
Wyodrębnianie jednostek do wykresów wiedzy w Google
Opublikowany: 2019-02-15<
Google może używać wyodrębniania jednostek, klas jednostek, właściwości jednostek i wyników powiązań ze stron do tworzenia grafów wiedzy
Kiedy Google wprowadził Graf wiedzy w 2012 roku, powiedział nam, że zacznie koncentrować się na rzeczach, a nie na ciągach, i indeksować obiekty świata rzeczywistego. Proces ten dojrzewa i mamy szansę obserwować, jak Google uczy się, jak zacząć indeksować sieć w celu wydobywania danych i angażowania się w wyodrębnianie jednostek, zamiast wyszukiwania informacji z sieci, takich jak strony i linki. Jak pisałem niedawno na Twitterze o tym:
W przeszukiwaniu sieci węzeł to strona, a krawędź to łącze między stronami; w przeszukiwaniu danych węzeł to jednostka, a krawędź to relacja między jednostkami. To ewolucja w myśleniu o sieci.
— Bill Sławski (@bill_slawski) 10 lutego 2019 r.
Niedawno przyznany patent Google mówi nam, w jaki sposób wyszukiwarka może przeprowadzać ekstrakcje jednostek ze stron internetowych i przechowywać informacje o nich. Wykracza to poza wykorzystywanie baz wiedzy jako źródeł informacji o podmiotach i przechodzi do znajdowania więcej niż to, co może być dostępne w takich źródłach, przeglądając fragmenty tekstowe na stronach internetowych. To prawdopodobnie oznacza, że będziemy widzieć wyniki wiedzy z większej liczby źródeł niż w przeszłości, takich jak Wikipedia. Problem, który ten patent rozwiązuje w tej wczesnej linii z patentu:
Konwencjonalne bazy wiedzy, ale mogą nie dostarczać aktualnych lub wiarygodnych informacji o podmiotach i innych informacji pożądanych przez użytkowników.
Widzieliśmy, jak Google wyodrębnia jednostki z tabel i list rozdzielanych dwukropkami w miejscach takich jak Wikipedia i IMDB. Co by było, gdyby mogli znaleźć te informacje na stronach WWW i wyodrębnić jednostki z tych stron oraz zebrać właściwości i atrybuty tych jednostek podczas przeszukiwania stron WWW. Mogą istnieć sposoby mierzenia poziomów zaufania informacji o tych podmiotach, a także ich poprawności.

Jak pokazano na tych obrazach z patentu, Google oblicza wyniki powiązań między podmiotami i powiązanymi atrybutami (więcej o wynikach powiązań poniżej).
O czymś podobnym pisałem w poście: Jak aktualizuje się wykres wiedzy Google, odpowiadając na pytania. W tym poście skupiono się na tym, jak Google może aktualizować istniejące wykresy wiedzy, zamiast znajdować informacje o podmiotach na stronach internetowych i rozpoznawać je, jak mogą łączyć się z innymi klasami podmiotów. Poleganie na bazach wiedzy zamiast traktowania sieci jako dużej bazy danych wydaje się być krokiem częściowym. Jeśli możliwe jest przeprowadzanie ekstrakcji bytów w inteligentny i użyteczny sposób, poleganie na moderowanej przez człowieka encyklopedii w sieci nie byłoby konieczne. W kilku miejscach w przeszłości Google powiedział, że preferuje metody skalowalne w sieci do organizowania informacji w sieci (np. gdy zaprzestali korzystania z Katalogu Google, który pochodził ze źródła pochodzącego od ludzi).
Ten niedawny patent ujawnia inne podejście, które pomaga Google w wyodrębnianiu jednostek i innych informacji o tych jednostkach ze źródeł dodanych do sieci zamiast dodawania do bazy wiedzy w sieci, w tym nowych stron internetowych i źródeł wiadomości.
