
Script Python gratuito para n-grams do Google Ads
Publicados: 2022-04-12N-grams podem ser uma arma significativa para analisar consultas de pesquisa no Google Ads ou SEO. Então, produzimos um script python gratuito para ajudá-lo a analisar n-grams de qualquer comprimento em seu feed de produtos e em suas consultas de pesquisa. Explicaremos o que são n-grams e como usar n-grams para otimizar seus anúncios do Google, principalmente para o Google Shopping. Finalmente, mostraremos como usar nosso script n-grams gratuito para melhorar seus resultados do Google Ads.
O que são n-gramas?
N-gramas são frases de N número de palavras, extraídas de corpos de texto mais longos. O 'N' aqui pode ser substituído por qualquer número.
Por exemplo, em uma frase como “o gato pulou no tapete”, “o gato pulou” ou “o tapete” seriam ambos 2 gramas (ou 'bigramas').
“O gato pulou” ou “o gato pulou” são exemplos de 3 gramas (ou 'trigramas') desta frase.
Como os n-grams ajudam nas consultas de pesquisa
N-grams são úteis na análise de consultas de pesquisa no Google Ads porque certas frases-chave podem aparecer em muitas consultas de pesquisa diferentes.
N-grams nos permitem analisar o impacto dessas frases em todo o seu inventário. Eles, portanto, permitem que você tome melhores decisões e otimizações em escala.
Até nos permite entender o impacto de palavras isoladas. Por exemplo, se você observar um desempenho fraco em pesquisas que contenham a palavra "grátis" (um '1 grama'), poderá decidir excluir essa palavra de todas as campanhas.
Ou um bom desempenho por meio de consultas de pesquisa contendo “personalizado” pode incentivá-lo a criar uma campanha dedicada.
Os N-grams são particularmente úteis para analisar as consultas de pesquisa do Google Shopping.
A natureza automatizada da segmentação por palavras-chave dos anúncios da lista de produtos significa que você pode exibir centenas de milhares de consultas de pesquisa. Especialmente quando você tem um grande número de variantes de produtos com recursos muito específicos.
Nosso script N-grams permite que você corte essa confusão para as frases que importam.
Analisando consultas de pesquisa com n-grams
O primeiro caso de uso para n-grams é analisar consultas de pesquisa.
Nosso script python n-grams para Google Ads contém instruções completas sobre como executá-lo, mas
vamos ver como tirar o máximo proveito disso.
- Você precisará ter o python instalado em sua máquina para começar. Se você não fizer isso, é muito fácil. Você primeiro instala o Anaconda. Em seguida, abra o Prompt do Anaconda e digite 'conda install jupyter lab'. Jupyter Lab é o ambiente no qual você executará este script.
Basta fazer o download de um relatório de consulta de pesquisa do seu Google Ads. Recomendamos configurá-lo como um relatório personalizado na seção "relatórios" do Google Ads. Você pode até configurar isso no nível da MCC se desejar executar esse script em várias contas.

