
おそらくCSVストレージの最良の代替手段:寄木細工のデータ
公開: 2021-11-25Apache Parquetは、CSVのような従来の方法と比較した場合、データの保存と取得にいくつかの利点を提供します。
寄木細工の形式は、複雑なタイプのより高速なデータ処理のために設計されています。 この記事では、Parquet形式が今日の増え続けるデータニーズにどのように適しているかについて説明します。
Parquet形式の詳細を掘り下げる前に、CSVデータとは何か、およびCSVデータがデータストレージにもたらす課題について理解しましょう。
CSVストレージとは何ですか?
データを整理およびフォーマットする最も一般的な方法の1つであるCSV( C omma S eparated V alues)についてはよく耳にします。 CSVデータストレージは行ベースです。 CSVファイルは.csv拡張子で保存されます。 Excel、Googleスプレッドシート、または任意のテキストエディタを使用して、CSVデータを保存して開くことができます。 ファイルを開くと、データを簡単に表示できます。
まあ、それは良くありません–間違いなくデータベース形式ではありません。
さらに、データ量が増えると、クエリ、管理、および取得が困難になります。
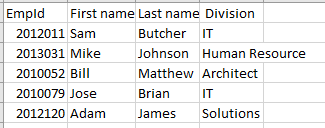
.CSVファイルに保存されているデータの例を次に示します。
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,SolutionsExcelで表示すると、次のような行と列の構造が表示されます。
CSVストレージの課題
CSVのような行ベースのストレージは、C reate、UのpdateおよびD elete操作に適しています。
何それから、CRUDのR EADは?
上記の.csvファイルの100万行を想像してみてください。 ファイルを開いて探しているデータを検索するには、かなりの時間がかかります。 それほどクールではありません。 AWSのようなほとんどのクラウドプロバイダーは、スキャンまたは保存されたデータの量に基づいて会社に課金します。繰り返しになりますが、CSVファイルは多くのスペースを消費します。
CSVストレージには、メタデータを保存するための排他的なオプションがないため、データスキャンが面倒な作業になります。
では、すべてのCRUD操作を実行するための費用効果が高く最適なソリューションは何でしょうか。 探検しましょう。
Parquetデータストレージとは何ですか?
Parquetは、データを保存するためのオープンソースのストレージ形式です。 これは、HadoopおよびSparkエコシステムで広く使用されています。 寄木細工のファイルは.parquet拡張子として保存されます。
寄木細工は高度に構造化された形式です。 また、データレイクに大量に存在する複雑な生データを最適化するためにも使用できます。 これにより、クエリ時間を大幅に短縮できます。
Parquetは、行ベースと列ベース(ハイブリッド)のストレージ形式が混在しているため、データストレージを効率的にし、取得を高速化します。 この形式では、データは水平方向と垂直方向に分割されます。 寄木細工の形式はまた、解析のオーバーヘッドを大幅に排除します。
この形式は、I / O操作の総数を制限し、最終的にはコストを制限します。
Parquetは、データスキーマ、値の数、列の位置、最小値、行グループの最大値の数、エンコーディングのタイプなどのデータに関する情報も格納するメタデータも格納します。メタデータは、ファイル内のさまざまなレベルで格納されます。 、データアクセスを高速化します。
CSVのような行ベースのアクセスでは、クエリが各行をナビゲートして特定の列の値を取得する必要があるため、データの取得には時間がかかります。 Parquetストレージを使用すると、必要なすべての列に一度にアクセスできます。
要約すれば、
- Parquetは、データストレージの柱状構造に基づいています
- 複雑なデータをストレージシステムにまとめて保存するために最適化されたデータ形式です
