
添加到您的样式指南注释文本:锚文本索引
已发表: 2019-02-22运行风格指南
我在过去遇到并推荐的一件事是使用样式指南。 我第一次听到我在做 SEO 的大学的概念。 学院院长不喜欢一个词组并坚持使用另一个词组,这是我们网站的主要关键词词组之一。 最好有一个地方来跟踪类似的偏好,以及可能适用于网站的其他方法。 我已经为网站推荐了一份风格指南,推荐诸如将来在网站的 URL 中使用所有小写字母之类的内容。 Go Fish Digital 没有风格指南,但它有一个 wiki,其中包含有关我们在我们的站点和客户站点上使用的特定技术的信息。
Google 更新了锚文本索引
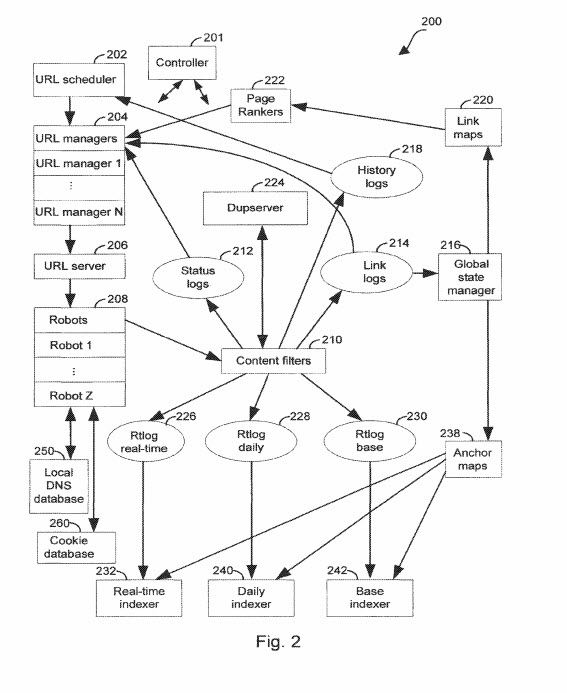
我已经在我们的 wiki 中添加了一些东西,还有一些东西要添加到它。 最新添加的内容将是我在刚刚发布的延续专利中看到的内容,更新了最初由搜索引擎于 2003 年提交的 Google 专利(我最初在 2007 年首次获得授权时撰写了该专利)。它涉及大多数做 SEO 的人都熟悉的 SEO 的一个方面,关于锚文本索引的使用。 我听说谷歌过去曾使用过这种新方法,但直到最近,在这项新专利的权利要求部分,我才看到有关它的任何书面信息。 有问题的专利是谷歌大脑团队负责人杰夫·迪恩的发明者。 他也是 Reasonable Surfer 专利的发明者之一,该专利更关注某人可能点击链接的概率,用于确定 PageRank 权重
可以在此处找到有关锚文本索引的此更新专利的最新版本:
网络爬虫系统中的锚标记索引
发明人:Huican Zhu、Jeffrey Dean、Sanjay Ghemawat、Bwolen Po-Jen Yang 和 Anurag Acharya
受让人:GOOGLE LLC
美国专利:10,210,256
授予时间:2019 年 2 月 19 日
提交时间:2016 年 4 月 1 日
抽象的
提供了一种用于索引链接文档集合中的文档的方法和系统。 访问包括一对或多对源文档和目标文档的链接日志。 生成包含一个或多个目标文档到源文档配对的排序锚映射。 排序后的锚映射中的配对基于目标文档标识符进行排序。
锚文本附近的注释文本 本专利的新内容
在此继续专利的权利要求中,一个值得注意的新内容是在与链接的锚文本一定距离内提到了注释文本,这可能会影响被链接到的页面可能是关于什么的。 我将在本专利的最新版本中包含其中一些引用注释文本的新声明:
主张的是:
1. 一种系统,包括: 至少一个处理器; 用于搜索文档的索引,该索引包括与文档相关的术语; 存储器存储指令,当被所述至少一个处理器执行时,执行的操作包括:通过网络爬虫获取源文档,在源文档中识别注释文本,注释文本是在预定距离内的文本。到目标文档和注释文本的出站链接,包括至少一个术语,在索引中存储术语和源文档之间的关联,存储在索引中,响应于识别注释文本,术语和目标之间的关联文档,识别,响应于接收包括与索引中的术语相关联的术语、源文档和目标文档的查询,响应于识别关联,包括响应文档列表中的源文档和目标文档到查询,并返回响应查询的文档列表作为查询的搜索结果。
2.如权利要求1所述的系统,其中所述目标文档尚未被爬行。
3.如权利要求1所述的系统,其特征在于,所述出站链接是所述源文档中的锚标签,并且所述注释是与所述锚标签相关联的锚文本。
4.如权利要求1所述的系统,还包括由索引器访问的锚图,所述锚图包括至少一个标识:相应目标文档; 多个源文件标识符,其中源文件包括到相应目标文件的出站链接; 以及针对每个源文档标识符的至少一个注释,该注释包括从相应的源文档中提取的文本段落,其中该文本段落在相应的出站链接的预定距离内。
5.如权利要求4所述的系统,所述锚图进一步识别至少一个注释的属性。
6.如权利要求1所述的系统,其特征在于,所述注释是来自源文档的连续文本块。
