
Extractions d'entités pour les graphiques de connaissances chez Google
Publié: 2019-02-15<
Google peut utiliser des extractions d'entités, des classes d'entités, des propriétés d'entités et des scores d'association à partir de pages pour créer des graphiques de connaissances
Lorsque Google a introduit le Knowledge Graph en 2012, il nous a dit qu'il allait commencer à se concentrer sur les choses et non sur les chaînes, et à indexer les objets du monde réel. Ce processus arrive à maturité, et nous avons la chance de voir Google apprendre comment commencer à explorer le Web pour extraire des données et s'engager dans des extractions d'entités, au lieu d'explorer des informations Web telles que des pages et des liens. Comme je l'ai écrit récemment sur Twitter à ce sujet :
Dans l'exploration Web, un nœud est une page et un bord est un lien entre les pages ; dans l'exploration de données, un nœud est une entité et un bord est une relation entre des entités. C'est une évolution dans la réflexion sur le web.
– Bill Slawski (@bill_slawski) 10 février 2019
Un brevet Google récemment accordé nous explique comment le moteur de recherche peut effectuer des extractions d'entités à partir de pages Web et stocker des informations à leur sujet. Cela va au-delà de l'utilisation des bases de connaissances comme sources d'informations sur les entités et va au-delà de ce qui peut être disponible dans de telles sources en examinant des passages textuels sur des pages Web. Cela signifie probablement que nous verrons des résultats de connaissances provenant de plus de sources que par le passé, telles que Wikipédia. Le problème que ce brevet résout dans cette première ligne du brevet :
Bases de connaissances conventionnelles, mais peuvent ne pas fournir des informations à jour ou fiables sur les entités et d'autres informations souhaitées par les utilisateurs.
Nous avons vu Google extraire des entités de tableaux et de listes délimitées par des deux-points à des endroits tels que Wikipedia et IMDB. Et s'ils pouvaient trouver ces informations sur des pages Web, extraire des entités de ces pages et collecter des propriétés et des attributs sur ces entités au fur et à mesure qu'ils exploraient les pages Web. Il peut exister des moyens d'évaluer les niveaux de confiance des informations sur ces entités et leur exactitude.

Comme le montrent ces images du brevet, Google calcule les scores d'association entre les entités et les attributs connectés (en savoir plus sur les scores d'association ci-dessous.)
J'ai écrit quelque chose de similaire dans l'article : Comment le Knowledge Graph de Google se met à jour en répondant aux questions. L'objectif de cet article était de savoir comment Google pourrait mettre à jour les graphiques de connaissances existants, plutôt que de trouver des informations sur les entités sur les pages Web et de les reconnaître, comment elles peuvent se joindre à d'autres classes d'entités. S'appuyer sur des bases de connaissances au lieu de traiter le Web comme une grande base de données semble être une étape partielle. S'il est possible d'effectuer des extractions d'entités de manière intelligente et utile, il ne serait pas nécessaire de dépendre d'une encyclopédie humaine modérée sur le Web. À quelques endroits dans le passé, Google avait déclaré qu'ils préféraient des approches évolutives sur le Web pour organiser les informations sur le Web (comme lorsqu'ils ont abandonné l'annuaire Google, qui provenait d'une source qui provenait de personnes.)
Ce brevet récent divulgue une approche différente qui aide Google à effectuer des extractions d'entités et d'autres informations sur ces entités, à partir de sources ajoutées au Web au lieu d'ajouter à une base de connaissances sur le Web, y compris de nouvelles pages Web et sources d'actualités.
Le brevet comporte une section récapitulative dans sa description où il nous renseigne sur le processus qu'il protège. Il les résume en quelques mots comme ceci :
Les modes de réalisation divulgués peuvent fournir des systèmes et des procédés pour déterminer des classes et des attributs de nouvelles entités, ainsi que des scores d'association reflétant des degrés de parenté et des niveaux de confiance dans les relations déterminées. Les modes de réalisation divulgués peuvent déterminer ces classes, attributs et scores associés sur la base des contextes lexicaux environnants dans lesquels les nouvelles entités apparaissent et des entités connues à proximité de chaque nouvelle entité. Des aspects des modes de réalisation décrits proposent également des systèmes et des procédés pour mettre à jour et stocker dynamiquement des relations déterminées en temps réel ou quasi réel .