W opisie patentu znajduje się sekcja podsumowująca, w której informuje nas o procesie, który chroni. Podsumowuje je w kilku słowach w ten sposób:
Ujawnione przykłady wykonania mogą zapewniać systemy i sposoby określania klas i atrybutów nowych jednostek, jak również wyniki powiązań odzwierciedlające stopnie pokrewieństwa i poziomy ufności w określonych powiązaniach. Ujawnione przykłady wykonania mogą określać te klasy, atrybuty i powiązane wyniki w oparciu o otaczające konteksty leksykalne, w których pojawiają się nowe jednostki i znane jednostki są w pobliżu każdej nowej jednostki. Aspekty ujawnionych przykładów wykonania zapewniają również systemy i sposoby dynamicznego aktualizowania i przechowywania określonych relacji w czasie rzeczywistym lub w czasie zbliżonym do rzeczywistego .
Rozwija je nieco bardziej szczegółowo, przedstawiając krok po kroku proces, który określa jako „Identyfikację kandydatów na jednostki”.
Identyfikowanie podmiotów kandydujących do wyodrębnienia podmiotów
- Kandydat na podmiot znajduje się w dokumencie dostępnym przez sieć.
- Wykryty kandydat encji to nowa encja oparta na co najmniej jednym modelu encji przechowywanym w bazie danych.
- Znana encja znajduje się obok nowej encji, a znana encja znajduje się w co najmniej jednym modelu encji.
- Kontekst obok nowej encji i znanej encji ma związek leksykalny ze znaną encją.
- Druga klasa jednostki skojarzona ze znaną jednostką i klasą kontekstu jest również skojarzona z kontekstem.
- Pierwsza klasa jednostki łączy się z nową jednostką na podstawie drugiej klasy jednostki i klasy kontekstu.
- Pierwszy wpis w bazie danych zależy od co najmniej jednego z modeli encji, wpis odzwierciedla powiązanie między pierwszą klasą encji a nową encją.
Patent, w którym znajdują się kandydaci podmiotu, dotyczy wyodrębniania podmiotu i przechowywania informacji o tych podmiotach:
Skomputeryzowane systemy i metody wydobywania i przechowywania informacji o podmiotach
Wynalazcy: Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli i David Lecomte
Pełnomocnik: GOOGLE LLC
Patent USA: 10.198,491
Przyznano: 5 lutego 2019 r.
Złożony: 6 lipca 2015 r.
Abstrakcyjny
Zaimplementowane komputerowo systemy i metody służą do wydobywania i przechowywania informacji dotyczących podmiotów z dokumentów, takich jak strony internetowe. W jednej implementacji dostarczany jest system, który wykrywa kandydata na podmiot w dokumencie i określa, że wykryty kandydat jest nowym podmiotem. System wykrywa również znaną jednostkę w pobliżu znanej jednostki w oparciu o jeden lub więcej modeli jednostek. System wykrywa również kontekst bliski nowej i znanej encji, mający związek leksykalny ze znaną encją. System określa również drugą klasę jednostki powiązaną ze znaną jednostką i klasę kontekstu powiązaną z kontekstem. System generuje również pierwszą klasę jednostki w oparciu o drugą klasę jednostki i klasę kontekstu. System generuje również wpis w jednym lub kilku modelach encji odzwierciedlający powiązanie między nową i pierwszą encją.
Wyodrębnianie encji — encje, klasy encji, instancje encji i atrybuty encji
Jednym z pierwszych kroków w procesie związanym z tym patentem jest rozpoznawanie podmiotów. Patent dostarcza pewnych informacji o tym, czym są podmioty i daje nam kilka przykładów:
W pewnych aspektach jednostka może odzwierciedlać osobę (np. George Washington), miejsce (np. San Francisco, Wyoming, konkretną ulicę lub skrzyżowanie itp.) lub rzecz (np. gwiazdę, samochód, polityk, lekarz, urządzenie , stadion, osoba, książka). Tytułem dalszego przykładu, jednostka może odzwierciedlać literaturę, organizację (np. New York Yankees), organ lub partię polityczną, biznes, suwerenny lub rządowy organ (np. Stany Zjednoczone, NATO, FDA itd.), datę (np. 4 lipca 1776), liczbę (np. 60, 3.14159, e), literę, stan, jakość, pomysł, koncepcję lub dowolną ich kombinację.
