
Вероятно, лучшая альтернатива CSV-хранилищу: паркетные данные
Опубликовано: 2021-11-25Apache Parquet предоставляет несколько преимуществ для хранения и извлечения данных по сравнению с традиционными методами, такими как CSV.
Формат паркета разработан для более быстрой обработки данных сложных типов. В этой статье мы поговорим о том, как формат Parquet подходит для сегодняшних постоянно растущих потребностей в данных.
Прежде чем мы углубимся в детали формата Parquet, давайте разберемся, что такое данные CSV и какие проблемы они создают для хранения данных.
Что такое хранилище CSV?
Все мы много слышали о CSV ( C omma S eparated V alues) - одном из наиболее распространенных способов организации и форматирования данных. Хранение данных CSV основано на строках. Файлы CSV хранятся с расширением .csv. Мы можем хранить и открывать данные CSV с помощью Excel, Google Таблиц или любого текстового редактора. Данные легко доступны для просмотра после открытия файла.
Что ж, это нехорошо - определенно не для формата базы данных.
Кроме того, по мере роста объема данных становится все труднее запрашивать, управлять и извлекать.
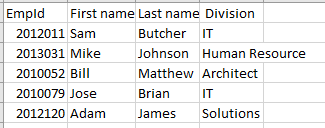
Вот пример данных, хранящихся в файле .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,SolutionsЕсли мы просмотрим его в Excel, мы можем увидеть структуру строка-столбец, как показано ниже:
Проблемы с хранилищем CSV
Хранилища на основе строк, такие как CSV, подходят для операций C reate, U pdate и D elete.
А как насчет R EAD в CRUD, то?
Представьте себе миллион строк в приведенном выше CSV-файле. Чтобы открыть файл и найти нужные данные, потребуется некоторое время. Не так уж и круто. Большинство облачных провайдеров, таких как AWS, взимают плату с компаний в зависимости от объема отсканированных или сохраненных данных - опять же, файлы CSV занимают много места.
В хранилище CSV нет эксклюзивной опции для хранения метаданных, что делает сканирование данных утомительной задачей.
Итак, какое экономичное и оптимальное решение для выполнения всех операций CRUD? Давайте изучим.
Что такое хранилище данных Parquet?
Parquet - это формат хранения данных с открытым исходным кодом. Он широко используется в экосистемах Hadoop и Spark. Файлы Parquet сохраняются с расширением .parquet.
Паркет - это сильно структурированный формат. Его также можно использовать для оптимизации сложных необработанных данных, массово присутствующих в озерах данных. Это может значительно сократить время запроса.
Parquet делает хранение данных эффективным и ускоряет поиск благодаря сочетанию строкового и столбцового (гибридного) форматов хранения. В этом формате данные разделяются как по горизонтали, так и по вертикали. Формат паркета также в значительной степени устраняет накладные расходы на синтаксический анализ.
Формат ограничивает общее количество операций ввода-вывода и, в конечном итоге, стоимость.
Parquet также хранит метаданные, в которых хранится информация о таких данных, как схема данных, количество значений, расположение столбцов, минимальное значение, максимальное значение, количество групп строк, тип кодирования и т. Д. Метаданные хранятся на разных уровнях в файле. , ускоряя доступ к данным.
В доступе на основе строк, таком как CSV, получение данных требует времени, поскольку запрос должен перемещаться по каждой строке и получать определенные значения столбца. С хранилищем паркета можно получить доступ сразу ко всем необходимым столбцам.
В итоге,
- Паркет основан на столбчатой структуре для хранения данных.
- Это оптимизированный формат данных для массового хранения сложных данных в системах хранения.
- Формат Parquet включает в себя различные методы сжатия и кодирования данных.
- Он значительно сокращает время сканирования данных и время запроса и занимает меньше места на диске по сравнению с другими форматами хранения, такими как CSV.
- Минимизирует количество операций ввода-вывода, снижая стоимость хранения и выполнения запросов.
