
Skrip Python Gratis untuk n-gram Google Ads
Diterbitkan: 2022-04-12N-gram dapat menjadi senjata yang signifikan untuk menganalisis kueri penelusuran di Google Ads atau SEO. Jadi, kami telah membuat skrip python gratis untuk membantu Anda menganalisis n-gram dengan panjang berapa pun di umpan produk dan kueri penelusuran Anda. Kami akan menjelaskan apa itu n-gram, dan bagaimana menggunakan n-gram untuk mengoptimalkan Google Ads Anda, khususnya untuk Google Shopping. Kami akhirnya akan menunjukkan cara menggunakan skrip n-gram gratis kami untuk meningkatkan hasil Google Ads Anda.
Apa itu n-gram?
N-gram adalah frasa dari N jumlah kata, ditarik dari badan teks yang lebih panjang. 'N' di sini dapat diganti dengan nomor apa pun.
Misalnya, dalam kalimat seperti "kucing melompat di atas tikar", "kucing melompat" atau "tikar" keduanya akan menjadi 2 gram (atau 'bi-gram').
"Kucing melompat" atau "kucing melompat" adalah contoh 3 gram (atau 'tri-gram') dari kalimat ini.
Bagaimana n-gram membantu permintaan pencarian
N-gram berguna dalam menganalisis kueri penelusuran dalam Google Ads karena frasa kunci tertentu dapat muncul di banyak kueri penelusuran yang berbeda.
N-gram memungkinkan kami menganalisis dampak frasa ini di seluruh inventaris Anda. Oleh karena itu, mereka memungkinkan Anda membuat keputusan dan pengoptimalan yang lebih baik dalam skala besar.
Bahkan memungkinkan kita untuk memahami dampak dari satu kata. Misalnya, jika Anda melihat kinerja yang lemah dengan penelusuran yang berisi kata "gratis" ('1 gram'), Anda mungkin memutuskan untuk menghapus kata tersebut dari semua kampanye.
Atau, kinerja yang kuat melalui kueri penelusuran yang berisi "dipersonalisasi" mungkin mendorong Anda untuk membuat kampanye khusus.
N-gram sangat berguna untuk melihat permintaan pencarian dari Google Shopping.
Sifat otomatis dari penargetan kata kunci Iklan Cantuman Produk berarti Anda dapat muncul untuk ratusan ribu kueri penelusuran. Apalagi jika Anda memiliki banyak varian produk dengan fitur yang sangat spesifik.
Skrip N-gram kami memungkinkan Anda memotong kekacauan itu menjadi frasa yang penting.
Menganalisis Kueri Penelusuran dengan n-gram
Kasus penggunaan pertama untuk n-gram adalah menganalisis kueri penelusuran.
Skrip python n-gram kami untuk Google Ads berisi petunjuk lengkap tentang cara menjalankannya, tetapi
kita akan membahas bagaimana mendapatkan hasil maksimal darinya.
- Anda harus menginstal python di mesin Anda untuk memulai. Jika tidak, sangat mudah. Anda pertama kali menginstal Anaconda. Kemudian, buka Anaconda Prompt dan ketik 'conda install jupyter lab'. Jupyter Lab adalah lingkungan di mana Anda akan menjalankan skrip ini.
Cukup unduh laporan kueri penelusuran dari Google Ads Anda. Sebaiknya siapkan sebagai laporan khusus di bagian 'laporan' di Google Ads. Anda bahkan dapat menyiapkan ini di tingkat PKS jika Anda ingin menjalankan skrip ini di beberapa akun.

