
ربما يكون أفضل بديل لتخزين CSV: بيانات الباركيه
نشرت: 2021-11-25يوفر Apache Parquet العديد من الفوائد لتخزين البيانات واسترجاعها عند مقارنتها بالطرق التقليدية مثل CSV.
تم تصميم تنسيق الباركيه لمعالجة البيانات بشكل أسرع للأنواع المعقدة. في هذه المقالة ، نتحدث عن كيف أن تنسيق الباركيه مناسب لاحتياجات البيانات المتزايدة اليوم.
قبل أن نتعمق في تفاصيل تنسيق Parquet ، دعونا نفهم ماهية بيانات CSV والتحديات التي تطرحها لتخزين البيانات.
ما هو تخزين CSV؟
لقد سمعنا جميعًا كثيرًا عن CSV ( C omma S eparated V alues) - إحدى أكثر الطرق شيوعًا لتنظيم البيانات وتنسيقها. تخزين بيانات CSV يعتمد على الصفوف. يتم تخزين ملفات CSV بامتداد .csv. يمكننا تخزين بيانات CSV وفتحها باستخدام Excel أو Google Sheets أو أي محرر نصوص. البيانات غير قابل للعرض بسهولة بمجرد فتح الملف.
حسنًا ، هذا ليس جيدًا - بالتأكيد ليس لتنسيق قاعدة البيانات.
علاوة على ذلك ، مع نمو حجم البيانات ، يصبح من الصعب الاستعلام والإدارة والاسترداد.
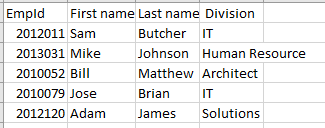
فيما يلي مثال على البيانات المخزنة في ملف .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutionsإذا عرضناه في Excel ، فيمكننا رؤية هيكل عمود الصف على النحو التالي:
التحديات مع تخزين CSV
تعد المستودعات القائمة على الصفوف مثل CSV مناسبة لعمليات التخزين C و U و D elete.
ماذا عن R ead في CRUD ، إذن؟
تخيل مليون صف في ملف .csv أعلاه. سيستغرق فتح الملف والبحث عن البيانات التي تبحث عنها وقتًا معقولاً. ليس رائعًا. يقوم معظم مزودي الخدمات السحابية مثل AWS بشحن الشركات بناءً على كمية البيانات التي تم مسحها ضوئيًا أو تخزينها - مرة أخرى ، تستهلك ملفات CSV مساحة كبيرة.
لا يحتوي تخزين CSV على خيار حصري لتخزين البيانات الوصفية ، مما يجعل فحص البيانات مهمة شاقة.
إذن ، ما هو الحل الأمثل والفعال من حيث التكلفة لأداء جميع عمليات CRUD؟ دعونا نستكشف.
ما هو تخزين بيانات الباركيه؟
الباركيه هو تنسيق تخزين مفتوح المصدر لتخزين البيانات. يستخدم على نطاق واسع في النظم البيئية Hadoop و Spark. يتم تخزين ملفات الباركيه على هيئة امتداد باركيه.
الباركيه هو شكل منظم للغاية. يمكن استخدامه أيضًا لتحسين البيانات الأولية المعقدة الموجودة بكميات كبيرة في بحيرات البيانات. هذا يمكن أن يقلل بشكل كبير من وقت الاستعلام.
يجعل الباركيه تخزين البيانات أكثر كفاءة واسترجاعًا أسرع بسبب مزيج من تنسيقات التخزين (المختلطة) القائمة على الصفوف والعمودية. في هذا التنسيق ، يتم تقسيم البيانات أفقيًا وعموديًا. يزيل تنسيق الباركيه أيضًا التحليل الزائد إلى حد كبير.
يقيد التنسيق العدد الإجمالي لعمليات الإدخال / الإخراج ، وفي النهاية التكلفة.
يقوم باركيه أيضًا بتخزين البيانات الوصفية ، التي تخزن معلومات حول البيانات مثل مخطط البيانات ، وعدد القيم ، وموقع الأعمدة ، والحد الأدنى للقيمة ، والحد الأقصى لعدد مجموعات الصفوف ، ونوع الترميز ، وما إلى ذلك. يتم تخزين البيانات الوصفية على مستويات مختلفة في الملف ، مما يجعل الوصول إلى البيانات أسرع.
في الوصول المستند إلى الصف مثل CSV ، يستغرق استرداد البيانات وقتًا حيث يتعين على الاستعلام التنقل عبر كل صف والحصول على قيم العمود المحددة. مع تخزين الباركيه ، يمكن الوصول إلى جميع الأعمدة المطلوبة في وقت واحد.
باختصار،
- يعتمد الباركيه على الهيكل العمودي لتخزين البيانات
- إنه تنسيق بيانات محسن لتخزين البيانات المعقدة بكميات كبيرة في أنظمة التخزين
- يتضمن تنسيق الباركيه طرقًا مختلفة لضغط البيانات وتشفيرها
- إنه يقلل بشكل كبير من وقت مسح البيانات ووقت الاستعلام ويستهلك مساحة أقل على القرص مقارنة بتنسيقات التخزين الأخرى مثل CSV
- يقلل من عدد عمليات الإدخال / الإخراج ، ويقلل من تكلفة التخزين وتنفيذ الاستعلام
- يتضمن البيانات الوصفية التي تسهل العثور على البيانات
- يوفر دعم مفتوح المصدر
تنسيق بيانات الباركيه
قبل الخوض في مثال ، دعنا نفهم كيفية تخزين البيانات بتنسيق Parquet بمزيد من التفصيل:

يمكن أن يكون لدينا أقسام أفقية متعددة تعرف باسم مجموعات الصفوف في ملف واحد. داخل كل مجموعة صف ، يتم تطبيق التقسيم الرأسي. يتم تقسيم الأعمدة إلى عدة أجزاء من الأعمدة. يتم تخزين البيانات كصفحات داخل أجزاء العمود. تحتوي كل صفحة على قيم البيانات وبيانات التعريف المشفرة. كما ذكرنا سابقًا ، يتم أيضًا تخزين البيانات الأولية للملف بأكمله في تذييل الملف على مستوى مجموعة الصف.
