
可能是 CSV 存储的最佳替代方案:Parquet Data
已发表: 2021-11-25与 CSV 等传统方法相比,Apache Parquet 为数据存储和检索提供了多项优势。
Parquet 格式旨在加快复杂类型的数据处理速度。 在本文中,我们将讨论 Parquet 格式如何适合当今不断增长的数据需求。
在深入探讨 Parquet 格式的细节之前,让我们先了解什么是 CSV 数据以及它对数据存储带来的挑战。
什么是 CSV 存储?
我们都听过很多关于CSV(C OMMA小号eparated V alues) -的组织和格式化数据的最常见的方式之一。 CSV 数据存储是基于行的。 CSV 文件以 .csv 扩展名存储。 我们可以使用 Excel、Google Sheets 或任何文本编辑器来存储和打开 CSV 数据。 一旦打开文件,数据就很容易查看。
嗯,这不好——绝对不是数据库格式。
此外,随着数据量的增长,查询、管理和检索变得困难。
以下是存储在 .CSV 文件中的数据示例:
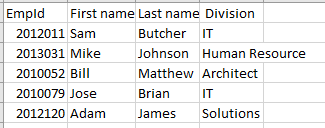
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions如果我们在 Excel 中查看,可以看到如下所示的行列结构:
CSV 存储的挑战
基于行的存储器如CSV适于对C reate,U PDATE和d elete操作。
怎么样在CRUD将R EAD,然后呢?
想象一下上面的 .csv 文件中有 100 万行。 打开文件并搜索您要查找的数据需要一定的时间。 没那么酷。 大多数云提供商(如 AWS)根据扫描或存储的数据量向公司收费——同样,CSV 文件会占用大量空间。
CSV 存储没有用于存储元数据的专有选项,这使得数据扫描成为一项乏味的任务。
那么,执行所有 CRUD 操作的经济高效且最佳的解决方案是什么? 让我们一探究竟。
什么是 Parquet 数据存储?
Parquet 是一种用于存储数据的开源存储格式。 它广泛用于 Hadoop 和 Spark 生态系统。 Parquet 文件存储为 .parquet 扩展名。
Parquet 是一种高度结构化的格式。 它还可以用于优化数据湖中大量存在的复杂原始数据。 这可以显着减少查询时间。
由于混合了基于行和列的(混合)存储格式,Parquet 可以提高数据存储效率和检索速度。 在这种格式中,数据被水平和垂直分区。 Parquet 格式也在很大程度上消除了解析开销。
该格式限制了 I/O 操作的总数,并最终限制了成本。
Parquet 还存储元数据,它存储有关数据的信息,如数据模式、值的数量、列的位置、最小值、行组的最大值、编码类型等。元数据存储在文件中的不同级别,使数据访问速度更快。
在 CSV 等基于行的访问中,数据检索需要时间,因为查询必须浏览每一行并获取特定的列值。 使用 Parquet 存储,可以一次访问所有必需的列。
总之,
- Parquet 基于柱状结构进行数据存储
- 它是一种优化的数据格式,用于在存储系统中批量存储复杂数据
- Parquet 格式包括各种数据压缩和编码方法
- 与 CSV 等其他存储格式相比,它显着减少了数据扫描时间和查询时间,并占用更少的磁盘空间
- 最小化 IO 操作次数,降低存储和查询执行成本
- 包括元数据,可以更轻松地查找数据
- 提供开源支持
Parquet 数据格式
在进入示例之前,让我们更详细地了解数据如何以 Parquet 格式存储:

我们可以在一个文件中有多个水平分区,称为行组。 在每个行组内,应用垂直分区。 这些列被分成几个列块。 数据存储为列块内的页面。 每个页面都包含编码的数据值和元数据。 正如我们之前提到的,整个文件的元数据也在行组级别存储在文件的页脚中。
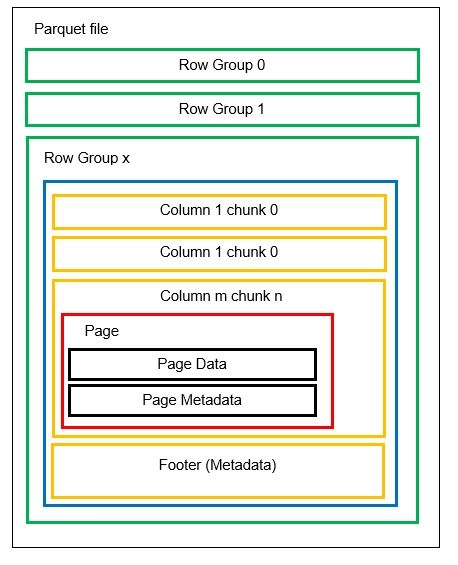
由于数据被拆分为列块,因此通过将新值编码到新块和文件中来添加新数据也很容易。 然后为受影响的文件和行组更新元数据。 因此,我们可以说 Parquet 是一种灵活的格式。
Parquet 本身支持使用页面压缩和字典编码技术压缩数据。 让我们看一个字典压缩的简单例子:
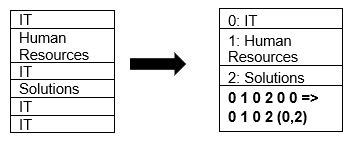
请注意,在上面的示例中,我们看到 IT 部门 4 次。 因此,在存储在字典中时,该格式使用另一个易于存储的值(0,1,2...)以及连续重复的次数对数据进行编码 - IT, IT 更改为 0,2 以保存更多空间。 查询压缩数据花费的时间更少。
头对头比较
现在我们对 CSV 和 Parquet 格式的外观有了一个大致的了解,是时候用一些统计数据来比较这两种格式了:
| CSV文件 | 实木复合地板 |
| 基于行的存储格式。 | 基于行和基于列的存储格式的混合。 |
| 由于没有可用的默认压缩选项,它会占用大量空间。 例如,一个 1TB 的文件存储在 Amazon S3 或任何其他云上时将占用相同的空间。 | 在存储的同时压缩数据,从而占用更少的空间。 以 Parquet 格式存储的 1 TB 文件将仅占用 130GB 的空间。 |
| 由于基于行的搜索,查询运行时间很慢。 对于每一列,必须检索每一行数据。 | 由于基于列的存储和元数据的存在,查询时间大约快了 34 倍。 |
| 每个查询必须扫描更多数据。 | 为执行查询而扫描的数据减少了约 99%,从而优化了性能。 |
| 大多数存储设备按存储空间收费,因此CSV格式意味着存储成本高。 | 由于数据以压缩编码格式存储,因此存储成本更低。 |
| 必须推断(导致错误)或提供(乏味)文件模式。 | 文件模式存储在元数据中。 |
| 该格式适用于简单的数据类型。 | Parquet 甚至适用于复杂类型,如嵌套模式、数组、字典。 |
结论
我们已经通过例子看到 Parquet 在成本、灵活性和性能方面比 CSV 更高效。 它是一种有效的数据存储和检索机制,尤其是当整个世界都在向云存储和空间优化迈进时。 Azure、AWS 和 BigQuery 等所有主要平台都支持 Parquet 格式。