
Script Python gratuit pour les n-grammes Google Ads
Publié: 2022-04-12Les N-grammes peuvent être une arme importante pour analyser les requêtes de recherche sur Google Ads ou SEO. Nous avons donc créé un script python gratuit pour vous aider à analyser les n-grammes de n'importe quelle longueur à la fois dans votre flux de produits et dans vos requêtes de recherche. Nous expliquerons ce que sont les n-grammes et comment les utiliser pour optimiser vos annonces Google, en particulier pour Google Shopping. Nous allons enfin vous montrer comment utiliser notre script n-grams gratuit pour améliorer vos résultats Google Ads.
Que sont les n-grammes ?
Les N-grammes sont des phrases d'un nombre N de mots, extraites de corps de texte plus longs. Le 'N' ici peut être remplacé par n'importe quel nombre.
Par exemple, dans une phrase comme « le chat a sauté sur le tapis », « le chat a sauté » ou « le tapis » seraient tous deux de 2 grammes (ou « bi-grammes »).
« Le chat a sauté » ou « le chat a sauté dessus » sont deux exemples de 3 grammes (ou « tri-grammes ») de cette phrase.
Comment les n-grammes aident les requêtes de recherche
Les N-grammes sont utiles pour analyser les requêtes de recherche dans Google Ads, car certaines phrases clés peuvent apparaître dans de nombreuses requêtes de recherche différentes.
N-grams nous permet d'analyser l'impact de ces phrases sur l'ensemble de votre inventaire. Ils vous permettent donc de prendre de meilleures décisions et des optimisations à grande échelle.
Cela nous permet même de comprendre l'impact de mots isolés. Par exemple, si vous constatez une faible performance des recherches contenant le mot « gratuit » (un « 1 gramme »), vous pouvez décider de supprimer ce mot de toutes les campagnes.
Ou, de bonnes performances grâce à des requêtes de recherche contenant « personnalisé » peuvent vous encourager à créer une campagne dédiée.
Les N-grammes sont particulièrement utiles pour consulter les requêtes de recherche de Google Shopping.
La nature automatisée du ciblage par mot-clé des annonces pour une offre de produit signifie que vous pouvez faire surface pour des centaines de milliers de requêtes de recherche. Surtout lorsque vous avez un grand nombre de variantes de produits avec des caractéristiques très spécifiques.
Notre script N-grams vous permet de réduire ce fouillis aux phrases qui comptent.
Analyser les requêtes de recherche avec n-grammes
Le premier cas d'utilisation des n-grammes est l'analyse des requêtes de recherche.
Notre script python n-grams pour Google Ads contient des instructions complètes sur la façon de l'exécuter, mais
nous verrons comment en tirer le meilleur parti.
- Vous aurez besoin d'avoir python installé sur votre machine pour commencer. Si vous ne le faites pas, c'est très facile. Vous installez d'abord Anaconda. Ensuite, ouvrez l'invite Anaconda et tapez "conda install jupyter lab". Jupyter Lab est l'environnement dans lequel vous exécuterez ce script.
Téléchargez simplement un rapport sur les requêtes de recherche à partir de vos annonces Google. Nous vous recommandons de le configurer en tant que rapport personnalisé dans la section "Rapports" de Google Ads. Vous pouvez même le configurer au niveau du Centre multicompte si vous souhaitez exécuter ce script sur plusieurs comptes.

