
Google Ads n-gram용 무료 Python 스크립트
게시 됨: 2022-04-12N-gram은 Google Ads 또는 SEO에서 검색어를 분석하는 데 중요한 무기가 될 수 있습니다. 따라서 제품 피드와 검색어 모두에서 길이에 상관없이 n-gram을 분석하는 데 도움이 되는 무료 Python 스크립트를 제작했습니다. n-gram이 무엇인지, 특히 Google 쇼핑을 위해 Google Ads를 최적화하기 위해 n-gram을 사용하는 방법을 설명합니다. 마지막으로 무료 n-grams 스크립트를 사용하여 Google Ads 결과를 개선하는 방법을 보여드리겠습니다.
n-그램이란 무엇입니까?
N-gram은 더 긴 본문에서 추출한 N개의 단어로 구성된 구입니다. 여기서 'N'은 임의의 숫자로 대체될 수 있습니다.
예를 들어, "cat jumped on the mat"와 같은 문장에서 "cat jumped" 또는 "mat"는 둘 다 2그램(또는 '바이그램')이 됩니다.
"cat jumped" 또는 "cat jumped on"은 모두 이 문장에서 3그램(또는 '트라이그램')의 예입니다.
n-gram이 검색 쿼리에 도움이 되는 방법
N-gram은 특정 핵심 문구가 다양한 검색어에 나타날 수 있기 때문에 Google Ads 내에서 검색어를 분석하는 데 유용합니다.
N-gram을 사용하면 전체 인벤토리에서 이러한 문구의 영향을 분석할 수 있습니다. 따라서 더 나은 결정을 내리고 대규모로 최적화할 수 있습니다.
그것은 심지어 우리가 한 단어의 영향을 이해할 수 있게 해줍니다. 예를 들어 "무료"('1그램')라는 단어가 포함된 검색에서 실적이 저조한 경우 모든 캠페인에서 해당 단어를 제외하기로 결정할 수 있습니다.
또는 "맞춤형"이 포함된 검색어를 통한 강력한 실적은 전용 캠페인을 구축하도록 권장할 수 있습니다.
N-gram은 특히 Google 쇼핑의 검색어를 조회하는 데 유용합니다.
제품 목록 광고 키워드 타겟팅의 자동화된 특성으로 인해 수십만 개의 검색어에 대해 노출될 수 있습니다. 특히 매우 구체적인 기능을 가진 많은 수의 제품 변형이 있는 경우.
N-grams 스크립트를 사용하면 복잡한 내용을 중요한 문구로 잘라낼 수 있습니다.
n-gram으로 검색어 분석하기
n-gram의 첫 번째 사용 사례는 검색 쿼리를 분석하는 것입니다.
Google Ads용 n-grams python 스크립트에는 실행 방법에 대한 전체 지침이 포함되어 있지만
최대한 활용하는 방법에 대해 알아보겠습니다.
- 시작하려면 컴퓨터에 Python이 설치되어 있어야 합니다. 그렇지 않은 경우 매우 쉽습니다. 먼저 아나콘다를 설치합니다. 그런 다음 Anaconda Prompt를 열고 'conda install jupyter lab'을 입력합니다. Jupyter Lab은 이 스크립트를 실행할 환경입니다.
Google Ads에서 검색어 보고서를 다운로드하기만 하면 됩니다. Google Ads의 '보고서' 섹션에서 맞춤 보고서로 설정하는 것이 좋습니다. 여러 계정에서 이 스크립트를 실행하려는 경우 MCC 수준에서 이를 설정할 수도 있습니다.

3. 그런 다음 스크립트의 설정을 업데이트하여 원하는 작업을 수행하고 모든 셀을 실행합니다.
실행하는 데 약간의 시간이 걸리지만 인내심을 가지십시오. 마법처럼 아래쪽에 진행 상황이 업데이트되는 것을 볼 수 있습니다.
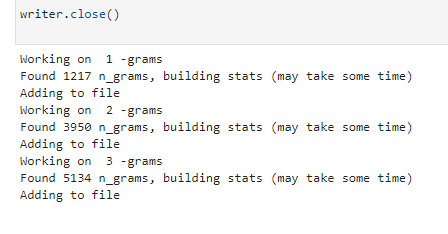
출력은 다운로드 폴더 사용을 제안하는 스크립트를 실행 중인 폴더 내에서 엑셀 파일로 나타납니다. 파일에는 사용자가 정의한 이름으로 레이블이 지정됩니다.