Il les développe un peu plus en détail en nous donnant un aperçu étape par étape d'un processus qu'il appelle « Identifier les candidats d'entités ».
Identification des entités candidates pour les extractions d'entités
- Une entité candidate se trouve dans un document accessible sur un réseau.
- L'entité candidate détectée est une nouvelle entité basée sur un ou plusieurs modèles d'entité stockés dans une base de données.
- Une entité connue est à côté de la nouvelle entité et l'entité connue est dans le ou les modèles d'entité.
- Un contexte à côté de la nouvelle entité et de l'entité connue a une relation lexicale avec l'entité connue.
- Une seconde classe d'entité associée à l'entité connue et une classe de contexte est également associée au contexte.
- Une première classe d'entité se connecte à la nouvelle entité sur la base de la seconde classe d'entité et de la classe de contexte.
- Une première entrée dans la base de données dépend d'au moins un des modèles d'entités, l'entrée reflétant l'association entre la première classe d'entités et la nouvelle entité.
Le brevet dans lequel se trouvent ces candidats d'entités concerne les extractions d'entités et le stockage d'informations sur ces entités :
Systèmes et procédés informatisés d'extraction et de stockage d'informations concernant des entités
Inventeurs : Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli et David Lecomte
Cessionnaire : GOOGLE LLC
Brevet américain : 10 198 491
Accordé : 5 février 2019
Déposé : 6 juillet 2015
Résumé
L'invention concerne des systèmes et des procédés mis en œuvre par ordinateur pour extraire et stocker des informations concernant des entités à partir de documents, tels que des pages Web. Dans une mise en œuvre, un système est fourni qui détecte une entité candidate dans un document et détermine que le candidat détecté est une nouvelle entité. Le système détecte également une entité connue à proximité de l'entité connue sur la base du ou des modèles d'entité. Le système détecte également un contexte proche des entités nouvelles et connues ayant une relation lexicale avec l'entité connue. Le système détermine également une seconde classe d'entité associée à l'entité connue et une classe de contexte associée au contexte. Le système génère également une première classe d'entités sur la base de la seconde classe d'entités et de la classe de contexte. Le système génère également une entrée dans le ou les modèles d'entités reflétant une association entre la nouvelle et les premières entités.
Extractions d'entités - Entités, classes d'entités, instances d'entités et attributs d'entités
L'une des premières étapes du processus impliqué dans ce brevet consiste à reconnaître des entités. Le brevet fournit quelques informations sur ce que sont les entités et nous donne plusieurs exemples :
Dans certains aspects, une entité peut refléter une personne (par exemple, George Washington), un lieu (par exemple, San Francisco, Wyoming, une rue ou une intersection particulière, etc.) ou une chose (par exemple, une star, une voiture, un politicien, un médecin, un appareil , stade, personne, livre). À titre d'exemple supplémentaire, une entité peut refléter un document littéraire, une organisation (par exemple, les Yankees de New York), un organisme ou un parti politique, une entreprise, un organisme souverain ou gouvernemental (par exemple, les États-Unis, l'OTAN, la FDA , etc.), une date (par exemple, 4 juillet 1776), un nombre (par exemple, 60, 3.14159, e), une lettre, un état, une qualité, une idée, un concept ou toute combinaison de ceux-ci.
En plus de ces définitions d'une entité, on nous parle également des classes et sous-classes d'entités, et de la manière dont les entités peuvent s'intégrer dans différentes classes et sous-classes. Ceci est important car le moteur de recherche essaiera d'intégrer les entités dans différentes classes au fur et à mesure qu'il les apprend.
Alors, qu'est-ce qu'une classe ou une sous-classe d'entité ?
