
可能是 CSV 存儲的最佳替代方案:Parquet Data
已發表: 2021-11-25與 CSV 等傳統方法相比,Apache Parquet 為數據存儲和檢索提供了多項優勢。
Parquet 格式旨在加快複雜類型的數據處理速度。 在本文中,我們將討論 Parquet 格式如何適合當今不斷增長的數據需求。
在深入探討 Parquet 格式的細節之前,讓我們先了解什麼是 CSV 數據以及它對數據存儲帶來的挑戰。
什麼是 CSV 存儲?
我們都聽過很多關於CSV(C OMMA小號eparated V alues) -的組織和格式化數據的最常見的方式之一。 CSV 數據存儲是基於行的。 CSV 文件以 .csv 擴展名存儲。 我們可以使用 Excel、Google Sheets 或任何文本編輯器來存儲和打開 CSV 數據。 一旦打開文件,數據就很容易查看。
嗯,這不好——絕對不是數據庫格式。
此外,隨著數據量的增長,查詢、管理和檢索變得困難。
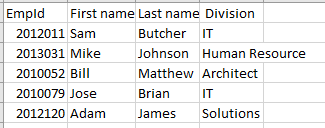
以下是存儲在 .CSV 文件中的數據示例:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions如果我們在 Excel 中查看,可以看到如下所示的行列結構:
CSV 存儲的挑戰
基於行的存儲器如CSV適於對C reate,U PDATE和d elete操作。
怎麼樣在CRUD將R EAD,然後呢?
想像一下上面的 .csv 文件中有 100 萬行。 打開文件並蒐索您要查找的數據需要一定的時間。 沒那麼酷。 大多數雲提供商(如 AWS)根據掃描或存儲的數據量向公司收費——同樣,CSV 文件會佔用大量空間。
CSV 存儲沒有用於存儲元數據的專有選項,這使得數據掃描成為一項乏味的任務。
那麼,執行所有 CRUD 操作的經濟高效且最佳的解決方案是什麼? 讓我們一探究竟。
什麼是 Parquet 數據存儲?
Parquet 是一種用於存儲數據的開源存儲格式。 它廣泛用於 Hadoop 和 Spark 生態系統。 Parquet 文件存儲為 .parquet 擴展名。
Parquet 是一種高度結構化的格式。 它還可以用於優化數據湖中大量存在的複雜原始數據。 這可以顯著減少查詢時間。
由於混合了基於行和列的(混合)存儲格式,Parquet 可以提高數據存儲效率和檢索速度。 在這種格式中,數據被水平和垂直分區。 Parquet 格式也在很大程度上消除了解析開銷。
該格式限制了 I/O 操作的總數,並最終限制了成本。
Parquet 還存儲元數據,它存儲有關數據的信息,如數據模式、值的數量、列的位置、最小值、行組的最大值、編碼類型等。元數據存儲在文件中的不同級別,使數據訪問速度更快。
在 CSV 等基於行的訪問中,數據檢索需要時間,因為查詢必須瀏覽每一行並獲取特定的列值。 使用 Parquet 存儲,可以一次訪問所有必需的列。
總之,
- Parquet 基於柱狀結構進行數據存儲
- 它是一種優化的數據格式,用於在存儲系統中批量存儲複雜數據
- Parquet 格式包括各種數據壓縮和編碼方法
- 與 CSV 等其他存儲格式相比,它顯著減少了數據掃描時間和查詢時間,並佔用更少的磁盤空間
- 最小化 IO 操作次數,降低存儲和查詢執行成本
- 包括元數據,可以更輕鬆地查找數據
- 提供開源支持
Parquet 數據格式
在進入示例之前,讓我們更詳細地了解數據如何以 Parquet 格式存儲:

我們可以在一個文件中有多個水平分區,稱為行組。 在每個行組內,應用垂直分區。 這些列被分成幾個列塊。 數據存儲為列塊內的頁面。 每個頁面都包含編碼的數據值和元數據。 正如我們之前提到的,整個文件的元數據也在行組級別存儲在文件的頁腳中。
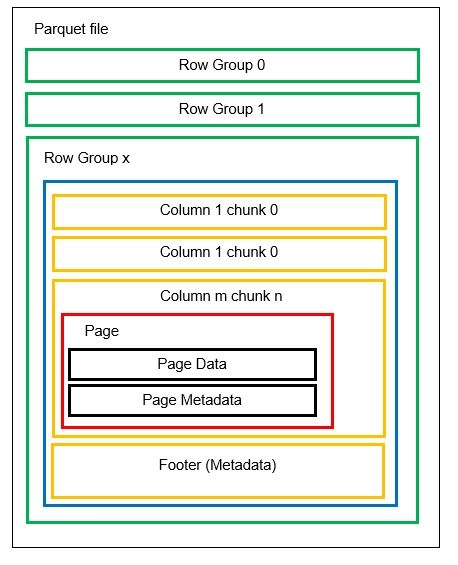
由於數據被拆分為列塊,因此通過將新值編碼到新塊和文件中來添加新數據也很容易。 然後為受影響的文件和行組更新元數據。 因此,我們可以說 Parquet 是一種靈活的格式。
Parquet 本身支持使用頁面壓縮和字典編碼技術壓縮數據。 讓我們看一個字典壓縮的簡單例子:
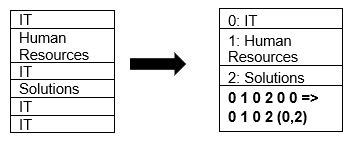
請注意,在上面的示例中,我們看到 IT 部門 4 次。 因此,在存儲在字典中時,該格式使用另一個易於存儲的值(0,1,2...)以及連續重複的次數對數據進行編碼 - IT, IT 更改為 0,2 以保存更多空間。 查詢壓縮數據花費的時間更少。
頭對頭比較
現在我們對 CSV 和 Parquet 格式的外觀有了一個大致的了解,是時候用一些統計數據來比較這兩種格式了:
| CSV文件 | 實木複合地板 |
| 基於行的存儲格式。 | 基於行和基於列的存儲格式的混合。 |
| 由於沒有可用的默認壓縮選項,它會佔用大量空間。 例如,一個 1TB 的文件存儲在 Amazon S3 或任何其他雲上時將佔用相同的空間。 | 在存儲的同時壓縮數據,從而佔用更少的空間。 以 Parquet 格式存儲的 1 TB 文件將僅佔用 130GB 的空間。 |
| 由於基於行的搜索,查詢運行時間很慢。 對於每一列,必須檢索每一行數據。 | 由於基於列的存儲和元數據的存在,查詢時間大約快了 34 倍。 |
| 每個查詢必須掃描更多數據。 | 為執行查詢而掃描的數據減少了約 99%,從而優化了性能。 |
| 大多數存儲設備按存儲空間收費,因此CSV格式意味著存儲成本高。 | 由於數據以壓縮編碼格式存儲,因此存儲成本更低。 |
| 必須推斷(導致錯誤)或提供(乏味)文件模式。 | 文件模式存儲在元數據中。 |
| 該格式適用於簡單的數據類型。 | Parquet 甚至適用於復雜類型,如嵌套模式、數組、字典。 |
結論
我們已經通過例子看到 Parquet 在成本、靈活性和性能方面比 CSV 更高效。 它是一種有效的數據存儲和檢索機制,尤其是當整個世界都在向雲存儲和空間優化邁進時。 Azure、AWS 和 BigQuery 等所有主要平台都支持 Parquet 格式。