Excel 파일의 각 탭에는 다른 n-gram 분석이 포함되어 있습니다. 예를 들어 다음은 바이그램 분석입니다.
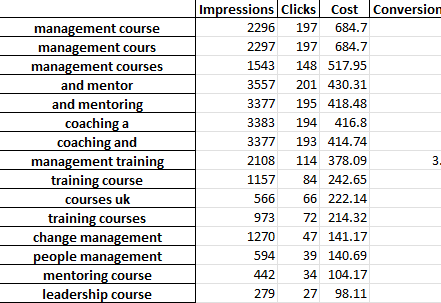
이 보고서를 사용하여 개선 사항을 찾을 수 있는 여러 가지 방법이 있습니다.
가장 높은 지출 문구부터 시작하여 CPA 또는 ROAS에 대한 이상값을 확인할 수 있습니다.
보고서를 비전환으로 필터링하면 지출이 적은 영역도 강조표시됩니다.
단일 단어 탭에 잘못된 변환기가 표시되면 3-Gram 탭에서 해당 단어가 사용된 컨텍스트를 쉽게 확인할 수 있습니다.
예를 들어, 전문 교육 계정에서 'Oxford'의 실적이 지속적으로 저조한 것을 발견할 수 있습니다. 3-Gram 탭은 사용자가 보다 형식적이고 대학 지향적인 과정을 찾고 있을 가능성이 있음을 빠르게 보여줍니다.
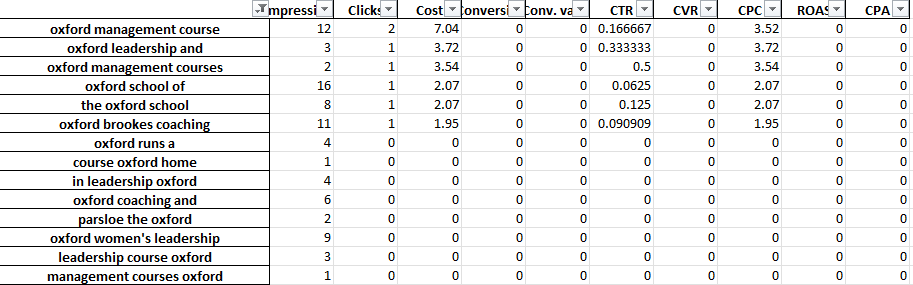
따라서 이 단어를 빠르게 부정할 수 있습니다.
궁극적으로 이 보고서를 사용하는 것이 가장 좋습니다.
n-gram으로 제품 피드 최적화
Google Ads용 두 번째 n-gram 스크립트는 제품 실적을 분석합니다.
다시 말하지만 스크립트 자체 내에서 전체 지침을 찾을 수 있습니다.
이 스크립트는 제품 제목 내 문구의 성능을 확인합니다. 결국 제품 제목은 귀하가 표시하는 키워드를 크게 결정합니다. 제목은 기본 광고 카피이기도 합니다. 따라서 제목은 매우 중요합니다.
스크립트는 이러한 제목에서 Google 쇼핑 실적을 개선하기 위해 조정할 수 있는 잠재적인 문구를 찾는 데 도움이 되도록 설계되었습니다.
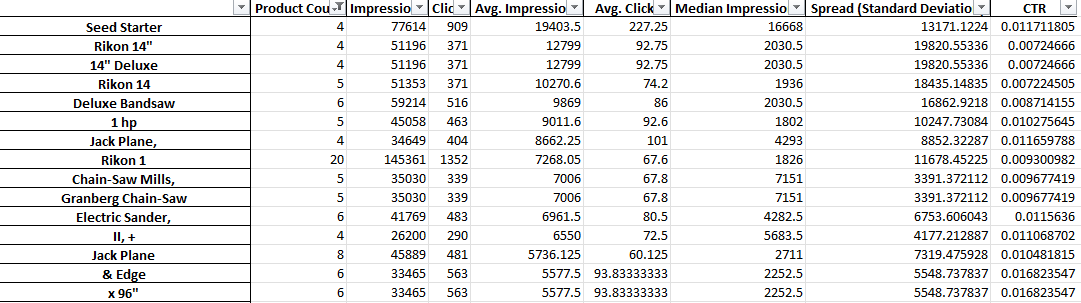
위에서 볼 수 있듯이 이 스크립트의 출력은 약간 다릅니다. Google 보고 API의 제한으로 인해 제품 제목 수준에 있는 동안에는 수익과 같은 전환 측정항목에 액세스할 수 없습니다.
