
Script de Python gratuito para n-gramas de Google Ads
Publicado: 2022-04-12Los N-gramas pueden ser un arma importante para analizar consultas de búsqueda en Google Ads o SEO. Por lo tanto, hemos producido una secuencia de comandos de Python gratuita para ayudarlo a analizar n-gramas de cualquier longitud tanto en su fuente de productos como en sus consultas de búsqueda. Explicaremos qué son los n-gramas y cómo usarlos para optimizar sus anuncios de Google, en particular para Google Shopping. Finalmente, le mostraremos cómo usar nuestro script gratuito de n-grams para mejorar sus resultados de Google Ads.
¿Qué son los n-gramas?
Los N-gramas son frases de N número de palabras, extraídas de cuerpos de texto más largos. La 'N' aquí puede ser reemplazada por cualquier número.
Por ejemplo, en una oración como "el gato saltó sobre la colchoneta", "el gato saltó" o "la colchoneta" serían 2 gramos (o 'bi-gramos').
"El gato saltó" o "el gato saltó sobre" son ejemplos de 3 gramos (o 'tri-gramos') de esta oración.
Cómo ayudan los n-grams a las consultas de búsqueda
Los N-gramas son útiles para analizar consultas de búsqueda en Google Ads porque ciertas frases clave pueden aparecer en muchas consultas de búsqueda diferentes.
Los N-gramas nos permiten analizar el impacto de estas frases en todo su inventario. Por lo tanto, le permiten tomar mejores decisiones y optimizaciones a escala.
Incluso nos permite comprender el impacto de las palabras sueltas. Por ejemplo, si vio un rendimiento bajo en las búsquedas que contienen la palabra "gratis" (un '1 gramo'), puede decidir eliminar esa palabra de todas las campañas.
O bien, un buen rendimiento a través de consultas de búsqueda que contienen "personalizado" podría alentarlo a crear una campaña dedicada.
Los N-gramas son particularmente útiles para ver las consultas de búsqueda de Google Shopping.
La naturaleza automatizada de la segmentación por palabras clave de los anuncios de lista de productos significa que puede aparecer para cientos de miles de consultas de búsqueda. Particularmente cuando tienes una gran cantidad de variantes de productos con características muy específicas.
Nuestro script N-grams le permite pasar de ese desorden a las frases que importan.
Análisis de consultas de búsqueda con n-gramas
El primer caso de uso de n-gramas es el análisis de consultas de búsqueda.
Nuestra secuencia de comandos n-grams python para Google Ads contiene instrucciones completas sobre cómo ejecutarla, pero
repasaremos cómo sacarle el máximo partido.
- Necesitará tener Python instalado en su máquina para comenzar. Si no lo haces, es muy fácil. Primero instala Anaconda. Luego, abra Anaconda Prompt y escriba 'conda install jupyter lab'. Jupyter Lab es el entorno en el que ejecutará este script.
Simplemente descargue un informe de consulta de búsqueda de sus anuncios de Google. Recomendamos configurarlo como un informe personalizado en la sección "informes" de Google Ads. Incluso puede configurar esto en el nivel de MCC si desea ejecutar este script en varias cuentas.

