
Ajouter à votre guide de style Texte d'annotation : Indexation de texte d'ancrage
Publié: 2019-02-22Exécution d'un guide de style
Une chose que j'ai rencontrée et que j'ai recommandée dans le passé a été l'utilisation d'un guide de style. J'ai entendu le concept pour la première fois dans une université pour laquelle je faisais du référencement. Le doyen de l'école n'aimait pas une phrase et a insisté sur une autre, qui était l'une de nos principales phrases-clés pour le site. C'est bien d'avoir un endroit pour garder une trace des préférences comme ça, et d'autres approches qui peuvent s'appliquer à un site. J'ai recommandé un guide de style pour les sites recommandant des choses comme l'utilisation future de toutes les lettres minuscules dans les URL des sites. Go Fish Digital n'a pas de guide de style, mais il a un wiki où nous incluons des informations sur les techniques spécifiques que nous utilisons sur notre site, ainsi que sur les sites clients.
Indexation de texte d'ancrage mise à jour sur Google
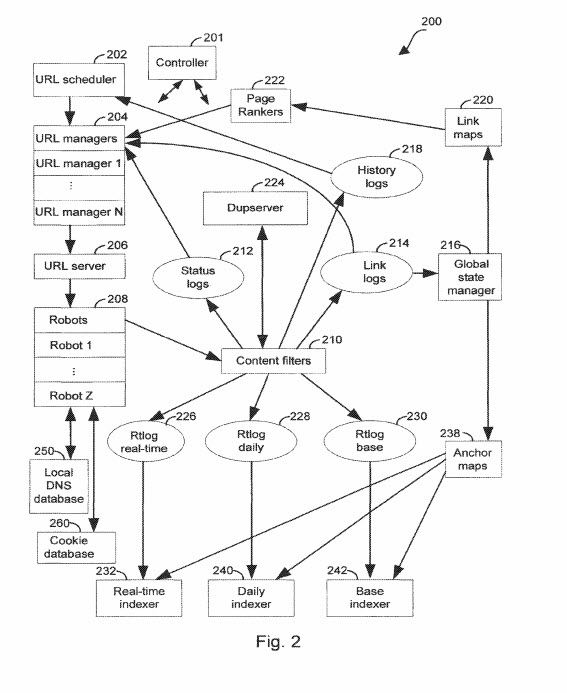
J'ai ajouté quelques éléments à notre wiki et j'ai encore quelques éléments à y ajouter. Le dernier ajout sera quelque chose que j'ai vu dans un brevet de continuation qui vient de sortir, mettant à jour un brevet Google qui a été initialement déposé en 2003 par le moteur de recherche (dont j'ai parlé à l'origine en 2007 lorsqu'il a été accordé pour la première fois). un aspect du référencement qui est familier à la plupart des personnes faisant du référencement, à propos de l'utilisation de l'indexation de texte d'ancrage. J'ai entendu des rumeurs selon lesquelles Google utilisait cette nouvelle approche dans le passé, mais je n'en avais rien vu par écrit jusqu'à très récemment, dans la section des revendications de ce nouveau brevet. Le brevet en question est celui dont le chef de l'équipe Google Brain est un inventeur, Jeff Dean. Il est également l'un des inventeurs du brevet Reasonable Surfer, qui accorde plus d'attention à la probabilité que quelqu'un clique sur un lien, à utiliser pour déterminer le poids du PageRank.
La dernière version de ce brevet mis à jour sur l'indexation de texte d'ancrage est disponible ici :
Indexation des balises d'ancrage dans un système de robot d'indexation Web
Inventeurs : Huican Zhu, Jeffrey Dean, Sanjay Ghemawat, Bwolen Po-Jen Yang et Anurag Acharya
Cessionnaire : GOOGLE LLC
Brevet américain : 10 210 256
Attribué : 19 février 2019
Déposé : 1 avril 2016
Résumé
L'invention concerne un procédé et un système d'indexation de documents dans une collection de documents liés. Un journal de liens, comprenant une ou plusieurs paires de documents source et de documents cibles, est accessible. Une carte d'ancrage triée, contenant un ou plusieurs appariements document cible-document source, est générée. Les appariements dans la carte d'ancrage triée sont classés en fonction des identificateurs de document cible.