따라서 이 보고서는 제품 수, 평균 트래픽 및 제품 문구의 확산(표준 편차)을 제공합니다.
가시성을 기반으로 하기 때문에 보고서를 사용하여 제품을 더 잘 보이게 할 수 있는 문구를 식별할 수 있습니다. 그런 다음 더 많은 제품 제목에 추가할 수 있습니다.

예를 들어, 평균 노출 수가 매우 많고 여러 제품의 제목에 나타나는 문구를 찾을 수 있습니다. 또한 표준 편차가 낮습니다. 즉, 여기서 우리의 수치를 왜곡하는 놀라운 제품이 단 하나뿐일 가능성이 없습니다.
우리는 이 도구를 사용하여 고객의 쇼핑 가시성을 극적으로 확장했습니다. 클라이언트는 수천 가지 크기의 제품을 판매했습니다. 예를 들어 8x10mm. 사람들은 또한 그들이 필요로 하는 매우 특정한 크기를 쇼핑하고 있었습니다.
그러나 Google은 이 크기에 대해 가능한 다른 명명 규칙을 이해하지 못했습니다. 8mm x 10mm, 8 x 10mm, 8mm x 10mm와 같은 검색은 모두 거의 완전히 다른 검색어로 취급되었습니다.
따라서 우리는 n-gram 스크립트를 사용하여 이러한 명명 규칙 중 어떤 것이 우리 제품에 가장 좋은 가시성을 제공하는지 결정했습니다.
가장 일치하는 항목을 찾아 제품 피드를 변경했습니다. 그 결과 고객의 쇼핑 캠페인에 대한 트래픽이 한 달 동안 550% 이상 급증했습니다.
제품 명명 문제와 n-gram이 도움이 될 수 있습니다.
Google Ads용 N-gram 스크립트
다음은 두 개의 완전한 스크립트입니다.
Google Ads 검색어용 N-gram 스크립트
#!/usr/bin/env python #coding: utf-8 # Ayima N-Grams Script for Google Ads #Takes in SQR data and outputs data split into phrases of N length #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ### Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Search term #+ Campaign #+ Campaign state #+ Currency code #+ Impressions #+ Clicks #+ Cost #+ Conversions #+ Conv. value #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ### Settings # First, enter the name of the file to run this script on # By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "N-Grams input - SQR (2).csv" grams_to_run = [1,2,3] #What length phrases you want to retrieve for. Recommended is < 4 max. Longer phrases retrieves far more results. campaigns_to_exclude = "" #input strings contained by campaigns you want to EXCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive campaigns_to_include = "PLA" #input strings contained by campaigns you want to INCLUDE, separated by commas if multiple (eg "DSA,PLA"). Case Insensitive character_limit = 3 #minimum number of characters in an ngram eg to filter out "a" or "i". Will filter everything below this limit client_name = "SAMPLE CLIENT" #Client name, to label on the final file enabled_campaigns_only = False #True/False - Whether to only run the script for enabled campaigns impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing brand_terms = ["BRAND_TERM_2", #Labels brand and non-brand search terms. You can add as many as you want. Case insensitive. If none, leave as [""] "BRAND_TERM_2"] #eg ["Adidas","Addidas"] ## The Script #### You should not need to make changes below here import pandas as pd from nltk import ngrams import numpy as np import time import re def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",") df = read_file(file_name) def filter_campaigns(df, to_ex = campaigns_to_exclude,to_inc = campaigns_to_include): to_ex = to_ex.split(",") to_inc = to_inc.split(",") if to_inc != ['']: to_inc = [word.lower() for word in to_inc] df = df[df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_inc))] if to_ex != ['']: to_ex = [word.lower() for word in to_ex] df = df[~df["Campaign"].str.lower().str.strip().str.contains('|'.join(to_ex))] if enabled_campaigns_only: try: df = df[df["Campaign state"].str.contains("Enabled")] except KeyError: print("Couldn't find 'Campaign state' column") return df def generate_ngrams(list_of_terms, n): """ Turns a list of search terms into a set of unique n-grams that appear within """ # Clean the terms up first and remove special characters/commas etc. #clean_terms = [] #for st in list_of_terms: #st = st.strip() #clean_terms.append(re.sub(r'[^a-zA-Z0-9\s]', '', st)) #split into grams unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams] all_grams = set([' '.join(tups) for tups in unique_ngrams]) if character_limit > 0: n_grams_list = [ngram for ngram in all_grams if len(ngram) > character_limit] return n_grams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df["Search term"].