
Добавьте в свое руководство по стилю текст аннотации: индексирование текста привязки
Опубликовано: 2019-02-22Руководство по стилю
Одна вещь, с которой я сталкивался и рекомендовала в прошлом, - это использование руководства по стилю. Впервые я услышал об этой концепции в университете, для которого занимался поисковой оптимизацией. Декану школы не нравилась одна фраза, и он настаивал на другой, которая была одной из наших основных фраз для сайта. Хорошо иметь место для отслеживания подобных предпочтений и других подходов, которые могут применяться к сайту. Я рекомендовал руководство по стилю для сайтов, рекомендующее такие вещи, как будущее использование всех строчных букв в URL-адресах сайтов. Go Fish Digital не имеет руководства по стилю, но у него есть вики, где мы включаем информацию о конкретных методах, которые мы используем на нашем сайте, а также на сайтах клиентов.
Индексирование текста привязки обновлено в Google
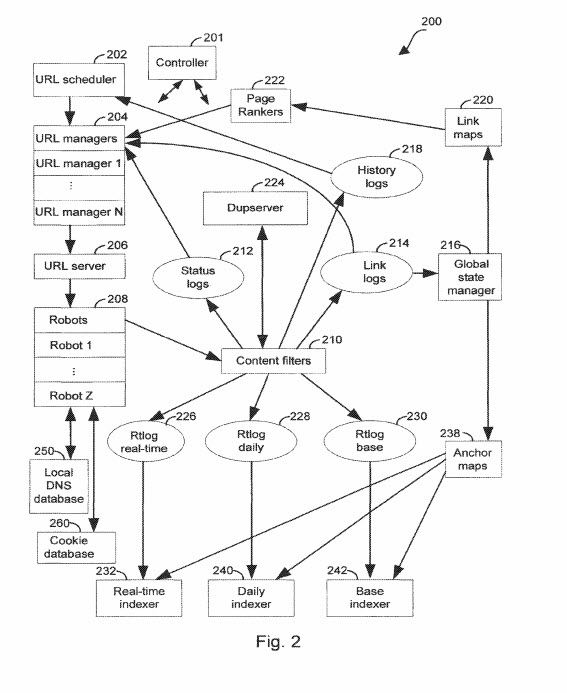
Я добавил несколько вещей в нашу вики, и есть еще пара вещей, которые нужно добавить к ней. Последним дополнением будет то, что я увидел в продолжающемся патенте, который только что вышел, обновляя патент Google, который был первоначально подан поисковой системой в 2003 году (о котором я писал первоначально в 2007 году, когда он был выдан впервые). аспект SEO, знакомый большинству людей, занимающихся поисковой оптимизацией, об использовании индексации якорного текста. Я слышал слухи, что Google использовал этот новый подход в прошлом, но до недавнего времени не видел ничего об этом в письменной форме в разделе формулы изобретения этого нового патента. Речь идет о патенте, который принадлежит изобретателю Джеффу Дину, главе команды Google Brain Team. Он также является одним из изобретателей патента Reasonable Surfer Patent, который уделяет больше внимания вероятности того, что кто-то может щелкнуть ссылку, чтобы использовать ее для определения веса PageRank.
Последнюю версию этого обновленного патента на индексирование якорного текста можно найти здесь:
Индексирование тегов привязки в системе поискового робота
Изобретатели: Хуйкан Чжу, Джеффри Дин, Санджай Гемават, Бволен По-Джен Ян и Анураг Ачарья.
Цессионарий: GOOGLE LLC
Патент США: 10,210,256.
Выдано: 19 февраля 2019 г.
Подана: 1 апреля 2016 г.
Абстрактный
Предоставляется метод и система для индексации документов в наборе связанных документов. Доступ к журналу ссылок, включающему одну или несколько пар исходных документов и целевых документов. Создается отсортированная карта привязки, содержащая один или несколько пар целевого документа и исходного документа. Пары в отсортированной карте привязок упорядочены на основе идентификаторов целевого документа.