Oprócz tych definicji jednostki, dowiadujemy się również o klasach jednostek i podklasach oraz o tym, jak jednostki mogą pasować do różnych klas i podklas. Jest to ważne, ponieważ wyszukiwarka będzie próbowała dopasować jednostki do różnych klas, gdy się o nich uczy.
Czym więc jest klasa lub podklasa encji?
Patent opisuje te dogłębnie:
W niektórych aspektach jednostka może być powiązana z klasą jednostek. Klasa jednostki może reprezentować kategoryzację, typ lub klasyfikację grupy lub modelu teoretycznego jednostek. Na przykład w celach ilustracyjnych klasy encji mogą obejmować „osobę”, „galaktykę”, „gracza baseballa”, „drzewo”, „drogę”, „polityka” itp. Klasa encji może być powiązana z jedną lub kilkoma podklasami . W niektórych aspektach podklasa może odzwierciedlać klasę jednostek należących do większej klasy (np. „superklasa”). Na przykładowej liście klas powyżej, na przykład, klasy „gracz baseballu” i „polityk” mogą być podklasami klasy „osoba”, ponieważ wszyscy baseballiści i politycy są ludźmi. W innych przykładach wykonania podklasy mogą reprezentować klasy jednostek, które są prawie całkowicie, ale nie całkowicie, częścią większej nadklasy. Taki układ może powstać w sytuacjach, w których występują wartości odstające lub fikcyjne byty. Na przykład klasa „polityk” może być podklasą klasy „osoba”, nawet jeśli niektóre fikcyjne byty to nieludzie politycy (np. „Mas Amedda”). Ujawnione przykłady wykonania zapewniają sposoby obsługi i zarządzania tego rodzaju powiązaniami, jak dalej opisano poniżej. Zarówno klasy, jak i podklasy mogą reprezentować klasy encji i mogą same stanowić encje.
Instancja danych jest przykładem określonej encji, która pasuje do klasy lub podklasy. Thomas Jefferson jest przykładem „prezydenta USA”, a „Mike Trout” jest konkretnym przykładem „profesjonalnego baseballisty”.
Patent działa na zbieraniu informacji o podmiotach i zbiera informacje o podmiotach, które określa jako „Atrybuty podmiotu”. Jak na tym rysunku z patentu:

Mogą one obejmować właściwości jednostek, a także relacje między klasami jednostek. Patent zapewnia również dogłębny wgląd w to, czym może być atrybut:
Encje mogą być powiązane z co najmniej jednym atrybutem jednostki i/lub atrybutem obiektu. Atrybut jednostki może w niektórych aspektach odzwierciedlać właściwość, cechę, cechę, jakość lub element klasy jednostki. W niektórych aspektach każde lub zasadniczo każde wystąpienie klasy encji będzie współdzielić wspólny zestaw atrybutów encji. Na przykład jednostka „osoba” może być powiązana między innymi z atrybutami jednostki „data urodzenia”, „miejsce urodzenia”, „rodzice”, „płeć” lub ogólnie „ma atrybut”. W innym przykładzie jednostka „zawodowa drużyna sportowa” może być powiązana z atrybutami jednostki, takimi jak „lokalizacja”, „roczny przychód”, „spis” i tak dalej. W innych przykładach wykonania atrybut jednostki może opisywać, w jaki sposób jednostka odnosi się do innej jednostki. Na przykład atrybuty jednostki mogą opisywać relacje między klasami jednostek, takie jak „jest a”, „jest podklasą” lub „jest nadklasą” lub „zawiera”. Na przykład klasa „gwiazda” może być powiązana z atrybutem jednostki „jest podklasą” z klasą jednostki „obiekt niebieski”.
Jeśli chodzi o wyodrębnianie encji, w końcu widzimy pary klucz-wartość używane, aby powiedzieć nam więcej o konkretnych encjach:
W niektórych aspektach atrybut obiektu może odzwierciedlać związek między instancją klasy encji z określoną wartością atrybutu. Na przykład jednostka „George Washington” może być powiązana z atrybutem obiektu „ma datę urodzenia” o wartości „Feb. 22, 1732”. W niektórych przykładach wykonania wartość atrybutu obiektu może sama odzwierciedlać jednostkę. Na przykład w powyższym przykładzie data „Feb. 22, 1732” może odzwierciedlać podmiot.