Le brevet les décrit en détail :
Dans certains aspects, une entité peut être associée à une classe d'entités. Une classe d'entités peut représenter une catégorisation, un type ou une classification d'un groupe ou d'un modèle notionnel d'entités. À des fins d'illustration, par exemple, les classes d'entités peuvent inclure « personne », « galaxie », « joueur de baseball », « arbre », « route », « politicien », etc. Une classe d'entités peut être associée à une ou plusieurs sous-classes . Dans certains aspects, une sous-classe peut refléter une classe d'entités subsumées dans une classe plus large (par exemple, une « superclasse »). Dans la liste de classes illustrative ci-dessus, par exemple, les classes « joueur de baseball » et « homme politique » peuvent être des sous-classes de la classe « personne », car tous les joueurs de baseball et les politiciens sont des êtres humains. Dans d'autres modes de réalisation, les sous-classes peuvent représenter des classes d'entités qui font presque entièrement, mais pas complètement, partie d'une superclasse plus grande. Un tel arrangement peut survenir dans des situations contenant des valeurs aberrantes ou des entités fictives. Par exemple, la classe « politicien » peut être une sous-classe de la classe « personne », même si certaines entités fictives sont des politiciens non humains (par exemple, « Mas Amedda »). Les modes de réalisation divulgués fournissent des moyens de traiter et de gérer ces types de relations, comme décrit plus en détail ci-dessous. Les classes et les sous-classes peuvent représenter des classes d'entités et peuvent constituer elles-mêmes des entités.
Une instance de données est un exemple d'entité spécifique qui s'intègre dans une classe ou une sous-classe. Thomas Jefferson est un exemple de « président américain » et « Mike Trout » est un exemple spécifique de « joueur de baseball professionnel ».
Le brevet fonctionne sur la collecte d'informations sur les entités, et il collecte des informations sur les entités qu'il appelle « attributs d'entité ». Comme dans ce dessin du brevet :

Celles-ci peuvent inclure des propriétés d'entités ainsi que des relations entre des classes d'entités. Le brevet fournit également un aperçu approfondi de ce qu'un attribut peut être :
Les entités peuvent être associées à un ou plusieurs attributs d'entité et/ou attributs d'objet. Un attribut d'entité peut refléter une propriété, un trait, une caractéristique, une qualité ou un élément d'une classe d'entité sous certains aspects. Dans certains aspects, chaque ou pratiquement chaque instance d'une classe d'entités partagera un ensemble commun d'attributs d'entité. Par exemple, l'entité « personne » peut être associée aux attributs d'entité « date de naissance », « lieu de naissance », « parents », « sexe » ou, en général, « a un attribut », entre autres. Dans un autre exemple, une entité « équipe sportive professionnelle » peut être associée à des attributs d'entité tels que « emplacement », « revenus annuels », « effectif », etc. Dans d'autres modes de réalisation, un attribut d'entité peut décrire comment une entité est liée à une autre entité. Par exemple, les attributs d'entité peuvent décrire des relations entre des classes d'entités telles que « est un », « est une sous-classe de » ou « est une superclasse de » ou « contient ». Par exemple, la classe "étoile" peut être associée à un attribut d'entité "est une sous-classe de" avec la classe d'entité "objet céleste".
En ce qui concerne les extractions d'entités, nous finissons par voir des paires clé-valeur utilisées pour nous en dire plus sur des entités spécifiques :
Dans certains aspects, un attribut d'objet peut refléter une relation entre une instance de classe d'entité avec une valeur d'attribut particulière. Par exemple, l'entité « George Washington » peut être associée à un attribut d'objet « a une date de naissance » avec une valeur « Feb. 22, 1732. Dans certains modes de réalisation, la valeur d'un attribut d'objet peut elle-même refléter une entité. Par exemple, dans l'exemple ci-dessus, la date « Feb. 22, 1732 » peut refléter une entité.
Cette approche de la collecte d'informations sur les entités comprend des attributs qui peuvent être communs aux sous-classes dans lesquelles celles-ci existent :
Dans certains modes de réalisation, les entités et les sous-classes héritent des attributs des superclasses dont elles dérivent. Par exemple, la classe "US President" peut hériter de l'attribut "birthdate" d'une superclasse "person". De plus, dans certains modes de réalisation, les superclasses n'héritent pas nécessairement des attributs de leurs sous-classes. À titre d'exemple, la classe « personne » n'hérite pas nécessairement de l'attribut « bases volées » de la sous-classe « joueur de baseball professionnel » ou de l'attribut « date d'occupation présumée » de la sous-classe « président des États-Unis ».
