
Mungkin Alternatif Terbaik untuk Penyimpanan CSV: Data Parket
Diterbitkan: 2021-11-25Apache Parket memberikan beberapa manfaat untuk penyimpanan dan pengambilan data jika dibandingkan dengan metode tradisional seperti CSV.
Format parket dirancang untuk pemrosesan data yang lebih cepat dari jenis yang kompleks. Pada artikel ini, kita berbicara tentang bagaimana format Parket cocok untuk kebutuhan data yang terus berkembang saat ini.
Sebelum kita menggali detail format Parket, mari kita pahami apa itu data CSV dan tantangannya untuk penyimpanan data.
Apa itu penyimpanan CSV?
Kita semua telah banyak mendengar tentang CSV ( C omma S eparated V alues) – salah satu cara paling umum untuk mengatur dan memformat data. Penyimpanan data CSV berbasis baris. File CSV disimpan dengan ekstensi .csv. Kami dapat menyimpan dan membuka data CSV menggunakan Excel, Google Spreadsheet, atau editor teks apa pun. Data mudah dilihat setelah file dibuka.
Yah, itu tidak bagus – jelas bukan untuk format database.
Lebih lanjut, seiring dengan bertambahnya volume data, permintaan, pengelolaan, dan pengambilan kembali menjadi sulit.
Berikut adalah contoh data yang disimpan dalam file .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,SolutionsJika kita melihatnya di Excel, kita bisa melihat struktur baris-kolom seperti di bawah ini:
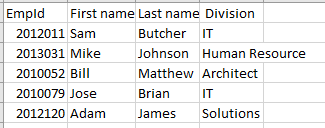
Tantangan dengan penyimpanan CSV
Penyimpanan berbasis baris seperti CSV cocok untuk operasi C reate, U pdate, dan D elete.
Bagaimana dengan benar menyebalkan R di CRUD, maka?
Bayangkan satu juta baris dalam file .csv di atas. Diperlukan waktu yang cukup lama untuk membuka file dan mencari data yang Anda cari. Tidak begitu keren. Sebagian besar penyedia cloud seperti AWS membebankan biaya kepada perusahaan berdasarkan jumlah data yang dipindai atau disimpan – sekali lagi, file CSV menghabiskan banyak ruang.
Penyimpanan CSV tidak memiliki opsi eksklusif untuk menyimpan metadata, membuat pemindaian data menjadi tugas yang membosankan.
Jadi, apa solusi hemat biaya dan optimal untuk melakukan semua operasi CRUD? Mari kita jelajahi.
Apa itu penyimpanan data Parket?
Parket adalah format penyimpanan sumber terbuka untuk menyimpan data. Ini banyak digunakan di ekosistem Hadoop dan Spark. File parket disimpan sebagai ekstensi .parquet.
Parket adalah format yang sangat terstruktur. Ini juga dapat digunakan untuk mengoptimalkan data mentah kompleks yang ada dalam jumlah besar di data lake. Ini dapat secara signifikan mengurangi waktu kueri.
Parket membuat penyimpanan data menjadi efisien dan pengambilan lebih cepat karena campuran format penyimpanan berbasis baris dan kolom (hibrida). Dalam format ini, data dipartisi secara horizontal maupun vertikal. Format parket juga menghilangkan sebagian besar overhead parsing.
Format ini membatasi jumlah keseluruhan operasi I/O dan, pada akhirnya, biaya.
Parket juga menyimpan metadata, yang menyimpan informasi tentang data seperti skema data, jumlah nilai, lokasi kolom, nilai minimum, jumlah nilai maksimum grup baris, jenis penyandian, dll. Metadata disimpan pada tingkat yang berbeda dalam file , membuat akses data lebih cepat.
Dalam akses berbasis baris seperti CSV, pengambilan data membutuhkan waktu karena kueri harus menavigasi setiap baris dan mendapatkan nilai kolom tertentu. Dengan penyimpanan Parket, semua kolom yang diperlukan dapat diakses sekaligus.
Kesimpulan,
- Parket didasarkan pada struktur kolom untuk penyimpanan data
- Ini adalah format data yang dioptimalkan untuk menyimpan data kompleks secara massal dalam sistem penyimpanan
- Format parket mencakup berbagai metode untuk kompresi dan penyandian data
- Ini secara signifikan mengurangi waktu pemindaian data dan waktu kueri dan membutuhkan lebih sedikit ruang disk dibandingkan dengan format penyimpanan lain seperti CSV
- Meminimalkan jumlah operasi IO, menurunkan biaya penyimpanan dan eksekusi kueri
- Termasuk metadata yang memudahkan untuk menemukan data
- Menyediakan dukungan sumber terbuka
Format data parket
Sebelum masuk ke contoh, mari kita pahami bagaimana data disimpan dalam format Parket secara lebih rinci:

Kita dapat memiliki beberapa partisi horizontal yang dikenal sebagai grup Baris dalam satu file. Dalam setiap grup Baris, partisi vertikal diterapkan. Kolom dibagi menjadi beberapa potongan kolom. Data disimpan sebagai halaman di dalam potongan kolom. Setiap halaman berisi nilai data dan metadata yang disandikan. Seperti yang kami sebutkan sebelumnya, metadata untuk seluruh file juga disimpan di footer file di tingkat grup Baris.