To podejście do zbierania informacji o podmiotach obejmuje atrybuty, które mogą być wspólne w podklasach, które istnieją w ramach:
W niektórych przykładach wykonania encje i podklasy dziedziczą atrybuty z nadklas, z których się wywodzą. Na przykład klasa „Prezydent USA” może dziedziczyć atrybut „data urodzenia” z nadklasy „osoba”. Co więcej, w niektórych przykładach wykonania nadklasy niekoniecznie dziedziczą atrybuty swoich podklas. Na przykład klasa „osoba” niekoniecznie musi dziedziczyć atrybut „skradzione bazy” z podklasy „zawodowy gracz baseballu” lub atrybut „przyjęta data urzędowania” z podklasy „Prezydent USA”.
Kontekstowe bazy danych i wyodrębnianie jednostek
Rozpoznałem „Konteksty” z niektórych schematów, które widziałem w przeszłości. Jest taki, który jest oczekującym słownictwem Schema, używając terminu „Wie o tym”, w którym można go użyć do opisania osoby działającej w określonym zawodzie jako posiadającej doświadczenie określonego typu. Te terminy kontekstowe są podobne, ponieważ pomagają dostarczyć więcej informacji o podmiotach, które dostarczają informacji o nich. Fragment o bazach kontekstowych z patentu dobrze je opisuje:
W niektórych przykładach wykonania baza danych kontekstów może przechowywać, odnosić się, zarządzać i/lub dostarczać informacje związane z jednym lub większą liczbą kontekstów. Kontekst może odzwierciedlać konstrukcję leksykalną lub reprezentację jednego lub więcej słów (np. słowo, frazę, klauzulę, zdanie, akapit itp.) nadając znaczenie jednemu lub większej liczbie słów (np. encji) w jego sąsiedztwie. W niektórych przykładach wykonania kontekst jest w n-gramach. N-gram może odzwierciedlać ciąg n słów, gdzie n jest dodatnią liczbą całkowitą. Na przykład kontekst może zawierać 1 gramy, takie jak „jest”, „było” lub „zgadzam się, ale przykładowe konteksty mogą zawierać 3 gramy, takie jak na przykład „urodził się”, „jest żonaty”, „ ukradł drugą bazę” lub „napisał sprzeciw”. Konteksty (i n-gramy) mogą również zawierać przerwy o dowolnej długości, takie jak 2-gramowe „od . . . dopóki . . . ”. Jak tu opisano, n-gram może reprezentować dowolną taką sekwencję, a dwa n-gramy nie muszą reprezentować liczby nazw słów. Na przykład „strzelił gola” i „w ostatniej minucie” mogą stanowić n-gramy, mimo że zawierają różną liczbę słów.