Bases de données contextuelles et extractions d'entités
J'ai reconnu les « Contextes » à partir de certains des schémas que j'ai vus dans le passé. Il y en a un qui est un vocabulaire Schema en attente, utilisant le terme « connaît », où vous pouvez l'utiliser pour décrire une personne agissant dans une profession spécifique comme ayant une expérience d'un certain type. Ces termes contextuels sont similaires car ils aident à fournir plus d'informations sur les entités qui vous donnent des informations à leur sujet. Le passage sur les bases de données contextuelles du brevet les décrit bien :
Dans certains modes de réalisation, la base de données de contextes peut stocker, relier, gérer et/ou fournir des informations associées à un ou plusieurs contextes. Un contexte peut refléter une construction ou une représentation lexicale d'un ou plusieurs mots (par exemple, un mot, une phrase, une clause, une phrase, un paragraphe, etc.) conférant un sens à un ou plusieurs mots (par exemple, une entité) à proximité. Dans certains modes de réalisation, un contexte est dans un n-gramme. Un n-gramme peut refléter une séquence de n mots, où n est un entier positif. Par exemple, un contexte peut inclure des 1-grammes tels que « est », « était » ou « concourre ». a volé la deuxième base » ou « a écrit une dissidence ». Les contextes (et les n-grammes) peuvent également inclure des espaces de n'importe quelle longueur, tels que le 2-gramme "de . . . jusqu'à . . . . " Comme décrit ici, un n-gramme peut représenter une telle séquence, et deux n-grammes n'ont pas besoin de représenter le nombre de mots du nom. Par exemple, « marqué un but » et « dans la dernière minute » peuvent tous deux constituer des n-grammes, bien qu'ils contiennent un nombre de mots différent.
L'apprentissage des entités et des contextes est une question d'apprentissage d'un vocabulaire significatif, car cela peut être utile lorsqu'il s'agit d'apprendre comment fonctionne le processus derrière ce brevet, et comment Google peut s'engager dans l'exploration de données pour extraire des informations sur les entités, leurs attributs, et les propriétés, et les contextes dans lesquels nous les voyons. Les contextes sont plus complexes qu'un simple n-gramme qui aide à fournir un contexte à une entité. Cette section suivante du brevet nous parle des classes de contexte et des entités de contexte :
Dans certains modes de réalisation, un contexte peut indiquer la présence potentielle d'une ou plusieurs entités. La ou les entités potentielles spécifiées par un contexte peuvent être appelées ici « classes de contexte » ou « entités de contexte ». Cependant, ces désignations sont uniquement à des fins d'illustration car elles ne sont pas destinées à être limitatives. Les classes de contexte peuvent refléter un ensemble de classes apparaissant typiquement en relation avec (par exemple, ayant une relation lexicale avec) le contexte. Dans certains aspects, les « classes de contexte » peuvent refléter des classes d'entités spécifiques. À titre d'exemple, le contexte « est marié à » peut être associé à une classe de contexte d'entité « personne », car le contexte « est marié à » a généralement une relation lexicale avec les êtres humains (par exemple, a une relation lexicale avec les instances de la classe « personne »). Dans cet exemple, par exemple, la phrase « Jack est marié à Jill » indique que « Jack » et « Jill » appartiennent à la classe « personne », en raison, au moins en partie, de la ou des classes de contexte du contexte. "Est marié à." Dans un autre exemple, le contexte « a un animal de compagnie » peut être associé à des classes de contexte telles que « animal », « chat, « chien », « animal domestique », etc. De plus, dans cet exemple alternatif, le contexte « a un animal de compagnie » peut signaler la présence de classes d'entités qui ne sont pas coextensives, car deux instances de la même classe ne partagent généralement pas de relation lexicale (par exemple, une relation d'attribut animal-maître) . L'interprétation et la génération des classes de contexte sont expliquées plus en détail ci-dessous.
