
Script Python gratuit pentru Google Ads n-grams
Publicat: 2022-04-12N-gramele pot fi o armă importantă pentru analiza interogărilor de căutare pe Google Ads sau SEO. Așadar, am produs un script python gratuit pentru a vă ajuta să analizați n-grame de orice lungime atât în fluxul de produse, cât și în interogările de căutare. Vă vom explica ce sunt n-gramele și cum să folosiți n-gramele pentru a vă optimiza anunțurile Google, în special pentru Cumpărături Google. În sfârșit, vă vom arăta cum să utilizați scriptul nostru gratuit n-grams pentru a vă îmbunătăți rezultatele Google Ads.
Ce sunt n-gramele?
N-gramele sunt expresii cu un număr de N cuvinte, extrase din corpuri mai lungi de text. „N” de aici poate fi înlocuit cu orice număr.
De exemplu, într-o propoziție precum „pisica a sărit pe saltea”, „pisica a sărit” sau „covorașul” ar fi ambele de 2 grame (sau „bigrame”).
„Pisica a sărit” sau „pisica a sărit pe” sunt ambele exemple de 3 grame (sau „tri-grame”) din această propoziție.
Cum n-gramele ajută interogările de căutare
N-gramele sunt utile în analiza interogărilor de căutare în Google Ads, deoarece anumite expresii cheie pot apărea în multe interogări de căutare diferite.
N-gramele ne permit să analizăm impactul acestor expresii în întregul inventar. Prin urmare, vă permit să luați decizii și optimizări mai bune la scară.
Ne permite chiar să înțelegem impactul cuvintelor individuale. De exemplu, dacă ați observat o performanță slabă la căutările care conțin cuvântul „gratuit” (un „1 gram”), ați putea decide să refuzați acel cuvânt din toate campaniile.
Sau, performanța puternică prin interogări de căutare care conțin „personalizate” vă poate încuraja să creați o campanie dedicată.
N-gramele sunt deosebit de utile pentru a căuta interogări de căutare din Cumpărături Google.
Natura automatizată a direcționării prin cuvinte cheie pentru anunțurile cu afișare de produse înseamnă că puteți apărea pentru sute de mii de interogări de căutare. Mai ales atunci când aveți un număr mare de variante de produse cu caracteristici foarte specifice.
Scriptul nostru N-grams vă permite să treceți prin această dezordine la frazele care contează.
Analizarea interogărilor de căutare cu n-grame
Primul caz de utilizare pentru n-grame este analiza interogărilor de căutare.
Scriptul nostru n-grams python pentru Google Ads conține instrucțiuni complete despre cum să îl rulați, dar
vom analiza cum să profităm la maximum de ea.
- Va trebui să aveți instalat python pe computer pentru a începe. Dacă nu, este foarte ușor. Mai întâi instalați Anaconda. Apoi, deschideți Anaconda Prompt și tastați „conda install jupyter lab”. Jupyter Lab este mediul în care veți rula acest script.
Pur și simplu descărcați un raport privind interogările de căutare din Google Ads. Vă recomandăm să îl configurați ca raport personalizat în secțiunea „rapoarte” din Google Ads. Puteți chiar să configurați acest lucru la nivel MCC dacă doriți să rulați acest script pe mai multe conturi.