Uczenie się o podmiotach i kontekstach to kwestia uczenia się znaczącego słownictwa, ponieważ może to być pomocne, jeśli chodzi o poznanie procesu stojącego za tym patentem oraz tego, jak Google może zaangażować się w eksplorację danych w celu wyodrębnienia informacji o podmiotach, ich atrybutach, i właściwości oraz konteksty, w których je widzimy. Konteksty są bardziej złożone niż tylko krótki n-gram, który pomaga zapewnić kontekst jednostce. Ta następna sekcja patentu mówi nam o klasach kontekstu i encjach kontekstu:
W niektórych przykładach wykonania kontekst może wskazywać na potencjalną obecność jednej lub większej liczby jednostek. Jedna lub więcej potencjalnych jednostek określonych przez kontekst może być tutaj określanych jako „klasy kontekstu” lub „jednostki kontekstu”. Jednak te oznaczenia służą wyłącznie celom ilustracyjnym, ponieważ nie mają na celu ograniczania. Klasy kontekstowe mogą odzwierciedlać zestaw klas zwykle powstających w związku z kontekstem (np. mając z nim związek leksykalny). W niektórych aspektach „klasy kontekstowe” mogą odzwierciedlać określone klasy jednostek. Przykładowo, kontekst „jest żonaty” może być powiązany z klasą kontekstu jednostki „osoba”, ponieważ kontekst „jest żonaty” zwykle ma związek leksykalny z ludźmi (np. ma związek leksykalny z instancjami klasy „osoba”). Na przykład w tym przykładzie zdanie „Jack jest żonaty z Jill” wskazuje, że zarówno „Jack”, jak i „Jill” należą do klasy „osoba”, przynajmniej częściowo ze względu na klasę (klasę) kontekstu. "Jest żonaty z." W innym przykładzie kontekst „ma zwierzaka” może być powiązany z klasami kontekstu, takimi jak „zwierzę”, „kot”, „pies”, „zwierzę udomowione” i tym podobne. Co więcej, w tym alternatywnym przykładzie kontekst „ma zwierzaka” może sygnalizować obecność klas encji, które nie są współrozległe, ponieważ dwie instancje tej samej klasy zazwyczaj nie dzielą relacji leksykalnej (np. relacji atrybutów zwierzak-władca). . Interpretację i generowanie klas kontekstowych wyjaśniono bardziej szczegółowo poniżej.
Wyniki powiązań obejmujące wyodrębnianie jednostek
Patent omawia bardziej szczegółowo klasy kontekstu i encje kontekstu, którym warto przyjrzeć się bardziej szczegółowo. Ale część patentu, która wydawała się warta poznania, dotyczyła czegoś, co odnosi się do obliczania wyników asocjacji podczas ekstrakcji jednostek:
W niektórych aspektach baza danych jednostek i/lub baza danych kontekstów może również przechowywać informacje dotyczące jednego lub większej liczby wyników skojarzeń. Wynik powiązania może odzwierciedlać prawdopodobieństwo lub stopień pewności, że atrybut, wartość atrybutu, relacja, hierarchia klas, wyznaczona klasa kontekstu lub inne takie powiązanie jest ważne, poprawne i/lub uzasadnione. Na przykład, w niektórych przykładach wykonania, wynik powiązania może odzwierciedlać stopień pokrewieństwa między dwiema jednostkami lub kontekstem i jednostką. Oceny asocjacji można określić za pomocą dowolnego procesu zgodnego z ujawnionymi przykładami wykonania. Na przykład, jak wyjaśniono bardziej szczegółowo poniżej, system obliczeniowy (np. serwer) może określać wyniki powiązania za pomocą czynników i wag, takich jak wiarygodność źródeł, z których generowany jest wynik powiązania, częstotliwość lub liczba współwystępowania między dwie encje w treści (np. jako funkcja wszystkich wystąpień, całkowita liczba dokumentów zawierających jedną lub obie encje itp.), atrybuty samych encji (np. czy encja jest podklasą innej), odkrytych powiązań (np. poprzez nadanie większej wagi nowszym lub starszym powiązaniom), czy atrybut ma znaną skłonność do wahań (np. okresowych lub sporadycznych), względną liczbę wystąpień między klasami encji, popularność encji jako parę, średnią, medianę, statystyczną i/lub ważoną bliskość między dwiema jednostkami w analizowanych dokumentach i/lub dowolnym innym procesie ujawnionym w niniejszym dokumencie. W niektórych aspektach system może sam generować jeden lub więcej wyników asocjacji. W niektórych aspektach system może wstępnie załadować jeden lub więcej wyników skojarzeń w oparciu o wstępnie wygenerowane struktury danych (np. przechowywane w bazach danych 140 i/lub 150).

