
Muhtemelen CSV Depolamasına En İyi Alternatif: Parke Verileri
Yayınlanan: 2021-11-25Apache Parquet, CSV gibi geleneksel yöntemlerle karşılaştırıldığında veri depolama ve alma için çeşitli avantajlar sağlar.
Parke formatı, karmaşık türlerin daha hızlı veri işlemesi için tasarlanmıştır. Bu yazımızda, Parke formatının günümüzün sürekli artan data ihtiyaçlarına nasıl uygun olduğundan bahsedeceğiz.
Parke formatının ayrıntılarına girmeden önce, CSV verilerinin ne olduğunu ve veri depolama için ortaya koyduğu zorlukları anlayalım.
CSV depolaması nedir?
Hepimiz CSV hakkında çok şey duymuş (C OMMA S V alues eparated) - organize ve veri biçimlendirme en yaygın yollardan biri. CSV veri depolaması satır tabanlıdır. CSV dosyaları .csv uzantısıyla saklanır. CSV verilerini Excel, Google E-Tablolar veya herhangi bir metin düzenleyiciyi kullanarak depolayabilir ve açabiliriz. Dosya açıldıktan sonra veriler kolayca görüntülenebilir .
Bu iyi değil – kesinlikle bir veritabanı formatı için değil.
Ayrıca, veri hacmi büyüdükçe sorgulamak, yönetmek ve almak zorlaşır.
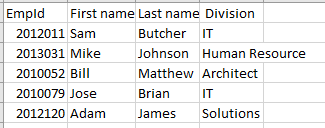
Bir .CSV dosyasında depolanan verilere bir örnek:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,SolutionsExcel'de görüntülersek, aşağıdaki gibi bir satır-sütun yapısı görebiliriz:
CSV depolama ile ilgili zorluklar
CSV gibi satır bazlı depolama Cı REATE U pdate D elete işlemleri için uygundur.
Peki ya CRUD'deki R read'e ne dersiniz?
Yukarıdaki .csv dosyasında bir milyon satır düşünün. Dosyayı açmak ve aradığınız verileri aramak makul bir süre alacaktır. Çok havalı değil. AWS gibi çoğu bulut sağlayıcı, şirketleri taranan veya depolanan veri miktarına göre ücretlendirir - yine CSV dosyaları çok fazla alan tüketir.
CSV depolama, meta verileri depolamak için özel bir seçeneğe sahip değildir, bu da veri taramasını sıkıcı bir görev haline getirir.
Peki, tüm CRUD işlemlerini gerçekleştirmek için uygun maliyetli ve optimal çözüm nedir? Keşfetelim.
Parke veri depolama nedir?
Parke, verileri depolamak için açık kaynaklı bir depolama biçimidir. Hadoop ve Spark ekosistemlerinde yaygın olarak kullanılmaktadır. Parke dosyaları .parquet uzantısı olarak saklanır.
Parke oldukça yapılandırılmış bir formattır. Veri göllerinde toplu olarak bulunan karmaşık ham verileri optimize etmek için de kullanılabilir. Bu, sorgu süresini önemli ölçüde azaltabilir.
Parke, satır ve sütun tabanlı (karma) depolama biçimlerinin bir karışımı nedeniyle veri depolamayı verimli hale getirir ve almayı daha hızlı hale getirir. Bu formatta veriler dikey olduğu kadar yatay olarak da bölümlenir. Parke formatı ayrıca ayrıştırma yükünü büyük ölçüde ortadan kaldırır.
Biçim, G/Ç işlemlerinin toplam sayısını ve sonuç olarak maliyeti kısıtlar.
Parquet ayrıca, veri şeması, değerlerin sayısı, sütunların konumu, minimum değer, satır gruplarının maksimum değer sayısı, kodlama türü gibi veriler hakkındaki bilgileri depolayan meta verileri de depolar. Meta veriler dosyada farklı düzeylerde depolanır. , veri erişimini hızlandırır.
CSV gibi satır tabanlı erişimde, sorgunun her satırda gezinmesi ve belirli sütun değerlerini alması gerektiğinden veri alımı zaman alır. Parke depolama ile gerekli tüm kolonlara tek seferde ulaşılabilir.
Özetle,
- Parke, veri depolama için sütunlu yapıya dayanmaktadır.
- Karmaşık verileri depolama sistemlerinde toplu olarak depolamak için optimize edilmiş bir veri formatıdır.