3. Luego, simplemente actualice la configuración en el script para hacer lo que quiera y ejecute todas las celdas.
Tomará un poco de tiempo ejecutarlo, pero tenga paciencia. Verá que el progreso se actualiza en la parte inferior a medida que hace su magia.
El resultado aparecerá como un archivo de Excel dentro de cualquier carpeta en la que esté ejecutando el script. Sugerimos usar la carpeta de descargas. El archivo se etiquetará con cualquier nombre que defina.
Cada pestaña del archivo de Excel contiene un análisis de n-grama diferente. Por ejemplo, aquí hay un análisis de bi-grama:
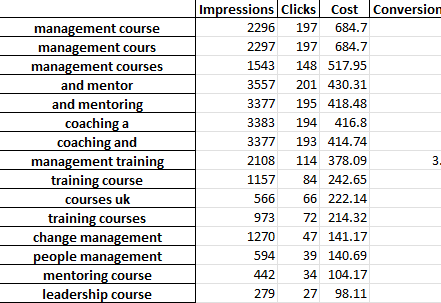
Hay varias formas en las que puede usar este informe para encontrar mejoras.
Puede comenzar con las frases de mayor gasto y ver cualquier valor atípico para CPA o ROAS.
Filtrar sus informes a los que no realizan conversiones también resaltará las áreas de bajo gasto.
Si ve convertidores deficientes en la pestaña de palabras sueltas, puede verificar fácilmente en qué contexto se usan las palabras en la pestaña de 3 gramos.
Por ejemplo, en una cuenta de capacitación profesional, podríamos detectar que 'Oxford' tiene un desempeño deficiente constante. La pestaña de 3 gramos revela rápidamente que es probable que los usuarios estén buscando un curso más formal y orientado a la universidad.
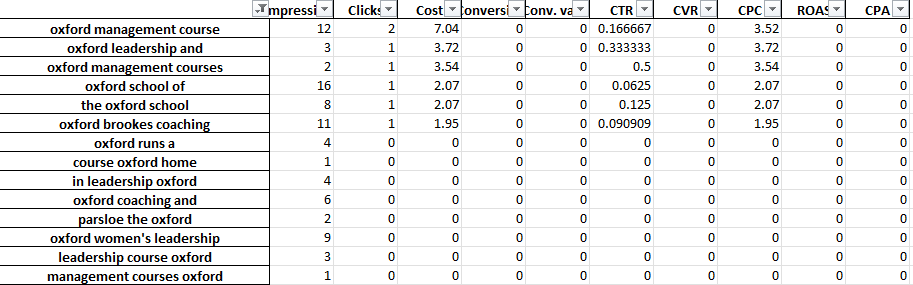
Por lo tanto, puede negar rápidamente esta palabra.
En última instancia, utilice este informe de la forma que mejor le convenga.
Optimización de feeds de productos con n-gramas
Nuestro segundo script de n-grams para Google Ads analiza el rendimiento de su producto.
Nuevamente, puede encontrar instrucciones completas dentro del propio script.
Este script analiza el rendimiento de las frases dentro de los títulos de sus productos. El título del producto, después de todo, determina en gran medida para qué palabras clave aparece. El título también es el texto principal de su anuncio. Por lo tanto, los títulos son increíblemente importantes.
El script está diseñado para ayudarlo a encontrar frases potenciales dentro de estos títulos que puede adaptar para mejorar su rendimiento de Google Shopping.
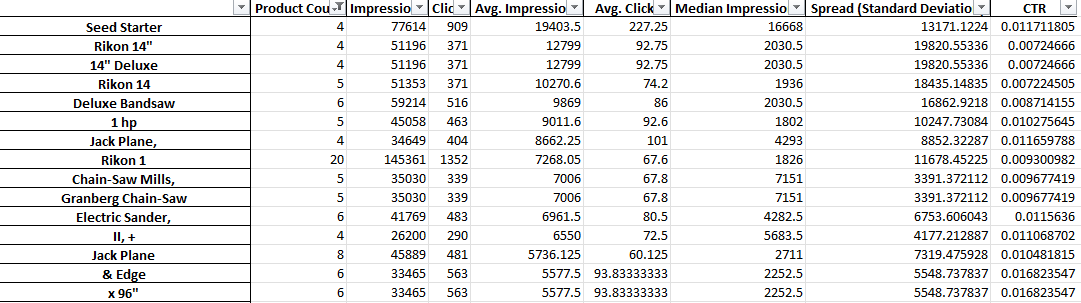
Como puede ver arriba, el resultado de este script es un poco diferente. Debido a las limitaciones de la API de informes de Google, no puede acceder a las métricas de conversión (como los ingresos) mientras se encuentra en el nivel del título del producto.
Este informe, por lo tanto, le brinda recuentos de productos, tráfico promedio y la dispersión (desviación estándar) de las frases de productos.
Debido a que se basa en la visibilidad, puede usar el informe para identificar frases que puedan hacer que sus productos sean más visibles. Luego puede agregarlos a más títulos de sus productos.

Por ejemplo, podemos encontrarnos con una frase con un número de impresiones promedio muy alto y que aparece dentro del título de varios productos. También tiene una desviación estándar baja, lo que significa que no es probable que haya un solo producto asombroso que distorsione nuestras cifras aquí.
Usamos esta herramienta para expandir dramáticamente la visibilidad de compras para un cliente. El cliente vendió productos en miles de tamaños diferentes. Por ejemplo 8x10mm. La gente también estaba comprando tamaños muy específicos que necesitaban.
Pero Google no entendió bien las diferentes convenciones de nomenclatura posibles para este tamaño: búsquedas como 8 mm por 10 mm, 8 x 10 mm, 8 mm x 10 mm se trataban como consultas de búsqueda casi completamente diferentes.
Por lo tanto, utilizamos nuestro script n-grams para determinar cuál de estas convenciones de nomenclatura daba a nuestros productos la mejor visibilidad.
Encontramos la mejor combinación e hicimos los cambios en nuestro feed de productos. Como resultado, el tráfico de las campañas de compras del cliente se disparó en más del 550 % en el transcurso de un solo mes.
Los nombres de productos son importantes y los n-gramas pueden ayudarlo con eso.
Secuencias de comandos N-gram para anuncios de Google
Aquí están los dos guiones completos.
Script N-grams para consultas de búsqueda de Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Script N-grams para analizar feeds de productos
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()También puede encontrar versiones actualizadas del script n-grams en github para descargar.

Estos scripts tienen la licencia Creative Commons BY SA 4.0, lo que significa que puede compartirlos y adaptarlos libremente, pero lo alentamos a que siempre comparta sus versiones mejoradas libremente para que todos las usen. Los N-gramas son demasiado útiles para no compartirlos.
Esta es solo una de las muchas herramientas, scripts y plantillas gratuitas que ponemos a disposición de los miembros de Ayima Insights Club. Puede obtener más información sobre Insights Club y registrarse de forma gratuita aquí.