- Включает метаданные, которые упрощают поиск данных
- Предоставляет поддержку с открытым исходным кодом
Формат данных паркета
Прежде чем переходить к примеру, давайте более подробно разберемся, как данные хранятся в формате Parquet:

В одном файле может быть несколько горизонтальных разделов, известных как группы строк. Внутри каждой группы строк применяется вертикальное разделение. Столбцы разделены на несколько частей. Данные хранятся в виде страниц внутри блоков столбцов. Каждая страница содержит закодированные значения данных и метаданные. Как мы упоминали ранее, метаданные для всего файла также хранятся в нижнем колонтитуле файла на уровне группы строк.
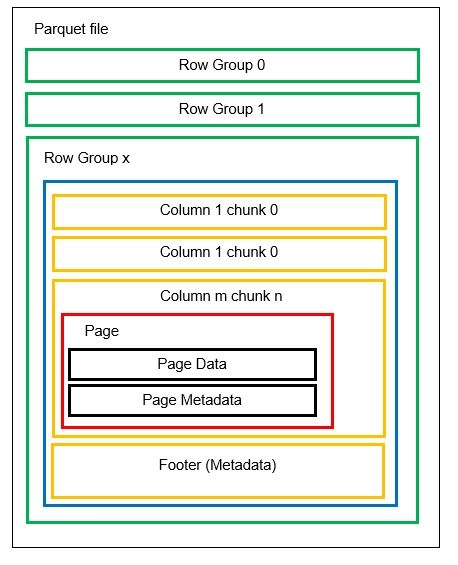
Поскольку данные разделены на блоки столбцов, также легко добавить новые данные путем кодирования новых значений в новый блок и файл. Затем обновляются метаданные для затронутых файлов и групп строк. Таким образом, можно сказать, что Parquet - это гибкий формат.
Parquet изначально поддерживает сжатие данных с использованием методов сжатия страниц и кодирования словаря. Давайте посмотрим на простой пример сжатия словаря:
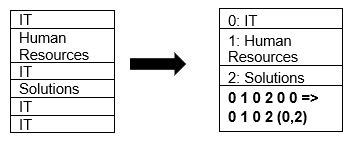
Обратите внимание, что в приведенном выше примере мы видим ИТ-подразделение 4 раза. Таким образом, при сохранении в словаре формат кодирует данные с помощью другого легко сохраняемого значения (0,1,2…) вместе с количеством раз, которое оно повторяется непрерывно - IT, IT изменено на 0,2 для сохранения больше пространства. Запрос сжатых данных занимает меньше времени.
Личное сравнение
Теперь, когда у нас есть четкое представление о том, как выглядят форматы CSV и Parquet, пришло время немного статистики для сравнения обоих форматов:
| CSV | Паркет |
| Формат хранения на основе строк. | Гибрид форматов хранения на основе строк и столбцов. |
| Он занимает много места, так как параметр сжатия по умолчанию недоступен. Например, файл размером 1 ТБ будет занимать то же место при хранении в Amazon S3 или любом другом облаке. | Сжимает данные во время хранения, занимая меньше места. Файл размером 1 ТБ, хранящийся в формате Parquet, займет всего 130 ГБ. |
| Время выполнения запроса медленное из-за поиска по строкам. Для каждого столбца необходимо получить каждую строку данных. | Время запроса примерно в 34 раза быстрее из-за хранения на основе столбцов и наличия метаданных. |
| Для каждого запроса необходимо сканировать больше данных. | При выполнении запроса сканируется примерно на 99% меньше данных, что оптимизирует производительность. |
| Стоимость большинства устройств хранения зависит от объема памяти, поэтому формат CSV означает высокую стоимость хранения. | Меньшая стоимость хранения, поскольку данные хранятся в сжатом закодированном формате. |
| Схема файла должна быть либо выведена (что приводит к ошибкам), либо предоставлена (утомительно). | Схема файла хранится в метаданных. |
| Формат подходит для простых типов данных. | Parquet подходит даже для сложных типов, таких как вложенные схемы, массивы, словари. |
Вывод
Мы убедились на примерах, что Parquet более эффективен, чем CSV, с точки зрения стоимости, гибкости и производительности. Это эффективный механизм для хранения и извлечения данных, особенно когда весь мир движется к облачному хранилищу и оптимизации пространства. Все основные платформы, такие как Azure, AWS и BigQuery, поддерживают формат Parquet.