Texte d'annotation près du texte d'ancrage Nouveau dans ce brevet
L'une des nouveautés notables dans les revendications de ce brevet de continuation est la mention du texte d'annotation, à une certaine distance du texte d'ancrage pour un lien, ce qui pourrait influencer le sujet d'une page qui est liée. J'inclurai certaines de ces nouvelles revendications dans la dernière version de ce brevet qui font référence au texte d'annotation :
Ce qui est revendiqué est:
1. Un système comprenant : au moins un processeur ; un index de recherche de documents, l'index comprenant des termes associés à des documents ; et des instructions de stockage en mémoire qui, lorsqu'elles sont exécutées par le au moins un processeur, effectuent des opérations comprenant l'obtention, via un moteur de recherche Web, d'un document source, l' identification, dans le document source, d'un texte d'annotation, le texte d'annotation étant du texte à une distance prédéterminée d'un lien sortant vers un document cible et le texte d'annotation comprenant au moins un terme, stockant dans l'index une association entre le terme et le document source, stockant dans l'index, en réponse à l'identification du texte d'annotation, une association entre le terme et la cible document, identifiant, en réponse à la réception d'une requête qui inclut le terme, le document source et le document cible associés au terme dans l'index , en réponse à l'identification des associations, y compris le document source et le document cible dans une liste de documents en réponse à la requête, et renvoyer la liste de documents répondant à la requête en tant que résultat de recherche pour la requête.
2. Système selon la revendication 1, dans lequel le document cible n'a pas encore été exploré.
3. Système selon la revendication 1, dans lequel le lien sortant est une balise d'ancrage dans le document source et l'annotation est un texte d'ancrage associé à la balise d'ancrage.
4. Système selon la revendication 1, comprenant en outre une carte d'ancrage accessible par un indexeur, la carte d'ancrage comprenant au moins une entrée qui identifie : un document cible respectif ; une pluralité d'identifiants de document source, le document source comprenant un lien sortant vers le document cible respectif ; et au moins une annotation pour chaque identifiant de document source, l'annotation comprend un passage de texte extrait d'un document source respectif, le passage de texte se trouvant à une distance prédéterminée d'un lien sortant respectif .
5. Système selon la revendication 4, la carte d'ancrage identifiant en outre un attribut d'au moins une annotation.
6. Système selon la revendication 1, dans lequel l'annotation est un bloc de texte continu du document source.
7. Système selon la revendication 1, dans lequel l'annotation comprend du texte en dehors d'une balise d'ancrage dans le document source.
8. Système selon la revendication 1, la mémoire stockant en outre des instructions qui, lorsqu'elles sont exécutées par le au moins un processeur, effectuent des opérations comprenant : le calcul d'une métrique de pertinence indépendante de la requête pour le document cible, dans lequel la métrique de pertinence indépendante de la requête comprend une somme des contributions partielles de métriques de pertinence indépendantes de la requête de chaque document source qui inclut un lien sortant vers le document cible.

La plus ancienne version de ce brevet d'indexation de texte d'ancrage
J'ai écrit à propos de la première version du brevet de texte d'ancrage en 2007 dans le post Google Patent on Anchor Text and Different Crawling Rates. C'était très instructif sur la façon dont Google a exploré les pages Web et les a indexées à différents taux, et a géré les redirections de différents types.
La dernière version du brevet comprend un processus mis à jour dont je n'ai pas parlé dans cette version précédente, dans le message que j'ai écrit il y a 12 ans.