3. Em seguida, basta atualizar as configurações no script para fazer o que você deseja e executar todas as células.
Vai demorar um pouco para correr, mas tenha paciência. Você verá o progresso sendo atualizado na parte inferior, pois faz sua mágica.
A saída aparecerá como um arquivo do Excel em qualquer pasta em que você esteja executando o script, sugerimos usar a pasta de downloads. O arquivo será rotulado com qualquer nome que você definir.
Cada guia do arquivo excel contém uma análise de n-gram diferente. Por exemplo, aqui está uma análise de bigramas:
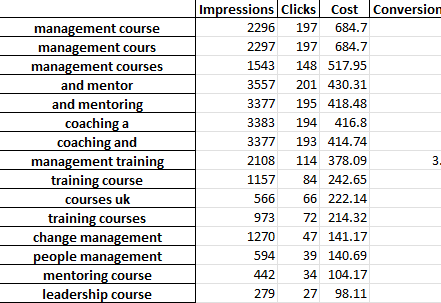
Há várias maneiras de usar esse relatório para encontrar melhorias.
Você pode começar com as frases de gastos mais altos e observar quaisquer discrepâncias para CPA ou ROAS.
Filtrar seus relatórios para não-conversores também destacará áreas de gastos insatisfatórios.
Se você vir conversores ruins na guia de palavras únicas, poderá verificar facilmente em que contexto as palavras estão sendo usadas na guia 3-Gram.
Por exemplo, em uma conta de treinamento profissional, podemos identificar que 'Oxford' tem um desempenho consistentemente ruim. A guia 3-Gram revela rapidamente que os usuários provavelmente procurarão um curso mais formal e voltado para a universidade.
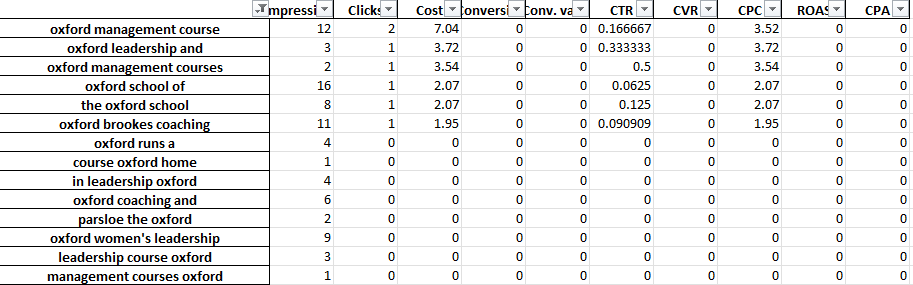
Você pode, portanto, rapidamente negar esta palavra.
Em última análise, use este relatório da maneira que funcionar melhor para você.
Otimizando feeds de produtos com n-gramas
Nosso segundo script n-grams para o Google Ads analisa o desempenho do seu produto.
Novamente, você pode encontrar instruções completas no próprio script
Este script analisa o desempenho das frases nos títulos dos seus produtos. O título do produto, afinal, determina em grande parte para quais palavras-chave você aparece. O título também é sua cópia do anúncio principal. Os títulos são, portanto, incrivelmente importantes.
O script foi desenvolvido para ajudar você a encontrar frases em potencial nesses títulos que podem ser adaptadas para melhorar seu desempenho no Google Shopping.
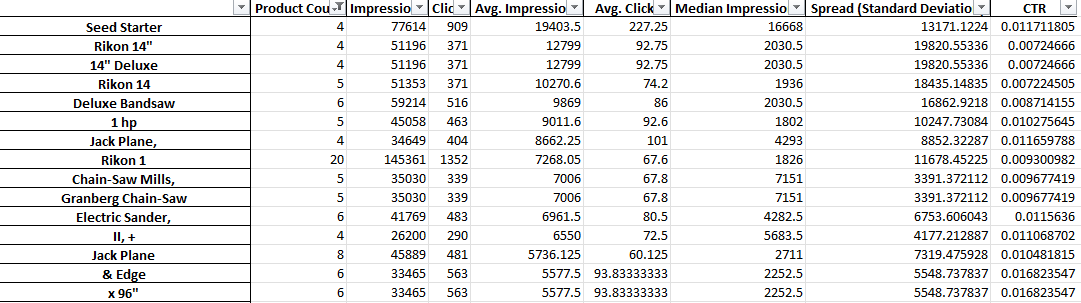
Como você pode ver acima, a saída deste script é um pouco diferente. Devido às limitações da API de relatórios do Google, você não pode acessar as métricas de conversão (como receita) enquanto estiver no nível do título do produto.
Este relatório, portanto, fornece contagens de produtos, tráfego médio e o spread (desvio padrão) das frases do produto.
Por se basear na visibilidade, você pode usar o relatório para identificar frases que possam tornar seus produtos mais visíveis. Você pode então adicioná-los a mais títulos de seus produtos.

Por exemplo, podemos encontrar uma frase com um número muito alto de impressões médias e que aparece no título de vários produtos. Ele também tem um desvio padrão baixo - o que significa que não é provável que haja apenas um produto incrível que esteja distorcendo nossos números aqui.
Usamos essa ferramenta para expandir drasticamente a visibilidade de compras para um cliente. O cliente vendia produtos em milhares de tamanhos diferentes. Por exemplo 8x10mm. As pessoas também estavam comprando tamanhos muito específicos de que precisavam.
Mas o Google era ruim em entender as diferentes convenções de nomenclatura possíveis para esse tamanho: pesquisas como 8 mm por 10 mm, 8 x 10 mm, 8 mm x 10 mm estavam sendo tratadas como consultas de pesquisa quase totalmente diferentes.
Portanto, usamos nosso script n-grams para determinar qual dessas convenções de nomenclatura deu aos nossos produtos a melhor visibilidade.
Encontramos a melhor correspondência e fizemos as alterações em nosso feed de produtos. Como resultado, o tráfego para as campanhas de compras do cliente aumentou mais de 550% ao longo de um único mês.
A nomenclatura do produto é importante e os n-grams podem ajudá-lo com isso.
Scripts N-gram para Google Ads
Aqui estão os dois scripts completos.
Script N-grams para consultas de pesquisa do Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Script N-grams para analisar feeds de produtos
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Você também pode encontrar versões atualizadas do script n-grams no github para download.

Esses scripts são licenciados sob a licença Creative Commons BY SA 4.0, o que significa que você é livre para compartilhá-los e adaptá-los, mas recomendamos que você sempre compartilhe suas versões aprimoradas livremente para que todos possam usar. N-gramas são muito úteis para não serem compartilhados.
Esta é apenas uma das muitas ferramentas, scripts e modelos gratuitos que disponibilizamos aos membros do Ayima Insights Club. Você pode saber mais sobre o Insights Club e se inscrever gratuitamente aqui.