Scores d'association impliquant des extractions d'entités
Le brevet donne plus de détails sur les classes de contexte et les entités de contexte, et celles-ci méritent d'être examinées plus en détail. Mais une section du brevet qui semblait valoir la peine d'être étudiée impliquait quelque chose qu'elle fait référence au calcul des scores d'association lors des extractions d'entités :
Dans certains aspects, la base de données d'entités et/ou la base de données de contexte peuvent également stocker des informations relatives à un ou plusieurs scores d'association. Un score d'association peut refléter une probabilité ou un degré de confiance qu'un attribut, une valeur d'attribut, une relation, une hiérarchie de classe, une classe de contexte désignée ou une autre association de ce type est valide, correcte et/ou légitime. Par exemple, dans certains modes de réalisation, un score d'association peut refléter un degré de relation entre deux entités ou un contexte et une entité. Les scores d'association peuvent être déterminés via n'importe quel processus compatible avec les modes de réalisation divulgués. Par exemple, comme expliqué plus en détail ci-dessous, un système informatique (par exemple, un serveur) peut déterminer les scores d'association en utilisant des facteurs et des pondérations tels que la fiabilité des sources à partir desquelles le score d'association est généré, la fréquence ou le nombre de cooccurrences entre deux entités dans le contenu (par exemple, en fonction du nombre total d'occurrences, le nombre total de documents contenant une ou les deux entités, etc.), les attributs des entités elles-mêmes (par exemple, si une entité est une sous-classe d'une autre), la récence des relations découvertes (par exemple, en donnant plus de poids aux associations plus récentes ou plus anciennes), si un attribut a une propension connue à fluctuer (par exemple, périodiquement ou sporadiquement), le nombre relatif d'instances entre les classes d'entités, la popularité des entités comme une paire, la proximité moyenne, médiane, statistique et/ou pondérée entre deux entités dans les documents analysés, et/ou tout autre processus divulgué ici. Dans certains aspects, le système peut lui-même générer un ou plusieurs scores d'association. Dans certains aspects, le système peut précharger un ou plusieurs scores d'association sur la base de structures de données prégénérées (par exemple, stockées dans les bases de données 140 et/ou 150).

Il est intéressant de noter que des éléments tels que la fiabilité des sources peuvent jouer un rôle dans les scores d'association attribués à une relation entre une entité ou un contexte et une entité. La section suivante examine ce qu'ils appellent « le rapport de cooccurrences entre un contexte et une entité » :
Dans un mode de réalisation, par exemple, un système informatique (par exemple, un serveur) peut générer un score d'association entre un contexte et une entité en déterminant le rapport de cooccurrences entre le contexte et l'entité (par exemple, l'entité spécifique, une instance de la classe d'entité, etc.) à toutes les occurrences de ce contexte et/ou de cette entité dans les documents du réseau. Une expression illustrative, par exemple, peut prendre la forme A=P(E, C)/P(C), où A est un exemple de valeur d'association entre l'entité et le contexte, P(C) est la probabilité de trouver le contexte dans une section de texte (par exemple, un document, une ou plusieurs pages Web, un corpus, etc.), et P(E, C) est la probabilité de trouver à la fois l'entité contextuelle dans la section. Dans cet exemple, le score d'association peut refléter la probabilité conditionnelle de trouver une entité E lorsque le contexte C apparaît. Une autre expression illustrative pour un score d'association peut prendre la forme de A=N(E, C)/(N(E)+N(C)-N(E, C)), où N(E) est le nombre d'instances l'entité apparaît dans une section (par exemple, un corpus), N(C) est le nombre d'instances où le contexte apparaît dans la section, et N(E, C) est le nombre d'instances de l'entité E et du contexte C apparaissent ensemble dans la rubrique. Des expressions similaires peuvent être utilisées pour générer des scores d'association entre deux entités.
Cet exemple de classes d'entités et de contextes spécifiques montre clairement comment les scores d'association peuvent aider à comprendre comment ces scores peuvent être utiles :
A titre d'exemple, le serveur peut déterminer que le contexte « reçoit une passe de » coexiste avec des instances des classes d'entités « basketteur » et « personne » 35 et 97 % du temps où le contexte apparaît dans tous les documents analysés, respectivement. Le système peut déterminer ces fréquences de cooccurrence en utilisant, au moins en partie, des modèles d'entité et de contexte pour déterminer les relations entre les entités (par exemple, pour déterminer « LeBron James » est une instance de la classe « joueur de basket »). Dans cet exemple, le serveur peut déterminer que les scores d'association reliant le contexte « reçoit une passe de » à « basketteur » et « personne » sont respectivement de 0,35 et de 0,97.