Co ciekawe, takie rzeczy, jak wiarygodność źródeł, mogą odgrywać rolę w wynikach skojarzeń przypisanych do relacji między jednostką lub kontekstem a jednostką. W następnej sekcji przyjrzymy się temu, co nazywają „stosunkiem współwystępowania między kontekstem a bytem”.:
W jednym przykładzie wykonania, na przykład, system komputerowy (np. serwer) może generować wynik powiązania między kontekstem a jednostką poprzez określenie stosunku współwystępowania między kontekstem a jednostką (np. konkretną jednostką, instancją klasę encji itp.) do wszystkich wystąpień tego kontekstu i/lub encji w dokumentach sieciowych. Na przykład jedno przykładowe wyrażenie może przyjąć postać A=P(E,C)/P(C), gdzie A jest przykładową wartością powiązania między jednostką a kontekstem, P(C) jest prawdopodobieństwem znalezienia kontekstu w sekcji tekstu (np. dokument, jedna lub więcej stron internetowych, korpus itp.), a P(E, C) jest prawdopodobieństwem znalezienia obu encji kontekstu współwystępowania w sekcji. W tym przykładzie wynik powiązania może odzwierciedlać warunkowe prawdopodobieństwo znalezienia jednostki E, gdy pojawi się kontekst C. Inne przykładowe wyrażenie dla wyniku asocjacji może mieć postać A=N(E, C)/(N(E)+N(C)-N(E,C)), gdzie N(E) jest liczbą wystąpień encja pojawia się w sekcji (np. korpus), N(C) to liczba wystąpień kontekstu pojawia się w sekcji, a N(E, C) to liczba wystąpień zarówno encji E, jak i kontekstu C występują razem w sekcji. Podobne wyrażenia mogą być używane do generowania wyników asocjacji między dwiema jednostkami.
Ten przykład konkretnych klas encji i kontekstów wyjaśnia, w jaki sposób oceny asocjacji mogą pomóc w zrozumieniu, w jaki sposób takie oceny mogą być przydatne:
Przykładowo, serwer może określić, że kontekst „otrzymuje przepustkę od” współwystępuje z wystąpieniami klas encji „koszykarz” i „osoba” w 35 i 97% przypadków pojawiania się kontekstu we wszystkich analizowanych dokumentach, odpowiednio. System może określić te częstotliwości współwystępowania, wykorzystując, przynajmniej częściowo, modele encji i kontekstu do określenia relacji między encjami (np. aby określić, że „LeBron James” jest instancją klasy „koszykarz”). W tym przykładzie serwer może określić, że wyniki skojarzeń odnoszące się do kontekstu „otrzymuje podanie od” do „koszykarza” i „osoby” wynoszą odpowiednio 0,35 i 0,97.
Zwróć uwagę, że te współwystępowania dotyczą całego zbioru dokumentów, a nie jednego.
Mamy kilka innych przykładów innych czynników, które mogą mieć wpływ na obliczanie wyników skojarzeń:
Wyniki asocjacji mogą uwzględniać inne kwestie, włączając jedną lub więcej wag dla każdego wystąpienia jednostki lub kontekstu. W niektórych aspektach system obliczeniowy może stosować wagi w celu uwzględnienia takich czynników, jak wagi czasowe (np. w celu większego ważenia ostatnich dokumentów lub zdarzeń), wagi wiarygodności (np. w celu ważenia bardziej wiarygodnych źródeł), wagi popularności (np. w celu większego ważenia bardziej popularnych źródeł), wag bliskości (np. w celu większego ważenia jednostek/kontekstów występujących w bliższej odległości od siebie) oraz dowolnego innego rodzaju wag zgodnie z ujawnionymi przykładami wykonania. W niektórych aspektach waga może odzwierciedlać względną ważność konkretnego dokumentu lub pojedynczego zdarzenia w porównaniu z innymi (np. wagi dla wszystkich wystąpień sumują się do 1,0), ważność dokumentu lub zdarzenia w skali bezwzględnej (np. każda waga odzwierciedla niezależną ocenę) lub jakąkolwiek inną miarę wskazującą na powiązanie między dwoma podmiotami lub kontekstami (np. bliskość między kontekstem a podmiotem).
Co może oznaczać niski wynik skojarzenia?