3. Kemudian, cukup perbarui pengaturan dalam skrip untuk melakukan apa yang Anda inginkan, dan jalankan semua sel.
Ini akan memakan sedikit waktu untuk berlari, tetapi tetaplah bersabar. Anda akan melihat kemajuan yang diperbarui di bagian bawah karena keajaibannya.
Outputnya akan muncul sebagai file excel di dalam folder apa pun tempat Anda menjalankan skrip, kami sarankan menggunakan folder unduhan. File akan diberi label dengan nama apa pun yang Anda tentukan.
Setiap tab file excel berisi analisis n-gram yang berbeda. Sebagai contoh, berikut adalah analisis bi-gram:
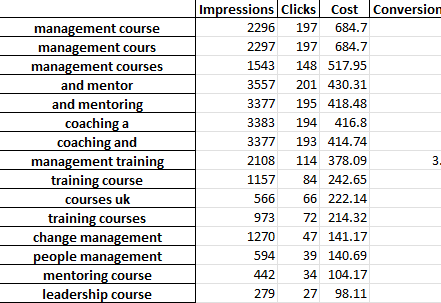
Ada beberapa cara Anda dapat menggunakan laporan ini untuk menemukan peningkatan.
Anda dapat memulai dengan frasa pembelanjaan tertinggi dan melihat outlier untuk CPA atau ROAS.
Memfilter laporan Anda ke non-konversi juga akan menyoroti area pengeluaran yang buruk.
Jika Anda melihat pengonversi yang buruk di tab satu kata, Anda dapat dengan mudah memeriksa konteks kata-kata yang digunakan di tab 3-Gram.
Misalnya, dalam akun pelatihan profesional, kami mungkin melihat bahwa 'Oxford' berkinerja buruk secara konsisten. Tab 3-Gram dengan cepat mengungkapkan bahwa pengguna cenderung mencari kursus yang lebih formal dan berorientasi universitas.
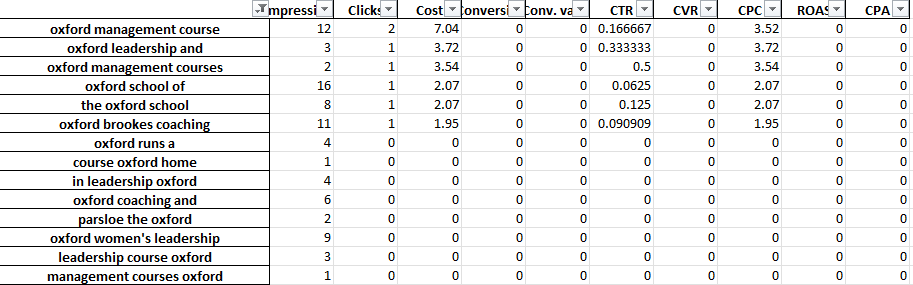
Karena itu, Anda dapat dengan cepat meniadakan kata ini.
Pada akhirnya, gunakan laporan ini dengan cara yang paling sesuai untuk Anda.
Mengoptimalkan feed produk dengan n-gram
Skrip n-gram kedua kami untuk Google Ads menganalisis performa produk Anda.
Sekali lagi, Anda dapat menemukan instruksi lengkap di dalam skrip itu sendiri
Skrip ini melihat kinerja frasa dalam judul produk Anda. Bagaimanapun juga, judul produk menentukan sebagian besar kata kunci yang Anda tampilkan. Judul juga merupakan salinan iklan utama Anda. Oleh karena itu, judul sangat penting.
Skrip ini dirancang untuk membantu Anda menemukan frasa potensial dalam judul-judul ini yang dapat Anda sesuaikan untuk meningkatkan kinerja Anda dari Google Belanja.
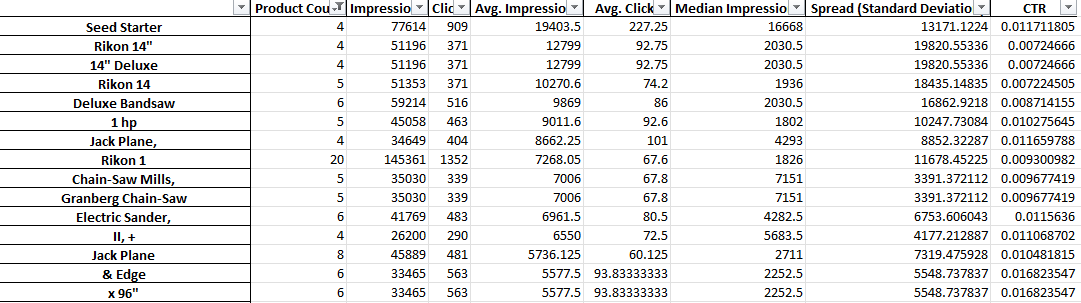
Seperti yang Anda lihat di atas, output dari skrip ini sedikit berbeda. Karena keterbatasan API pelaporan Google, Anda tidak dapat mengakses metrik konversi (seperti pendapatan) saat Anda berada di tingkat judul produk.
Oleh karena itu, laporan ini memberi Anda jumlah produk, lalu lintas rata-rata, dan penyebaran (standar deviasi) dari frasa produk.
Karena didasarkan pada visibilitas, Anda dapat menggunakan laporan untuk mengidentifikasi frasa yang cenderung membuat produk Anda lebih terlihat. Anda kemudian dapat menambahkan ini ke lebih banyak judul produk Anda.

Misalnya, kami mungkin menemukan frasa dengan jumlah tayangan rata-rata yang sangat tinggi dan yang muncul dalam judul beberapa produk. Ini juga memiliki standar deviasi yang rendah - artinya tidak mungkin hanya ada satu produk luar biasa yang mencondongkan angka kami di sini.
Kami menggunakan alat ini untuk secara dramatis memperluas visibilitas belanja untuk klien. Klien menjual produk dalam ribuan ukuran berbeda. Misalnya 8x10mm. Orang-orang juga berbelanja untuk ukuran yang sangat spesifik yang mereka butuhkan.
Namun, Google buruk dalam memahami kemungkinan konvensi penamaan yang berbeda untuk ukuran ini: Penelusuran seperti 8mm kali 10mm, 8 x 10mm, 8mm x 10mm semuanya diperlakukan sebagai kueri penelusuran yang hampir sepenuhnya berbeda.
Oleh karena itu, kami menggunakan skrip n-gram kami untuk menentukan konvensi penamaan mana yang memberikan produk kami visibilitas terbaik.
Kami menemukan yang paling cocok dan membuat perubahan pada umpan produk kami. Akibatnya, lalu lintas ke kampanye belanja klien melonjak lebih dari 550% selama satu bulan.
Masalah penamaan produk dan n-gram dapat membantu Anda dalam hal itu.
Skrip N-gram untuk Google Ads
Berikut skrip lengkap keduanya.
Skrip N-gram untuk kueri penelusuran Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Skrip N-gram untuk menganalisis umpan produk
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()Anda juga dapat menemukan versi terbaru dari skrip n-gram di github untuk diunduh.

Skrip ini dilisensikan di bawah lisensi Creative Commons BY SA 4.0, artinya Anda bebas untuk berbagi dan mengadaptasinya, tetapi kami mendorong Anda untuk selalu membagikan versi yang ditingkatkan secara bebas untuk digunakan semua orang. N-gram terlalu berguna untuk tidak dibagikan.
Ini hanyalah salah satu dari banyak alat, skrip, dan template gratis yang kami sediakan untuk anggota Ayima Insights Club. Anda dapat mempelajari lebih lanjut tentang Klub Wawasan, dan mendaftar secara gratis di sini.