Notez que ces cooccurrences proviennent d'un corpus de documents, au lieu d'un.
Nous avons d'autres exemples d'autres facteurs qui peuvent jouer un rôle dans le calcul des scores d'association :
Les scores d'association peuvent tenir compte d'autres considérations en incorporant un ou plusieurs poids pour chaque occurrence d'une entité ou d'un contexte. Dans certains aspects, le système informatique peut appliquer des poids pour tenir compte de facteurs tels que les poids temporels (par exemple, pour peser plus lourdement les documents ou les occurrences récents), les poids de fiabilité (par exemple, pour peser plus lourdement les sources plus fiables), les poids de popularité (par exemple, pour peser plus lourdement des sources plus populaires), des poids de proximité (par exemple, pour peser plus lourdement des entités/contextes se produisant à proximité les uns des autres) et tout autre type de poids compatible avec les modes de réalisation divulgués. Dans certains aspects, un poids peut refléter l'importance relative d'un document particulier ou d'une occurrence individuelle par rapport à d'autres (par exemple, les poids pour toutes les occurrences totalisent 1,0), l'importance d'un document ou d'une occurrence sur une échelle absolue (par exemple, chaque poids reflète une évaluation indépendante), ou toute autre mesure indiquant la relation entre deux entités ou contextes (par exemple, la proximité entre un contexte et une entité).
Que peut signifier un score d'association faible ?
Ainsi, dans certains modes de réalisation, un score d'association faible peut indiquer qu'une source de données sur laquelle est basée une relation n'est généralement pas digne de confiance ou fiable. Dans d'autres modes de réalisation, un score d'association faible peut indiquer que des cooccurrences de la paire de sujets ne se produisent pas dans des documents récents. Dans encore d'autres modes de réalisation, un faible score d'association peut indiquer que les co-occurrences entre la paire sont rares (par exemple, peu de « politiciens » sont des « joueurs de basket-ball professionnels »). Dans encore d'autres modes de réalisation, le score d'association peut refléter une combinaison de plusieurs de ces facteurs. Dans certains aspects, un système (par exemple, un serveur ou un système informatique en relation avec des bases de données) peut mettre à jour et modifier les scores d'association au fil du temps (par exemple, sur la base de nouveaux documents, contextes et attributs).
Les scores d'association nous donnent une idée des vraisemblances :
Un score d'association peut prendre la forme d'un nombre numérique (par exemple, 0,0 à 1,0, 0 à 100, etc.), d'une échelle qualitative (par exemple, improbable, probable, très probable), autre mesure ou système de notation capable de spécifier les niveaux de diplôme. Par exemple, dans un mode de réalisation, une base de données d'entités peut stocker un score d'association de 0,84, reflétant que la probabilité que l'entité « Bryce Harper » soit associée à un attribut « date de naissance » ayant une valeur « Oct. 16, 1992. Cela peut indiquer, par exemple, que le système considère que la date de naissance de Bryce Harper est le 16 octobre 1992, avec une précision de 84 %. En outre, « Bryce Harper » peut être associé à une classe d'entités « personne » via l'attribut ou la relation « est un » avec un score d'association de 1,0, indiquant une certitude que Bryce Harper est une personne. Dans un autre exemple, le contexte « marqué un but » peut être associé aux classes de contexte « joueur de football », « joueur de hockey » et « personne » avec des scores d'association de 0,64, 0,49 et 0,98, respectivement. Ces valeurs exemplaires peuvent indiquer, par exemple, qu'il est plus probable que le contexte concerne les joueurs de football que les joueurs de hockey, et plus probablement encore que la phrase concerne une ou plusieurs personnes en général que les joueurs de football en particulier. Comme indiqué ci-dessus, la ou les bases de données d'entités (par exemple, la base de données d'entités) et les bases de données de contexte (par exemple, la base de données de contexte), le serveur et/ou le dispositif client peuvent stocker, générer, déterminer, archiver et indexer des entités, des attributs, des contextes, des classes de contexte, des scores d'association et toute autre information sous n'importe quelle forme compatible avec les modes de réalisation divulgués.