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data =list(np.sum(sliced_df[[impressions_column_name,"Clicks","Cost","Conversions","Conv. value"]])) return raw_data def _generate_metrics(df): #generate metrics try: df["CTR"] = df["Clicks"]/df[f"Impressions"] df["CVR"] = df["Conversions"]/df["Clicks"] df["CPC"] = df["Cost"]/df["Clicks"] df["ROAS"] = df[f"Conv. value"]/df["Cost"] df["CPA"] = df["Cost"]/df["Conversions"] except KeyError: print("Couldn't find a column") #replace infinites with NaN and replace with 0 df.replace([np.inf, -np.inf], np.nan, inplace=True) df.fillna(0, inplace= True) df.round(2) return df def build_ngrams_df(df, sq_column_name ,ngrams_list, character_limit = 0): """Takes in n-grams and df and returns df of those metrics df - dataframe in question sq_column_name - str. Name of the column containing search terms ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams Outputs a dataframe """ #set up metrics lists to drop values array = [] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #turn the above into a dataframe columns = ["Impressions","Clicks","Cost","Conversions", "Conv. value"] ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list), dtype = float) ngrams_ df.sort_values(by = "Cost", ascending = False, inplace = True) #calculate additional metrics and return return _generate_metrics(ngrams_df) def group_by_sqs(df): df = df.groupby("Search term", as_index = False).sum() return df df = group_by_sqs(df) def find_brand_terms(df, brand_terms = brand_terms): brand_terms = [str.lower(term) for term in brand_terms] st_brand_bool = [] for i, row in df.iterrows(): term = row["Search term"] #runs through the term and if any of our brand strings appear, labels the column brand if any([brand_term in term for brand_term in brand_terms]): st_brand_bool.append("Brand") else: st_brand_bool.append("Generic") return st_brand_bool df["Brand label"] = find_brand_terms(df) #This is necessary for larger search volumes to cut down the very outlier terms with extremely few searches i = 1 while len(df)> 40000: print(f"DF too long, at {len(df)} rows, filtering to impressions greater than {i}") df = df[df[impressions_column_name] > i] i+=1 writer = pd.ExcelWriter(f"Ayima N-Gram Script Output - {client_name} N-Grams.xlsx", engine='xlsxwriter') df.to_excel(writer, sheet_name='Raw Searches') for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Search term"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Search term", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) writer.close()제품 피드 분석을 위한 N-gram 스크립트
#!/usr/bin/env python #coding: utf-8 # N-Grams for Google Shopping #This script looks to find patterns and trends in product feed data for Google shopping. It will help you find what words and phrases have been performing best for you #Script produced by Ayima Limited (www.ayima.com) # 2022. This work is licensed under a CC BY SA 4.0 license (https://creativecommons.org/licenses/by-sa/4.0/). #Version 1.1 ## Instructions #Download an SQR from within the reports section of Google ads. #The report must contain the following metrics: #+ Item ID #+ Product title #+ Impressions #+ Clicks #Then, complete the setting section as instructed and run the whole script #The script may take some time. Ngrams are computationally difficult, particularly for larger accounts. But, give it enough time to run, and it will log if it is running correctly. ## Settings #First, enter the name of the file to run this script on #By default, the script only looks in the folder it is in for the file. So, place this script in your downloads folder for ease. file_name = "Product report for N-Grams (1).csv" grams_to_run = [1,2,3] #The number of words in a phrase to run this for (eg 3 = three-word phrases only) character_limit = 0 #Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols title_column_name = "Product Title" #Name of our product title column desc_column_name = "" #Name of our product description column, if we have one file_label = "Sample Client Name" #The label you want to add to the output file (eg the client name, or the run date) impressions_column_name = "Impr." #Google consistently flip between different names for their impressions column. We think just to annoy us. This spelling was correct at time of writing client_name = "SAMPLE" ## The Script #### You should not need to make changes below here #First import all of the relevant modules/packages import pandas as pd from nltk import ngrams import numpy as np import time import re #import our data file def read_file(file_name): #find the file format and import if file_name.strip().split('.')