- 寄木細工の形式には、データの圧縮とエンコードのためのさまざまな方法が含まれています
- CSVなどの他のストレージ形式と比較して、データスキャン時間とクエリ時間を大幅に削減し、必要なディスク容量を削減します
- IO操作の数を最小限に抑え、ストレージとクエリの実行のコストを削減します
- データの検索を容易にするメタデータが含まれています
- オープンソースサポートを提供します
寄木細工のデータ形式
例に入る前に、データがParquet形式でどのように保存されるかをより詳細に理解しましょう。

1つのファイルに行グループと呼ばれる複数の水平パーティションを含めることができます。 各行グループ内で、垂直分割が適用されます。 列はいくつかの列チャンクに分割されます。 データは、列チャンク内のページとして保存されます。 各ページには、エンコードされたデータ値とメタデータが含まれています。 前述したように、ファイル全体のメタデータは、行グループレベルでファイルのフッターにも保存されます。
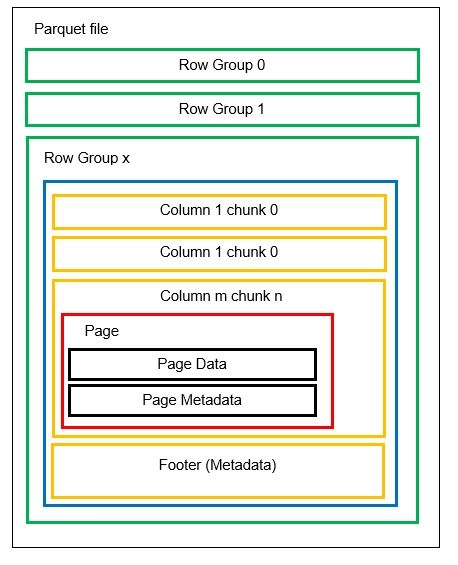
データは列チャンクに分割されるため、新しい値を新しいチャンクとファイルにエンコードして新しいデータを追加することも簡単です。 次に、影響を受けるファイルと行グループのメタデータが更新されます。 したがって、Parquetは柔軟な形式であると言えます。
Parquetは、ページ圧縮および辞書エンコード技術を使用したデータの圧縮をネイティブにサポートします。 辞書圧縮の簡単な例を見てみましょう。
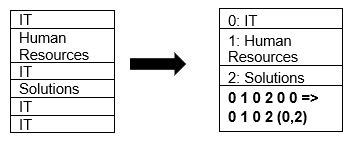
上記の例では、IT部門が4回表示されていることに注意してください。 したがって、ディクショナリに保存している間、フォーマットはデータを別の保存しやすい値(0,1,2…)と連続して繰り返される回数でエンコードします– IT、ITは保存するために0.2に変更されますより多くのスペース。 圧縮データのクエリにかかる時間は短くなります。
直接比較
CSV形式とParquet形式がどのように見えるかについての公正なアイデアが得られたので、いくつかの統計で両方の形式を比較します。
| CSV | 寄木細工 |
| 行ベースのストレージ形式。 | 行ベースと列ベースのストレージ形式のハイブリッド。 |
| デフォルトの圧縮オプションが利用できないため、多くのスペースを消費します。 たとえば、1TBのファイルはAmazonS3または他のクラウドに保存されたときに同じスペースを占有します。 | 保存中にデータを圧縮するため、消費するスペースが少なくなります。 Parquet形式で保存された1TBのファイルは、わずか130GBのスペースを占有します。 |
| 行ベースの検索のため、クエリの実行時間は遅くなります。 列ごとに、データのすべての行を取得する必要があります。 | 列ベースのストレージとメタデータの存在により、クエリ時間は約34倍高速になります。 |
| クエリごとにより多くのデータをスキャンする必要があります。 | クエリの実行のためにスキャンされるデータが約99%少なくなるため、パフォーマンスが最適化されます。 |
| ほとんどのストレージデバイスはストレージスペースに基づいて課金されるため、CSV形式はストレージコストが高いことを意味します。 | データは圧縮され、エンコードされた形式で保存されるため、ストレージコストが削減されます。 |
| ファイルスキーマは、推測(エラーにつながる)または提供(面倒)する必要があります。 | ファイルスキーマはメタデータに保存されます。 |
| この形式は、単純なデータ型に適しています。 | Parquetは、ネストされたスキーマ、配列、辞書などの複雑な型にも適しています。 |
結論
例を通して、Parquetはコスト、柔軟性、パフォーマンスの点でCSVよりも効率的であることがわかりました。 これは、特に全世界がクラウドストレージとスペースの最適化に移行している場合に、データを保存および取得するための効果的なメカニズムです。 Azure、AWS、BigQueryなどのすべての主要なプラットフォームはParquet形式をサポートしています。