Graphes de connaissances avec scores d'association lors des extractions d'entités
Le brevet décrit un exemple de graphe de connaissances avec des scores d'association inclus avec chaque bord qui relie les entités à des attributs ou des valeurs :
Dans certains aspects, le graphe de connaissances peut comprendre une pluralité de nœuds, chaque nœud reflétant une entité. Le graphe de connaissances peut également comprendre une ou plusieurs arêtes reflétant des attributs décrivant des relations entre les entités et les valeurs d'attributs particuliers. Dans certains modes de réalisation, le graphe de connaissances peut également comprendre un score d'association pour chaque bord (par exemple, chaque attribut ou valeur associée) qu'il contient, bien que de tels scores d'association ne soient pas requis. Dans le graphique de connaissances illustratif représenté sur la Fig. 2A, par exemple, le nœud d'entité « Bryce Harper », reflétant une entité particulière, est connecté à une autre entité, « Washington Nationals », via l'attribut d'objet « joue pour » avec un score d'association de 0,96. Ces valeurs et relations peuvent indiquer, par exemple, que Bryce Harper est un joueur des Nationals de Washington et que le système associe cet attribut à un degré de confiance de 0,96. L'entité « Washington Nationals » elle-même peut être associée à d'autres entités non représentées, indiquées par les lignes en pointillés émanant du nœud. D'autres entités sont représentées sur les Fig. Les figures 2A-2C et 3 peuvent être associées de manière similaire à d'autres nœuds et attributs non représentés, et la description de certaines relations et valeurs y est simplement illustrative.
Les scores d'association peuvent fournir un sentiment de confiance dans l'exactitude d'un fait lié à une entité. Une autre série d'exemples liés à Bryce Harper :
FIGUE. 2A illustre également l'association du nœud « Bryce Harper » avec le nœud d'entité de date « Oct. 16, 1992" et le nœud d'entité de valeur "60 Home Runs" via les attributs "a un anniversaire" et "a un total de RH de carrière", respectivement. Ces attributs ont des scores d'association respectifs de 0,84 et 0,37, indiquant que le système est plus confiant dans la valeur associée à la relation d'attribut « a une date de naissance » que la valeur associée à « a un total de RH de carrière ». La différence dans ces scores d'association peut provenir, par exemple, de la fiabilité des sources utilisées pour générer de telles relations, de la fréquence des cooccurrences entre les entités, du fait qu'une des valeurs des attributs (nœud 204) est changeant au fil du temps, et/ou d'autres facteurs, conformément aux modes de réalisation divulgués.
Imaginez un énorme graphique de connaissances couvrant de nombreux types différents, chacun avec de nombreuses propriétés ou attributs qui leur sont associés, et des scores d'association fournissant des niveaux de confiance entre les entités et les classes et sous-classes. Le brevet nous montre que cela serait vraisemblablement :
Un nœud d'entité peut également être associé à des classes et sous-classes d'entités, connectées via des attributs décrivant la nature de la relation entre une entité et une classe d'entités. Par exemple, la Fig. 2A illustre les connexions entre le nœud « Bryce Harper » et les classes d'entités « personne » et « joueur de baseball professionnel » via les bords respectifs « est un » et « a une profession ». Ces attributs ont des scores d'association de 1,0 et 0,99, respectivement. Les attributs illustratifs et les scores d'association indiquent que le système considère Bryce Harper comme une personne dont la profession est un joueur de baseball professionnel avec certitude ou quasi-certitude.