Текст аннотации рядом с текстом привязки Новое в этом патенте
Одним из примечательных нововведений в формуле изобретения в этом дополнительном патенте является упоминание текста аннотации на определенном расстоянии от текста привязки для ссылки, который может повлиять на то, на что может быть сделана ссылка на страницу. Я включу некоторые из этих новых пунктов формулы в последнюю версию этого патента, которые относятся к тексту аннотации:
Заявлено следующее:
1. Система, содержащая: по меньшей мере, один процессор; указатель для поиска документов, указатель включает термины, связанные с документами; и хранящие в памяти инструкции, которые при выполнении по меньшей мере одним процессором выполняют операции, включая получение через веб-сканер исходного документа, идентификацию в исходном документе текста аннотации, причем текст аннотации является текстом в пределах заранее определенного расстояния исходящая ссылка на целевой документ и текст аннотации, включающий как минимум один термин, сохранение в указателе связи между термином и исходным документом, сохранение в указателе, реагирование на идентификацию текста аннотации, связь между термином и целевым документом документ, идентифицирующий, реагирующий на получение запроса, который включает термин, исходный документ и целевой документ, связанный с термином в указателе , реагирующий на идентификацию ассоциаций, включая исходный документ и целевой документ в списке документов, отвечающих на запрос и возвращение списка документов, отвечающих на запрос, в качестве результата поиска по запросу.
2. Система по п.1, в которой целевой документ еще не просматривался.
3. Система по п.1, в которой исходящая ссылка является тегом привязки в исходном документе, а аннотация представляет собой текст привязки, связанный с тегом привязки.
4. Система по п.1, дополнительно содержащая карту привязки, к которой обращается индексатор, причем карта привязки включает в себя по меньшей мере одну запись, которая идентифицирует: соответствующий целевой документ; множество идентификаторов исходного документа, при этом исходный документ включает в себя исходящую ссылку на соответствующий целевой документ; и по меньшей мере одну аннотацию для каждого идентификатора исходного документа, при этом аннотация включает в себя текстовый отрывок, извлеченный из соответствующего исходного документа, причем текстовый отрывок находится в пределах заранее определенного расстояния от соответствующей исходящей ссылки .
5. Система по п.4, в которой карта привязки дополнительно идентифицирует атрибут по меньшей мере одной аннотации.
6. Система по п.1, в которой аннотация представляет собой непрерывный блок текста из исходного документа.
7. Система по п.1, в которой аннотация включает текст вне тега привязки в исходном документе.
8. Система по п.1, в которой в памяти дополнительно хранятся инструкции, которые при выполнении по меньшей мере одним процессором выполняют операции, в том числе: вычисление не зависящей от запроса метрики релевантности для целевого документа, при этом не зависящая от запроса метрика релевантности включает в себя сумму вкладов в метрики релевантности, не зависящие от запроса, из каждого исходного документа, который включает исходящую ссылку на целевой документ.

Самая старая версия этого патента на индексирование якорного текста
Я писал о самой ранней версии патента на анкорный текст еще в 2007 году в статье Google Patent on Anchor Text and Different Rate Crawling. Это было очень информативно о том, как Google сканирует веб-страницы и индексирует их с разной скоростью, а также обрабатывает перенаправления разных типов.
Последняя версия патента включает обновленный процесс, о котором я не писал в той более ранней версии, в сообщении, которое я написал 12 лет назад.