7.如权利要求1所述的系统,其特征在于,所述注释包括在所述源文档中的锚标记之外的文本。
8.如权利要求1所述的系统,所述存储器还存储指令,所述指令在由所述至少一个处理器执行时执行包括: 计算所述目标文档的与查询无关的相关性度量,其中所述与查询无关的相关性度量包括总和来自每个源文档的部分与查询无关的相关性度量贡献,其中包括到目标文档的出站链接。

此锚文本索引专利的最旧版本
早在 2007 年,我就在关于锚文本和不同爬网率的谷歌专利一文中写到了最早版本的锚文本专利。 关于谷歌如何抓取网页并以不同的速率将它们编入索引,以及处理不同类型的重定向,它提供了非常丰富的信息。
最新版本的专利包括一个更新的过程,我在 12 年前写的帖子中没有在早期版本中写过。
由于我在锚文本附近包含了一些提及关联文本的权利要求,因此我应该向您展示来自该专利最旧版本的权利要求,即 Web 爬虫系统中的锚文本索引(2003 年 7 月 3 日提交)。 以下是该版本专利的前 8 项权利要求(将这些与最新版本的上述 8 项进行比较):
主张的是:
1.一种处理与链接文档集合中的文档相关的信息的方法,该方法包括:访问链接日志,该链接日志包括多个链接记录,每个链接记录标识一个源文档和一个或多个链接记录的列表。源文档中的一个或多个出站链接指向的更多目标文档; 链接记录包括所识别的源文档的源文档标识符和所识别的目标文档列表的一个或多个目标文档标识符; 其中链接记录至少部分基于从链接文档集合中的爬行文档中提取的信息; 并且输出对应于链接日志并且包括多个锚记录的排序锚映射,每个锚记录标识各自的目标文档和入站链接列表,入站链接列表标识包含到各自的链接的源文档目标文件; 锚记录包括各自的目标文档标识符; 其中,至少部分地基于它们各自的目标文档标识符在排序的锚映射中对多个锚记录进行排序; 并且其中多个锚定记录中的每个各自的目标文档标识符对应于链接日志中的一个或多个目标文档标识符之一。
2.如权利要求1所述的方法,其特征在于,排序后的锚图中的每个锚记录还包括相应的注释列表。
3.如权利要求2所述的方法,其中包括在用于相应锚记录的相应注释列表中的每个注释对应于标识相应源文档的相应入站链接,该源文档包含到相应目标文档的链接。
4.如权利要求2所述的方法,其特征在于,所述排序锚图中的锚记录的相应注释列表中的至少一个条目包括文本段落和所述文本段落的属性列表。
5.如权利要求4所述的方法,其特征在于,所述文本段落是根据所述锚记录的源文档中的相应源文档中的锚标记预定距离内的文本确定的。
6.如权利要求1所述的方法,还包括重复访问和输出以产生分层的一组已排序锚图。
7.如权利要求6所述的方法,还包括,当已经满足合并条件时,合并所述分层的已排序锚图集合的子集以产生合并的锚图; 其中合并的锚图包括多个合并的锚记录,每个合并的锚记录对应于来自分层的已排序锚图集合的子集中的至少一个锚记录,其中合并的锚记录在合并的锚图中基于以下排序:它们各自的目标文档标识符。
8.如权利要求1所述的方法,还包括输出排序的链接图,所述排序的链接图包括多个链接图记录,每个链接图记录包括相关联的链接记录中的源文档标识符和目标文档标识符的列表。
将注释文本引入锚文本索引
请注意该专利的新权利要求中对注释文本的提及。 考虑到更新专利以反映该专利旨在保护的过程,并排除其他搜索引擎使用,这使得在锚文本附近添加注释文本的想法对我来说非常有趣。 该专利没有提供关于如何使用带有链接的注释文本的确切路线图,但确实提供了足够的信息,使其成为值得尝试的有趣内容。
并添加到样式指南中,供内容创建者在创建包含指向其他页面的链接的内容时考虑使用,他们可能希望对包含在该注释文本中的术语进行排名。
SEO 可能正在朝着涉及 Schema 和知识面板的更多语义过程发展,但我们也看到了最初在 2003 年提交专利的内容的更新,例如锚文本的使用也可能会更新。
很好的链接到你。