Nous apprenons également des faibles scores d'association sur les classes d'entités et d'autres classes d'entités :
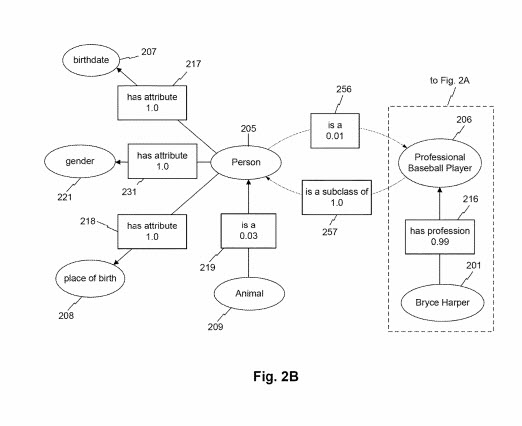
Comme représenté sur la Fig. 2B, une classe d'entité peut également être associée à d'autres classes d'entité par le biais d'attributs d'entité. Par exemple, la classe « animal » peut être associée à la classe « personne » via l'attribut « est un ». Dans cet exemple, le score d'association correspondant à l'attribut est de 0,03. Cela peut indiquer, par exemple, que les instances de la classe « animal » 209 sont des instances rares de la classe « personne » (par exemple, en raison de la prévalence d'animaux non humains tels que d'autres mammifères, insectes, oiseaux, poissons, etc.). Bien qu'il ne soit pas représenté sur la Fig. 2B, la classe « personne » peut être associée à un attribut réciproque « est un » ou « est une sous-classe de », etc., en relation avec le nœud « animal ». Un tel attribut peut être associé à un score d'association plus élevé (par exemple, 0,94), indiquant que la classe « personne » est une sous-classe d'« animal ». Par exemple, la Fig. 2B représente la classe « joueur de baseball professionnel » associée à la classe « personne » avec l'attribut d'entité « est une sous-classe de » avec un score d'association de 1,0. En revanche, le nœud de classe « personne » peut être associé au nœud « joueur de baseball professionnel » via l'attribut « est un » avec un score d'association de 0,01. Ce score d'association plus faible peut refléter, par exemple, la forte prévalence d'entités de la classe « personne » qui ne sont pas de la classe « joueur de baseball professionnel » (par exemple, la plupart des gens ne sont pas des joueurs de baseball professionnels). FIGUE. 2B décrit en outre comment le nœud de classe de joueur de baseball professionnel peut s'associer au nœud d'entité « Bryce Harper » via l'attribut « a une profession », comme discuté en relation avec la Fig. 2A.
Les associations entre les types d'entités et les classes de contexte dans un graphe contextuel peuvent nous fournir des informations spécifiques sur ces types d'entités et ces contextes :
Dans certains modes de réalisation, les classes d'entités incluses dans le graphe de contexte peuvent représenter des classes de contexte associées à un contexte particulier (par exemple, un contexte). Dans de tels modes de réalisation, un score d'association reliant les contextes à leurs classes de contexte (et toutes les sous-classes incluses, etc.) peut refléter un degré de validité ou de parenté entre la classe de contexte et le contexte (par exemple, bord) et/ou le degré de parenté entre les classes d'entités elles-mêmes (par exemple, edge). Dans certains aspects, le score d'association peut ainsi refléter une probabilité que le contexte signale la présence de la classe de contexte associée ou d'une instance de cette classe de contexte. Par exemple, comme le montre la Fig. En 2D, le nœud de contexte "reçoit(s) un passage de" peut être associé à cinq classes de contexte. Dans cet exemple, le contexte "reçois une passe de" est associé aux classes de contexte "personne", "joueur de baseball", "joueur de basket-ball", "joueur de hockey" et "joueur de football". Chacune de ces associations peut inclure un score d'association correspondant, tel que des scores. Ces scores d'association sont illustrés par la phrase d'accompagnement « prend une classe » pour indiquer une probabilité ou une probabilité que le contexte indique la présence d'une classe ou d'une instance de classe particulière.
Par exemple, comme il peut être rare qu'un membre de la classe « joueur de baseball » « reçoive(nt) une passe d'un autre joueur » (contexte), le score d'association associé à cette classe de contexte est de 0,02, comme indiqué dans l'élément de ligne . Comme expliqué ci-dessus, cette valeur peut être générée à partir de la fréquence des co-occurrences entre le contexte et une instance de la classe « joueur de baseball » sur les sources du réseau, la fiabilité de ces sources, etc. En revanche, les scores d'association entre le contexte et les autres classes d'entités sont relativement plus élevées. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019