Поскольку я включил некоторые пункты формулы изобретения, в которых упоминается текст ассоциации рядом с текстом привязки, я должен показать вам формулу изобретения из самой старой версии патента, «Индексирование текста привязки в системе веб-сканера» (подана 3 июля 2003 г.). Вот первые 8 пунктов формулы из этой версии патента (сравните их с 8 пунктами последней версии):
Заявлено следующее:
1. Способ обработки информации, относящейся к документам в коллекции связанных документов, включающий: доступ к журналу ссылок, журналу ссылок, который содержит множество записей ссылок, каждая запись ссылки идентифицирует исходный документ и список из одного или несколько целевых документов, на которые указывают одна или несколько исходящих ссылок в исходном документе; запись ссылки, включающая в себя идентификатор исходного документа для идентифицированного исходного документа и один или несколько идентификаторов целевого документа для идентифицированного списка целевых документов; при этом записи ссылок основаны, по меньшей мере частично, на информации, извлеченной из просматриваемых документов в коллекции связанных документов; и вывод отсортированной карты привязки, которая соответствует журналу ссылок и содержит множество записей привязки, каждая запись привязки идентифицирует соответствующий целевой документ и список входящих ссылок, список входящих ссылок идентифицирует исходные документы, которые содержат ссылки на соответствующие целевой документ; запись привязки, включающая в себя соответствующий идентификатор целевого документа; при этом множество записей привязки упорядочено в отсортированной карте привязки на основе, по меньшей мере частично, их соответствующих идентификаторов целевого документа; и при этом каждый соответствующий идентификатор целевого документа во множестве записей привязки соответствует одному из одного или нескольких идентификаторов целевого документа в журнале ссылок.
2. Способ по п.1, в котором каждая запись привязки в отсортированной карте привязки дополнительно содержит соответствующий список аннотаций.
3. Способ по п.2, в котором каждая аннотация, включенная в соответствующий список аннотаций для соответствующей записи привязки, соответствует соответствующей входящей ссылке, идентифицирующей соответствующий исходный документ, который содержит ссылку на соответствующий целевой документ.
4. Способ по п.2, в котором по меньшей мере одна запись в соответствующем списке аннотаций записи привязки в отсортированной карте привязки включает в себя текстовый фрагмент и список атрибутов текстового фрагмента.
5. Способ по п.4, в котором отрывок текста определяется из текста в пределах заранее определенного расстояния от тега привязки в соответствующем исходном документе в исходных документах записи привязки.
6. Способ по п.1, дополнительно включающий в себя повторение доступа и вывода для создания многоуровневого набора отсортированных карт привязки.
7. Способ по п.6, дополнительно включающий в себя, когда условие слияния удовлетворено, слияние подмножества многоуровневого набора отсортированных карт привязки для создания объединенной карты привязки; при этом объединенная карта привязки включает в себя множество объединенных записей привязки, каждая объединенная запись привязки соответствует по меньшей мере одной записи привязки из подмножества многоуровневого набора отсортированных карт привязки, при этом объединенные записи привязки упорядочиваются в объединенной карте привязки на основе их соответствующие идентификаторы целевого документа.
8. Способ по п.1, дополнительно включающий вывод отсортированной карты ссылок, причем отсортированная карта ссылок содержит множество записей карты ссылок, каждая запись карты ссылок содержит идентификатор исходного документа и список идентификаторов целевого документа в связанной записи ссылки.
Введение текста аннотации в индексирование текста привязки
Обратите внимание на упоминания текста аннотации в новой формуле изобретения этого патента. Учитывая, что патент был обновлен, чтобы отразить процесс, который патент предназначен для защиты, и исключить использование других поисковых систем, это делает идею добавления текста аннотации рядом с текстом привязки очень интересной для меня. Патент не дает точного плана действий по использованию текста аннотации со ссылками, но предоставляет достаточно информации, чтобы сделать его интересным, как то, с чем стоит поэкспериментировать.
И добавление к руководству по стилю, которое создатели контента должны рассмотреть при создании контента, содержащего ссылки на другие страницы, которые они, возможно, захотят ранжировать по терминам, включенным в этот текст аннотации.
SEO может развиваться в сторону более семантического процесса, включающего схемы и панели знаний, но мы также видим обновления того, как вещи, первоначально заявленные в патенты еще в 2003 году, например, использование якорного текста, также могут быть обновлены.
Хорошая ссылка на вас.