3. Apoi, actualizați doar setările din script pentru a face ceea ce doriți și rulați toate celulele.
Va dura puțin timp pentru a alerga, dar răbdați. Veți vedea progresul fiind actualizat în partea de jos, pe măsură ce își face magia.
Ieșirea va apărea ca un fișier Excel în orice folder în care rulați scriptul, vă recomandăm să utilizați folderul de descărcări. Fișierul va fi etichetat cu orice nume definit.
Fiecare filă a fișierului Excel conține o analiză n-gram diferită. De exemplu, iată o analiză bi-gramă:
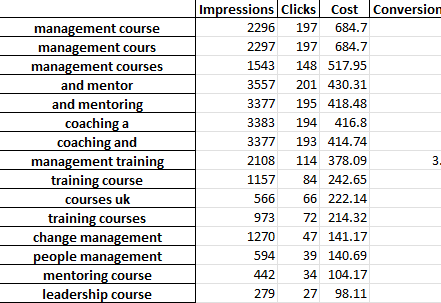
Există mai multe moduri în care puteți utiliza acest raport pentru a găsi îmbunătățiri.
Puteți începe cu cele mai mari expresii de cheltuieli și puteți analiza orice valori aberante pentru CPA sau rentabilitatea cheltuielilor publicitare.
Filtrarea rapoartelor dvs. către persoanele care nu fac conversie va evidenția, de asemenea, domeniile cu cheltuieli slabe.
Dacă vedeți convertoare slabe în fila cu cuvinte simple, puteți verifica cu ușurință în ce context sunt folosite cuvintele în fila 3 grame.
De exemplu, într-un cont de formare profesională, am putea observa că „Oxford” are în mod constant performanțe slabe. Fila de 3 grame dezvăluie rapid că utilizatorii sunt probabil să caute un curs mai formal, orientat spre universitate.
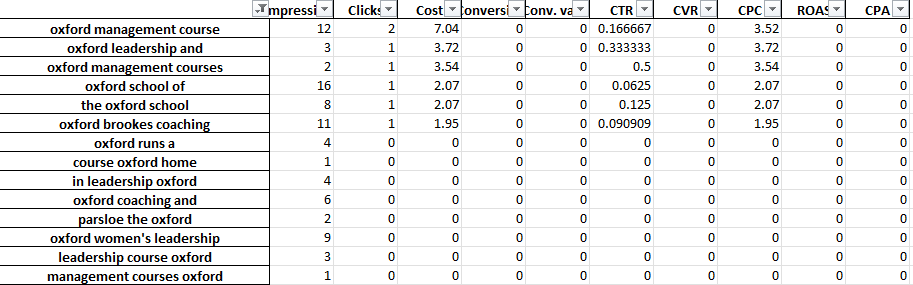
Prin urmare, puteți nega rapid acest cuvânt.
În cele din urmă, utilizați acest raport, oricum funcționează cel mai bine pentru dvs.
Optimizarea fluxurilor de produse cu n-grame
Al doilea script n-grame pentru Google Ads analizează performanța produsului dvs.
Din nou, puteți găsi instrucțiuni complete în scriptul în sine
Acest script analizează performanța expresiilor din titlurile produselor dvs. La urma urmei, titlul produsului determină într-o mare măsură pentru ce cuvinte cheie apari. Titlul este, de asemenea, copia dvs. principală a anunțului. Prin urmare, titlurile sunt incredibil de importante.
Scriptul este conceput pentru a vă ajuta să găsiți expresii potențiale în aceste titluri pe care le puteți adapta pentru a vă îmbunătăți performanța din Cumpărături Google.
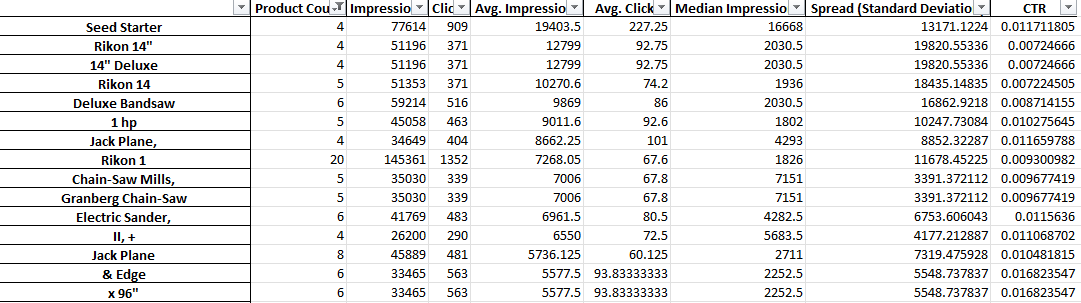
După cum puteți vedea mai sus, rezultatul acestui script este puțin diferit. Din cauza limitărilor API-ului de raportare Google, nu puteți accesa valorile de conversie (cum ar fi venitul) cât timp vă aflați la nivelul titlului produsului.
Prin urmare, acest raport vă oferă numărul de produse, traficul mediu și răspândirea (abaterea standard) a frazelor de produs.
Deoarece se bazează pe vizibilitate, puteți utiliza raportul pentru a identifica expresii care pot face produsele dvs. mai vizibile. Apoi le puteți adăuga la mai multe titluri de produse.

De exemplu, am putea găsi o expresie cu un număr foarte mare de afișări medii și care apare în titlul mai multor produse. Are, de asemenea, o abatere standard scăzută - ceea ce înseamnă că nu este probabil să existe un singur produs uimitor care să ne modifice cifrele aici.
Am folosit acest instrument pentru a extinde dramatic vizibilitatea cumpărăturilor pentru un client. Clientul a vândut produse în mii de dimensiuni diferite. De exemplu 8x10mm. Oamenii făceau, de asemenea, cumpărături pentru dimensiuni foarte specifice de care aveau nevoie.
Dar, Google a fost prost în a înțelege diferitele convenții posibile de denumire pentru această dimensiune: căutări precum 8 mm pe 10 mm, 8 x 10 mm, 8 mm x 10 mm au fost toate tratate ca interogări de căutare aproape complet diferite.
Prin urmare, am folosit scriptul nostru n-grams pentru a determina care dintre aceste convenții de denumire a oferit produselor noastre cea mai bună vizibilitate.
Am găsit cea mai bună potrivire și am făcut modificările fluxului nostru de produse. Drept urmare, traficul către campaniile de cumpărături ale clientului a crescut cu peste 550% pe parcursul unei singure luni.
Numele produselor contează și n-gramele vă pot ajuta în acest sens.
Scripturi N-gram pentru Google Ads
Iată ambele scripturi complete.
Script N-grame pentru interogări de căutare Google Ads
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()Script N-grame pentru analiza fluxurilor de produse
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()De asemenea, puteți găsi versiuni actualizate ale scriptului n-grams pe github pentru a le descărca.

Aceste scripturi sunt licențiate sub licența Creative Commons BY SA 4.0, ceea ce înseamnă că sunteți liber să le partajați și să le adaptați, dar vă încurajăm să distribuiți întotdeauna versiunile îmbunătățite în mod liber pentru ca toată lumea să le poată utiliza. N-gramele sunt prea utile pentru a nu partaja.
Acesta este doar unul dintre numeroasele instrumente, scripturi și șabloane gratuite pe care le punem la dispoziție membrilor Ayima Insights Club. Puteți afla mai multe despre Insights Club și vă puteți înscrie gratuit aici.