[-1] == "xlsx": return pd.read_excel(f"{file_name}",skiprows = 2, thousands =",") elif file_name.strip().split('.')[-1] == "csv": return pd.read_csv(f"{file_name}",skiprows = 2, thousands =",")# df = read_file(file_name) df.head() def generate_ngrams(list_of_terms, n): """ Turns our list of product titles into a set of unique n-grams that appear within """ unique_ngrams = set() for term in list_of_terms: grams = ngrams(term.split(" "), n) [unique_ngrams.add(gram) for gram in grams if ' ' not in gram] ngrams_list = set([' '.join(tups) for tups in unique_ngrams]) return ngrams_list def _collect_stats(term): #Slice the dataframe to the terms at hand sliced_df = df[df[title_column_name].str.match(fr'. {re.escape(term)}. ')] #add our metrics raw_data = [len(sliced_df), #number of products np.sum(sliced_df[impressions_column_name]), #total impressions np.sum(sliced_df["Clicks"]), #total clicks np.mean(sliced_df[impressions_column_name]), #average number of impressions np.mean(sliced_df["Clicks"]), #average number of clicks np.median(sliced_df[impressions_column_name]), #median impressions np.std(sliced_df[impressions_column_name])] #standard deviation return raw_data def build_ngrams_df(df, title_column_name, ngrams_list, character_limit = 0, desc_column_name = ''): """ Takes in n-grams and df and returns df of those metrics df - our dataframe title_column_name - str. Name of the column containing product titles ngrams_list - list/set of unique ngrams, already generated character_limit - Words have to be over a certain length, useful for single word grams to rule out tiny words/symbols desc_column_name = str. Name of the column containing product descriptions, if applicable Outputs a dataframe """ #first cut it to only grams longer than our minimum if character_limit > 0: ngrams_list = [ngram for ngram in ngrams_list if len(ngram) > character_limit] raw_data = map(_collect_stats, ngrams_list) #stack into an array data = np.array(list(raw_data)) #data[np.isnan(data)] = 0 columns = ["Product Count","Impressions","Clicks","Avg. Impressions", "Avg. Clicks","Median Impressions","Spread (Standard Deviation)"] #turn the above into a dataframe ngrams_df = pd.DataFrame(columns= columns, data=data, index = list(ngrams_list)) #clean the dataframe and add other key metrics ngrams_df["CTR"] = ngrams_df["Clicks"]/ ngrams_df["Impressions"] ngrams_df.fillna(0, inplace=True) ngrams_df.round(2) ngrams_df[["Impressions","Clicks","Product Count"]] = ngrams_df[["Impressions","Clicks","Product Count"]].astype(int) ngrams_df.sort_values(by = "Avg. Impressions", ascending = False, inplace = True) return ngrams_df writer = pd.ExcelWriter(f"{client_name} Product Feed N-Grams.xlsx", engine='xlsxwriter') start_time = time.time() for n in grams_to_run: print("Working on ",n, "-grams") n_grams = generate_ngrams(df["Product Title"], n) print(f"Found {len(n_grams)} n_grams, building stats (may take some time)") n_gram_df = build_ngrams_df(df,"Product Title", n_grams, character_limit) print("Adding to file") n_gram_df.to_excel(writer, sheet_name=f'{n}-Gram',) time_taken = time.time() - start_time print("Took "+str(time_taken) + " Seconds") writer.close()github에서 업데이트된 버전의 n-grams 스크립트를 다운로드하여 찾을 수도 있습니다.

이 스크립트는 Creative Commons BY SA 4.0 라이선스에 따라 사용이 허가되었습니다. 즉, 자유롭게 공유하고 조정할 수 있지만 항상 모든 사람이 사용할 수 있도록 개선된 버전을 자유롭게 공유할 것을 권장합니다. N-gram은 공유하지 않기에는 너무 유용합니다.
이것은 Ayima Insights Club 회원에게 제공되는 많은 무료 도구, 스크립트 및 템플릿 중 하나일 뿐입니다. Insights Club에 대해 자세히 알아보고 여기에서 무료로 가입할 수 있습니다.