3. Ensuite, mettez simplement à jour les paramètres du script pour faire ce que vous voulez et exécutez toutes les cellules.
Il faudra un peu de temps pour courir, mais restez patient. Vous verrez les progrès mis à jour en bas car ils font leur magie.
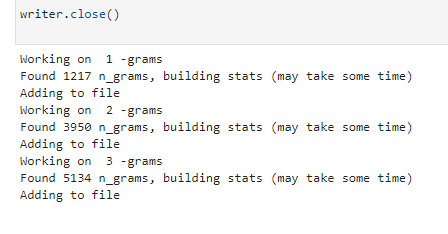
La sortie apparaîtra sous la forme d'un fichier Excel dans le dossier dans lequel vous exécutez le script, nous vous suggérons d'utiliser le dossier des téléchargements. Le fichier sera étiqueté avec n'importe quel nom que vous définissez.
Chaque onglet du fichier Excel contient une analyse n-gramme différente. Par exemple, voici une analyse bi-gramme :
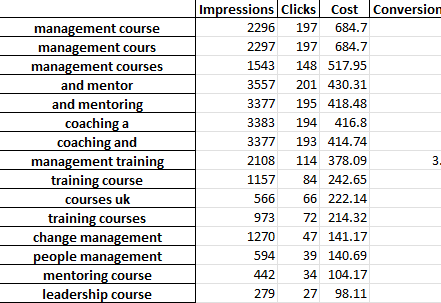
Il existe plusieurs façons d'utiliser ce rapport pour trouver des améliorations.
Vous pouvez commencer par les phrases les plus coûteuses et examiner les valeurs aberrantes pour le CPA ou le ROAS.
Le filtrage de vos rapports sur les non-convertisseurs mettra également en évidence les zones de mauvaises dépenses.
Si vous voyez de mauvais convertisseurs dans l'onglet des mots simples, vous pouvez facilement vérifier dans quel contexte les mots sont utilisés dans l'onglet 3-Gram.
Par exemple, dans un compte de formation professionnelle, nous pouvons remarquer que « Oxford » fonctionne systématiquement mal. L'onglet 3-Gram révèle rapidement que les utilisateurs sont susceptibles de rechercher un cours plus formel, orienté vers l'université.
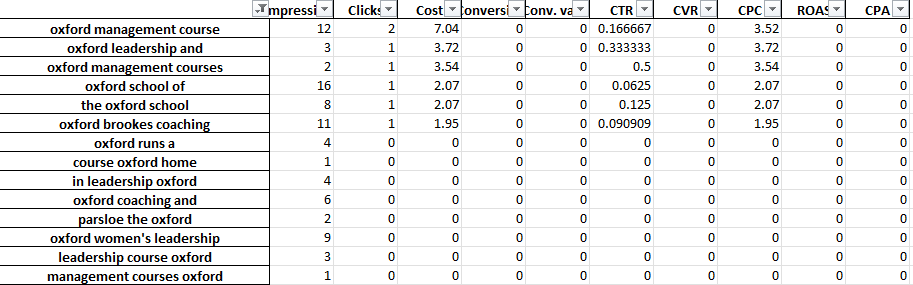
Vous pouvez donc rapidement supprimer ce mot.
En fin de compte, utilisez ce rapport de la manière qui vous convient le mieux.
Optimiser les flux de produits avec n-grammes
Notre deuxième script n-grams pour Google Ads analyse les performances de votre produit.
Encore une fois, vous pouvez trouver des instructions complètes dans le script lui-même
Ce script examine les performances des phrases dans les titres de vos produits. Le titre du produit, après tout, détermine dans une large mesure les mots-clés pour lesquels vous vous présentez. Le titre est également votre principal texte publicitaire. Les titres sont donc incroyablement importants.
Le script est conçu pour vous aider à trouver des phrases potentielles dans ces titres que vous pouvez adapter pour améliorer vos performances à partir de Google Shopping.
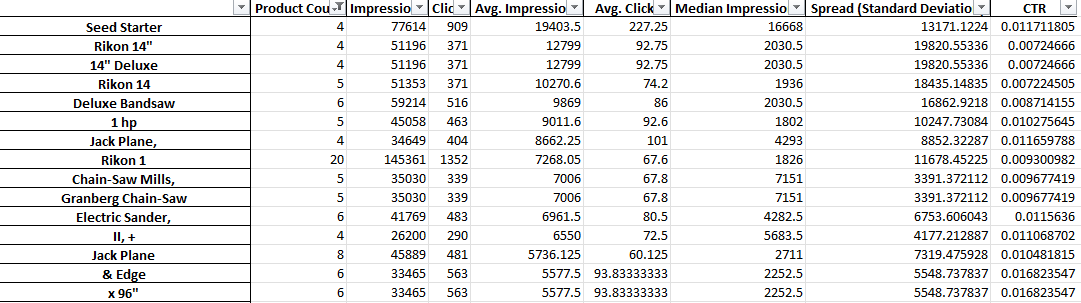
Comme vous pouvez le voir ci-dessus, la sortie de ce script est un peu différente. En raison des limitations de l'API de création de rapports de Google, vous ne pouvez pas accéder aux mesures de conversion (comme les revenus) tant que vous êtes au niveau du titre du produit.
Ce rapport vous donne donc le nombre de produits, le trafic moyen et la propagation (écart type) des phrases de produit.
Parce qu'il est basé sur la visibilité, vous pouvez utiliser le rapport pour identifier les phrases susceptibles de rendre vos produits plus visibles. Vous pouvez ensuite les ajouter à plusieurs de vos titres de produits.

Par exemple, nous pourrions trouver une phrase avec un nombre très élevé d'impressions moyennes et qui apparaît dans le titre de plusieurs produits. Il a également un faible écart type - ce qui signifie qu'il est peu probable qu'un seul produit étonnant fausse nos chiffres ici.
Nous avons utilisé cet outil pour augmenter considérablement la visibilité des achats d'un client. Le client a vendu des produits dans des milliers de tailles différentes. Par exemple 8x10mm. Les gens achetaient également des tailles très spécifiques dont ils avaient besoin.
Mais Google ne comprenait pas bien les différentes conventions de dénomination possibles pour ce dimensionnement : des recherches telles que 8 mm sur 10 mm, 8 x 10 mm, 8 mm x 10 mm étaient toutes traitées comme des requêtes de recherche presque entièrement différentes.
Nous avons donc utilisé notre script n-grams pour déterminer laquelle de ces conventions de nommage donnait à nos produits la meilleure visibilité.
Nous avons trouvé la meilleure correspondance et apporté les modifications à notre flux de produits. En conséquence, le trafic vers les campagnes Shopping du client a augmenté de plus de 550 % en un seul mois.
La dénomination des produits est importante et les n-grammes peuvent vous aider.
Scripts N-gram pour Google Ads
Voici les deux scripts complets.
Script N-grams pour les requêtes de recherche Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Script N-grammes pour analyser les flux de produits
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Vous pouvez également trouver des versions mises à jour du script n-grams sur github à télécharger.

Ces scripts sont sous licence Creative Commons BY SA 4.0, ce qui signifie que vous êtes libre de les partager et de les adapter, mais nous vous encourageons à toujours partager librement vos versions améliorées pour que tout le monde puisse les utiliser. Les N-grammes sont trop utiles pour ne pas être partagés.
Ce n'est qu'un des nombreux outils, scripts et modèles gratuits que nous mettons à la disposition des membres d'Ayima Insights Club. Vous pouvez en savoir plus sur Insights Club et vous inscrire gratuitement ici.