W związku z tym w niektórych przykładach wykonania niski wynik powiązania może wskazywać, że źródło danych, na którym opiera się relacja, jest ogólnie niewiarygodne lub niewiarygodne. W innych przykładach wykonania niski wynik skojarzenia może wskazywać, że współwystępowanie pary podmiotów nie występuje w ostatnich dokumentach. W jeszcze innych przykładach wykonania niski wynik skojarzenia może wskazywać, że współwystępowanie między parą jest rzadkie (np. niewielu „polityków” to „zawodowi koszykarze”). W jeszcze innych przykładach wykonania wynik powiązania może odzwierciedlać kombinację wielu takich czynników. W niektórych aspektach system (np. serwer lub system obliczeniowy w połączeniu z bazami danych) może aktualizować i modyfikować wyniki skojarzeń w czasie (np. w oparciu o nowe dokumenty, konteksty i atrybuty).
Wyniki asocjacji dają nam wyobrażenie o prawdopodobieństwach:
Wynik asocjacji może mieć formę liczby (np. 0,0 do 1,0, 0 do 100 itd.), skali jakościowej (np. mało prawdopodobne, prawdopodobne, bardzo prawdopodobne), skali oznaczonej kolorami i/lub dowolnej inna miara lub schemat oceny, w którym można określić poziomy stopni. Na przykład w jednym przykładzie wykonania baza danych encji może przechowywać wynik powiązania wynoszący 0,84, odzwierciedlający prawdopodobieństwo, że encja „Bryce Harper” jest skojarzona z atrybutem „data urodzenia” o wartości „Październik. 16, 1992”. Może to wskazywać na przykład, że system uznaje datę urodzenia Bryce'a Harpera za 16 października 1992 r. z dokładnością 84%. Ponadto „Bryce Harper” może być powiązany z klasą jednostki „osoba” poprzez atrybut lub związek „jest a” z wynikiem powiązania równym 1,0, co wskazuje na pewność, że Bryce Harper jest osobą. W innym przykładzie kontekst „strzelił gola” może być powiązany z klasami kontekstu „piłkarz”, „hokeista” i „osoba” z wynikami skojarzeń wynoszącymi odpowiednio 0,64, 0,49 i 0,98. Te przykładowe wartości mogą na przykład wskazywać, że bardziej prawdopodobne jest, że kontekst odnosi się do piłkarzy, a nie do hokeistów, a jeszcze bardziej prawdopodobne, że zdanie odnosi się do jednej lub większej liczby osób, a nie do piłkarzy w szczególności. Jak wskazano powyżej, jedna lub więcej baz danych jednostek (np. baza danych jednostek) i bazy danych kontekstów (np. baza danych kontekstów), serwer i/lub urządzenie klienta mogą przechowywać, generować, określać, archiwizować i indeksować jednostki, atrybuty, konteksty, klasy kontekstowe, wyniki asocjacji i wszelkie inne informacje w dowolnej formie zgodnej z ujawnionymi przykładami wykonania.
Grafy wiedzy z wynikami powiązań podczas wyodrębniania jednostek
Patent opisuje przykładowy wykres wiedzy z wynikami asocjacji dołączonymi do każdej krawędzi, która łączy jednostki z atrybutami lub wartościami:
W niektórych aspektach wykres wiedzy może zawierać wiele węzłów, przy czym każdy węzeł odzwierciedla jednostkę. Wykres wiedzy może również zawierać jedną lub więcej krawędzi odzwierciedlających atrybuty opisujące relacje między jednostkami i wartościami poszczególnych atrybutów. W niektórych przykładach wykonania wykres wiedzy może również zawierać ocenę powiązań dla każdej krawędzi (np. każdego atrybutu lub skojarzonej wartości) w nim zawartej, chociaż takie oceny powiązań nie są wymagane. Na ilustracyjnym wykresie wiedzy przedstawionym na FIG. 2A, na przykład, węzeł jednostki „Bryce Harper”, odzwierciedlający konkretną jednostkę, jest połączony z inną jednostką „Washington Nationals” poprzez atrybut obiektu „gra o” z wynikiem powiązania równym 0,96. Te wartości i relacje mogą na przykład wskazywać, że Bryce Harper jest zawodnikiem Washington Nationals i że system kojarzy ten atrybut z poziomem ufności równym 0,96. Sam podmiot „Washington Nationals” może być powiązany z innymi niepokazanymi podmiotami, oznaczonymi kreskowanymi liniami wychodzącymi z węzła. Inne jednostki są przedstawione na FIG. 2A-2C i 3 mogą podobnie być powiązane z innymi niepokazanymi węzłami i atrybutami, a przedstawienie w nich pewnych relacji i wartości jest jedynie ilustracyjne.