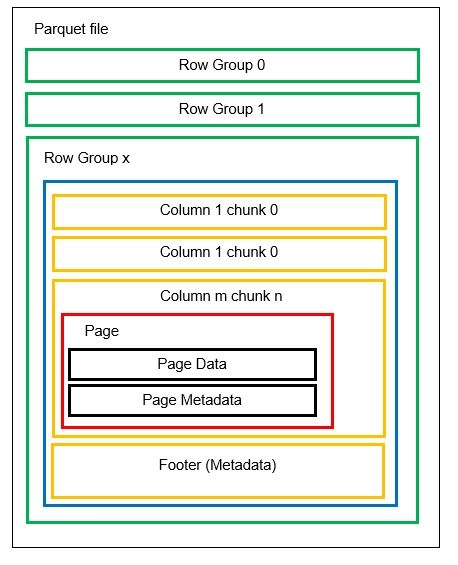
نظرًا لأن البيانات مقسمة إلى أجزاء أعمدة ، فإن إضافة بيانات جديدة عن طريق ترميز القيم الجديدة في قطعة وملف جديد أمر سهل أيضًا. يتم بعد ذلك تحديث البيانات الوصفية للملفات ومجموعات الصفوف المتأثرة. وبالتالي ، يمكننا القول أن الباركيه هو تنسيق مرن.
يدعم الباركيه في الأصل ضغط البيانات باستخدام تقنيات ضغط الصفحات وترميز القاموس. لنرى مثالاً بسيطًا لضغط القاموس:
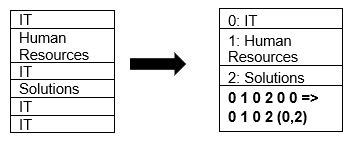
لاحظ أنه في المثال أعلاه ، نرى قسم تكنولوجيا المعلومات 4 مرات. لذلك ، أثناء التخزين في القاموس ، يقوم التنسيق بترميز البيانات بقيمة أخرى سهلة التخزين (0،1،2 ...) إلى جانب عدد مرات تكرارها باستمرار - يتم تغيير تكنولوجيا المعلومات ، تكنولوجيا المعلومات إلى 0،2 للحفظ المزيد من المساحة. يستغرق الاستعلام عن البيانات المضغوطة وقتًا أقل.
مقارنة وجها لوجه
الآن بعد أن أصبح لدينا فكرة جيدة عن الشكل الذي تبدو عليه تنسيقات CSV و Parquet ، فقد حان الوقت لبعض الإحصائيات لمقارنة كلا التنسيقين:
| CSV | ارضية خشبية |
| تنسيق التخزين على أساس الصف. | مزيج من تنسيقات التخزين المستندة إلى الصفوف والأعمدة. |
| يستهلك مساحة كبيرة حيث لا يتوفر خيار ضغط افتراضي. على سبيل المثال ، سيشغل ملف 1 تيرابايت نفس المساحة عند تخزينه على Amazon S3 أو أي سحابة أخرى. | يضغط البيانات أثناء التخزين ، وبالتالي يستهلك مساحة أقل. سيشغل ملف 1 تيرابايت المخزن بتنسيق باركيه مساحة 130 جيجابايت فقط. |
| وقت تشغيل الاستعلام بطيء بسبب البحث المستند إلى الصفوف. لكل عمود ، يجب استرداد كل صف من البيانات. | وقت الاستعلام أسرع بنحو 34 مرة بسبب التخزين المستند إلى العمود ووجود البيانات الوصفية. |
| يجب فحص المزيد من البيانات لكل استعلام. | يتم فحص بيانات أقل بنسبة 99٪ تقريبًا لتنفيذ الاستعلام ، وبالتالي تحسين الأداء. |
| يتم شحن معظم أجهزة التخزين بناءً على مساحة التخزين ، لذا فإن تنسيق CSV يعني تكلفة تخزين عالية. | تكلفة تخزين أقل حيث يتم تخزين البيانات بتنسيق مضغوط ومشفّر. |
| يجب استنتاج مخطط الملف (مما يؤدي إلى حدوث أخطاء) أو توفيره (ممل). | يتم تخزين مخطط الملف في البيانات الوصفية. |
| التنسيق مناسب لأنواع البيانات البسيطة. | الباركيه مناسب حتى للأنواع المعقدة مثل المخططات المتداخلة والمصفوفات والقواميس. |
استنتاج
لقد رأينا من خلال الأمثلة أن الباركيه أكثر كفاءة من CSV من حيث التكلفة والمرونة والأداء. إنها آلية فعالة لتخزين واسترجاع البيانات ، خاصة عندما يتجه العالم بأسره نحو التخزين السحابي وتحسين المساحة. تدعم جميع الأنظمة الأساسية الرئيسية مثل Azure و AWS و BigQuery تنسيق الباركيه.