- Parke formatı, veri sıkıştırma ve kodlama için çeşitli yöntemler içerir
- Veri tarama süresini ve sorgulama süresini önemli ölçüde azaltır ve CSV gibi diğer depolama biçimlerine kıyasla daha az disk alanı kaplar
- GÇ işlemlerinin sayısını en aza indirerek depolama ve sorgu yürütme maliyetini düşürür
- Veri bulmayı kolaylaştıran meta veriler içerir
- Açık kaynak desteği sağlar
Parke veri formatı
Bir örneğe geçmeden önce, verilerin Parquet formatında nasıl depolandığını daha ayrıntılı olarak anlayalım:

Tek bir dosyada Satır grupları olarak bilinen birden fazla yatay bölüme sahip olabiliriz. Her Satır grubu içinde dikey bölümleme uygulanır. Sütunlar birkaç sütun parçasına bölünmüştür. Veriler, sütun parçalarının içinde sayfalar olarak depolanır. Her sayfa, kodlanmış veri değerlerini ve meta verileri içerir. Daha önce de belirttiğimiz gibi, tüm dosyanın meta verileri, dosyanın Row grubu düzeyinde alt bilgisinde de saklanır.
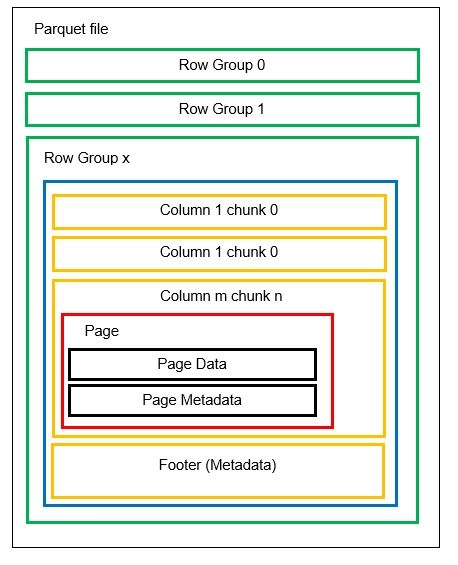
Veriler sütun parçalarına bölündüğünden, yeni değerleri yeni bir yığın ve dosyaya kodlayarak yeni veriler eklemek de kolaydır. Meta veriler daha sonra etkilenen dosyalar ve satır grupları için güncellenir. Böylece Parke esnek bir formattır diyebiliriz.
Parke, sayfa sıkıştırma ve sözlük kodlama tekniklerini kullanarak verilerin sıkıştırılmasını yerel olarak destekler. Basit bir sözlük sıkıştırma örneği görelim:
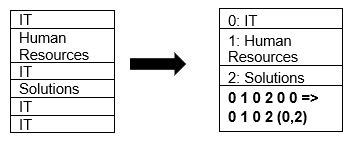
Yukarıdaki örnekte BT bölümünü 4 kez gördüğümüzü unutmayın. Bu nedenle, sözlükte saklanırken format, verileri saklaması kolay başka bir değer (0,1,2…) ile birlikte sürekli tekrarlanma sayısıyla kodlar – IT, IT, kaydetmek için 0,2 olarak değiştirilir. daha çok alan. Sıkıştırılmış verileri sorgulamak daha az zaman alır.
Kafa kafaya karşılaştırma
Artık CSV ve Parke formatlarının nasıl göründüğüne dair adil bir fikre sahip olduğumuza göre, bazı istatistiklerin her iki formatı da karşılaştırmasının zamanı geldi:
| CSV | Parke |
| Satır tabanlı depolama biçimi. | Satır tabanlı ve sütun tabanlı depolama biçimlerinin bir karışımı. |
| Varsayılan sıkıştırma seçeneği bulunmadığından çok fazla alan tüketir. Örneğin, 1 TB'lık bir dosya, Amazon S3'te veya başka bir bulutta depolandığında aynı alanı kaplar. | Verileri depolarken sıkıştırır, böylece daha az yer kaplar. Parke biçiminde depolanan 1 TB'lık bir dosya yalnızca 130 GB yer kaplar. |
| Satır tabanlı arama nedeniyle sorgu çalışma süresi yavaş. Her sütun için, her veri satırının alınması gerekir. | Sütun tabanlı depolama ve meta verilerin varlığı nedeniyle sorgulama süresi yaklaşık 34 kat daha hızlıdır. |
| Sorgu başına daha fazla veri taranmalıdır. | Sorgunun yürütülmesi için yaklaşık %99 daha az veri taranır, böylece performans optimize edilir. |
| Çoğu depolama cihazı, depolama alanına göre ücretlendirilir, bu nedenle CSV formatı, yüksek depolama maliyeti anlamına gelir. | Veriler sıkıştırılmış, kodlanmış biçimde depolandığından daha az depolama maliyeti. |
| Dosya şemasının ya çıkarsanması (hatalara yol açar) ya da sağlanması (sıkıcı) gerekir. | Dosya şeması meta verilerde saklanır. |
| Biçim, basit veri türleri için uygundur. | Parke, iç içe şemalar, diziler, sözlükler gibi karmaşık türler için bile uygundur. |
Çözüm
Parkenin maliyet, esneklik ve performans açısından CSV'den daha verimli olduğunu örneklerle gördük. Özellikle tüm dünya bulut depolama ve alan optimizasyonuna doğru ilerlerken, verileri depolamak ve almak için etkili bir mekanizmadır. Azure, AWS ve BigQuery gibi tüm büyük platformlar Parke biçimini destekler.