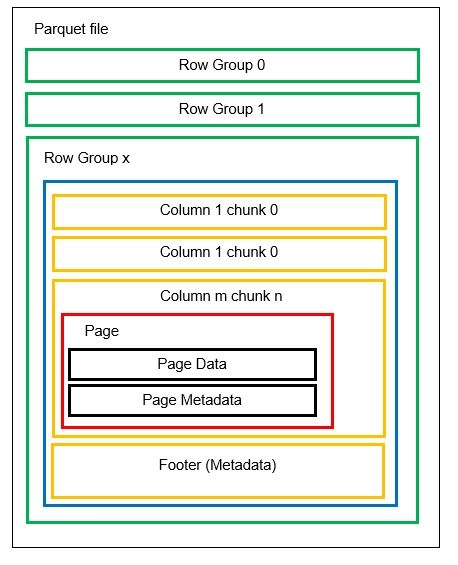
Karena data dipecah menjadi potongan kolom, menambahkan data baru dengan menyandikan nilai baru ke dalam potongan dan file baru juga mudah. Metadata kemudian diperbarui untuk file dan grup baris yang terpengaruh. Dengan demikian, kita dapat mengatakan bahwa Parket adalah format yang fleksibel.
Parket secara native mendukung kompresi data menggunakan kompresi halaman dan teknik pengkodean kamus. Mari kita lihat contoh sederhana kompresi kamus:
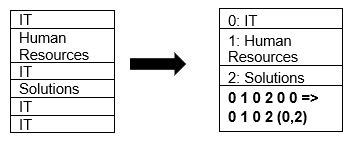
Perhatikan bahwa pada contoh di atas, kita melihat divisi IT sebanyak 4 kali. Jadi, saat menyimpan dalam kamus, format mengkodekan data dengan nilai lain yang mudah disimpan (0,1,2…) bersama dengan berapa kali diulang terus menerus – IT, IT diubah menjadi 0,2 untuk menyimpan lebih banyak ruang. Meminta data terkompresi membutuhkan waktu lebih sedikit.
Perbandingan head-to-head
Sekarang kita memiliki gambaran yang adil tentang bagaimana format CSV dan Parket terlihat, saatnya untuk beberapa statistik untuk membandingkan kedua format:
| CSV | Parket |
| Format penyimpanan berbasis baris. | Hibrida format penyimpanan berbasis baris dan berbasis kolom. |
| Ini menghabiskan banyak ruang karena tidak ada opsi kompresi default yang tersedia. Misalnya, file 1 TB akan menempati ruang yang sama saat disimpan di Amazon S3 atau cloud lainnya. | Mengompresi data saat menyimpan, sehingga memakan lebih sedikit ruang. File 1 TB yang disimpan dalam format Parket hanya akan memakan ruang 130GB. |
| Waktu proses kueri lambat karena pencarian berbasis baris. Untuk setiap kolom, setiap baris data harus diambil. | Waktu kueri sekitar 34 kali lebih cepat karena penyimpanan berbasis kolom dan keberadaan metadata. |
| Lebih banyak data harus dipindai per kueri. | Sekitar 99% lebih sedikit data yang dipindai untuk eksekusi kueri, sehingga mengoptimalkan kinerja. |
| Sebagian besar perangkat penyimpanan mengenakan biaya berdasarkan ruang penyimpanan, sehingga format CSV berarti biaya penyimpanan yang tinggi. | Lebih sedikit biaya penyimpanan karena data disimpan dalam format terkompresi dan dikodekan. |
| Skema file harus disimpulkan (menyebabkan kesalahan) atau disediakan (membosankan). | Skema file disimpan dalam metadata. |
| Format ini cocok untuk tipe data sederhana. | Parket cocok bahkan untuk tipe kompleks seperti skema bersarang, array, kamus. |
Kesimpulan
Kami telah melihat melalui contoh bahwa Parket lebih efisien daripada CSV dalam hal biaya, fleksibilitas, dan kinerja. Ini adalah mekanisme yang efektif untuk menyimpan dan mengambil data, terutama ketika seluruh dunia bergerak menuju penyimpanan cloud dan optimalisasi ruang. Semua platform utama seperti Azure, AWS, dan BigQuery mendukung format Parket.