Puisque j'ai inclus certaines des revendications mentionnant le texte d'association près du texte d'ancrage, je devrais vous montrer les revendications de la version la plus ancienne du brevet, Anchor Text Indexing in a Web Crawler System (déposé le 3 juillet 2003). Voici les 8 premières revendications de cette version du brevet (comparez-les aux 8 ci-dessus de la version la plus récente) :
Ce qui est revendiqué est:
1. Procédé de traitement d'informations relatives à des documents dans une collection de documents liés, le procédé comprenant : l'accès à un journal de liens, le journal de liens qui comprend une pluralité d'enregistrements de liens, chaque enregistrement de liens identifiant un document source et une liste d'un ou plusieurs documents cibles pointés par un ou plusieurs liens sortants dans le document source ; l'enregistrement de lien comprenant un identifiant de document source pour le document source identifié et un ou plusieurs identifiants de document cible pour la liste identifiée de documents cibles ; dans lequel les enregistrements de liens sont basés, au moins en partie, sur des informations extraites de documents explorés dans la collection de documents liés ; et la sortie d'une carte d'ancrage triée qui correspond au journal de liens et qui comprend une pluralité d'enregistrements d'ancrage, chaque enregistrement d'ancrage identifiant un document cible respectif et une liste de liens entrants, la liste de liens entrants identifiant des documents source qui contiennent des liens vers le document cible; l'enregistrement d'ancrage comprenant un identifiant de document cible respectif ; dans lequel la pluralité d'enregistrements d'ancrage est ordonnée dans la carte d'ancrage triée sur la base, au moins en partie, de leurs identifiants de document cible respectifs ; et dans lequel chaque identifiant de document cible respectif dans la pluralité d'enregistrements d'ancrage correspond à l'un des un ou plusieurs identifiants de document cible dans le journal de liens.
2. Procédé selon la revendication 1, dans lequel chaque enregistrement d'ancrage dans la carte d'ancrage triée comprend en outre une liste respective d'annotations.
3. Procédé selon la revendication 2, dans lequel chaque annotation incluse dans la liste respective d'annotations pour un enregistrement d'ancrage respectif correspond à un lien entrant respectif identifiant un document source respectif qui contient un lien vers le document cible respectif.
4. Procédé selon la revendication 2, dans lequel au moins une entrée dans la liste respective d'annotations d'un enregistrement d'ancrage dans la carte d'ancrage triée comprend un passage de texte et une liste d'attributs du passage de texte.
5. Procédé selon la revendication 4, dans lequel le passage de texte est déterminé à partir du texte à une distance prédéterminée d'une balise d'ancrage dans un document source respectif dans les documents sources de l'enregistrement d'ancrage.
6. Procédé selon la revendication 1, comprenant en outre la répétition de l'accès et de la sortie pour produire un ensemble en couches de cartes d'ancrage triées.
7. Procédé selon la revendication 6, comprenant en outre, lorsqu'une condition de fusion a été satisfaite, la fusion d'un sous-ensemble de l'ensemble en couches de cartes d'ancrage triées pour produire une carte d'ancrage fusionnée ; dans lequel la carte d'ancrage fusionnée comprend une pluralité d'enregistrements d'ancrage fusionnés, chaque enregistrement d'ancrage fusionné correspondant à au moins un enregistrement d'ancrage du sous-ensemble de l'ensemble en couches de cartes d'ancrage triées, dans lequel les enregistrements d'ancrage fusionnés sont classés dans la carte d'ancrage fusionnée sur la base leurs identifiants de documents cibles respectifs.
8. Procédé selon la revendication 1, comprenant en outre la sortie d'une carte de liens triée, la carte de liens triés comprenant une pluralité d'enregistrements de carte de liens, chaque enregistrement de carte de liens comprenant l'identifiant de document source et la liste d'identifiants de document cible dans un enregistrement de lien associé.
introduction du texte d'annotation à l'indexation du texte d'ancrage
Notez les mentions de texte d'annotation dans les nouvelles revendications de ce brevet. Considérant que le brevet a été mis à jour pour refléter le processus que le brevet est destiné à protéger et à exclure d'autres moteurs de recherche, cela rend l'idée d'ajouter un texte d'annotation près du texte d'ancrage très intéressante pour moi. Le brevet ne fournit pas de feuille de route exacte sur la façon d'utiliser le texte d'annotation avec des liens, mais fournit suffisamment d'informations pour le rendre intéressant et mérite d'être expérimenté.
Et l'ajout d'un guide de style que les créateurs de contenu peuvent utiliser lorsqu'ils créent du contenu contenant des liens vers d'autres pages qu'ils peuvent souhaiter classer pour les termes inclus dans ce texte d'annotation.
Le référencement peut évoluer vers un processus plus sémantique impliquant Schema et des panneaux de connaissances, mais nous voyons également des mises à jour sur la façon dont les éléments initialement déposés dans les brevets en 2003, comme l'utilisation du texte d'ancrage, peuvent également être mis à jour.
Bon lien avec toi.