rekordu zakotwiczenia.
6. Sposób według zastrzeżenia 1, obejmujący ponadto powtarzanie uzyskiwania dostępu i wysyłania w celu utworzenia warstwowego zestawu posortowanych map kotwic.
7. Sposób według zastrzeżenia 6, obejmujący ponadto, gdy warunek scalania został spełniony, scalanie podzbioru warstwowego zestawu posortowanych map zakotwiczeń w celu wytworzenia scalonej mapy zakotwiczenia; przy czym scalona mapa kotwic zawiera wiele scalonych rekordów kotwic, przy czym każdy scalony rekord kotwic odpowiada co najmniej jednemu rekordowi kotwic z podzbioru warstwowego zestawu posortowanych map kotwic, przy czym scalone rekordy kotwic są uporządkowane w scalonej mapie kotwic na podstawie ich odpowiednie identyfikatory dokumentów docelowych.
8. Sposób według zastrzeżenia 1, obejmujący ponadto wyprowadzanie posortowanej mapy dowiązań, przy czym posortowana mapa dowiązań zawiera wiele rekordów mapy dowiązań, przy czym każdy rekord mapy dowiązań zawiera identyfikator dokumentu źródłowego i listę identyfikatorów dokumentów docelowych w skojarzonym rekordzie dowiązania.
wprowadzenie tekstu adnotacji do indeksowania tekstu kotwicy
Zwróć uwagę na wzmianki o tekście adnotacji w nowych zastrzeżeniach dotyczących tego patentu. Biorąc pod uwagę, że patent został zaktualizowany w celu odzwierciedlenia procesu, który patent ma chronić, i wykluczenia z używania innych wyszukiwarek, pomysł dodania tekstu adnotacji w pobliżu tekstu zakotwiczenia jest dla mnie bardzo interesujący. Patent nie zapewnia dokładnej mapy drogowej, jak używać tekstu adnotacji z linkami, ale dostarcza wystarczającej ilości informacji, aby uczynić go interesującym jako czymś, z czym warto poeksperymentować.
Oraz dodanie przewodnika po stylu dla twórców treści, których należy użyć podczas tworzenia treści zawierającej łącza do innych stron, które mogą chcieć umieścić w rankingu pod kątem terminów zawartych w tekście adnotacji.
SEO może ewoluować w kierunku bardziej semantycznego procesu obejmującego schematy i panele wiedzy, ale widzimy również aktualizacje dotyczące tego, jak rzeczy pierwotnie zgłoszone w patentach w 2003 roku, takie jak użycie tekstu kotwicy, mogą być również aktualizowane.
Dobre połączenie z tobą.