Oceny skojarzeń mogą dawać poczucie pewności co do poprawności faktu związanego z podmiotem. Kolejny zestaw przykładów związanych z Bryce Harper:
FIGA. 2A przedstawia również powiązanie węzła „Bryce Harper” z węzłem encji daty „Oct. 16, 1992” i węzeł jednostki wartości „60 Home Runs” odpowiednio za pomocą atrybutów „ma urodziny” i „ma całkowitą liczbę pracowników w karierze”. Atrybuty te mają odpowiednio wyniki powiązania 0,84 i 0,37, co wskazuje, że system jest bardziej pewny wartości powiązanej z powiązaniem atrybutów „ma datę urodzenia” niż wartość powiązaną z „ma całkowity HR kariery”. Różnica w tych wynikach asocjacji może wynikać m.in. zmieniające się w czasie i/lub inne czynniki, zgodne z ujawnionymi przykładami wykonania.
Wyobraź sobie ogromny wykres wiedzy obejmujący wiele różnych typów, z których każdy ma wiele powiązanych właściwości lub atrybutów, a także wyniki asocjacji zapewniające poziomy ufności między jednostkami, klasami i podklasami. Patent pokazuje nam, że byłoby to prawdopodobne:
Węzeł encji może być również powiązany z klasami encji i podklasami, połączonymi za pomocą atrybutów opisujących naturę relacji między jednostką a klasą encji. Na przykład RYS. 2A przedstawia połączenia między węzłem „Bryce Harper” a klasami jednostek „osoba” i „zawodowy baseballista” poprzez odpowiednie krawędzie „jest” i „ma zawód”. Te atrybuty mają wyniki asocjacji odpowiednio 1,0 i 0,99. Przykładowe atrybuty i wyniki skojarzeń wskazują, że system uważa Bryce'a Harpera za osobę, której zawód jest zawodowym graczem w baseball z pewnością lub prawie pewną.
Dowiadujemy się również z niskich wyników skojarzeń dotyczących klas jednostek i innych klas jednostek:
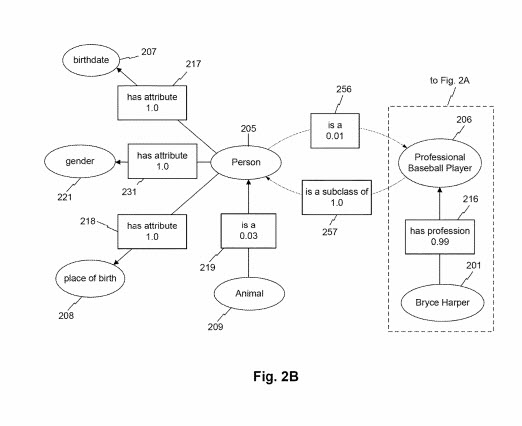
Jak pokazano na FIG. 2B, klasa encji może być również powiązana z innymi klasami encji poprzez atrybuty encji. Na przykład klasa „zwierzę” może być powiązana z klasą „osoba” poprzez atrybut „jest a”. W tym przykładzie wynik powiązania odpowiadający atrybutowi wynosi 0,03. Może to wskazywać na przykład, że przypadki klasy „zwierząt” 209 są rzadkimi przypadkami klasy „osoby” (np. ze względu na występowanie zwierząt innych niż ludzie, takich jak inne ssaki, owady, ptaki, ryby itp.). Chociaż nie pokazano na FIG. 2B, klasa „osoba” może być powiązana z odwrotnym atrybutem „jest a” lub „jest podklasą” itp. w związku z węzłem „zwierzę”. Taki atrybut może być powiązany z wyższym wynikiem asocjacji (np. 0,94), co wskazuje, że klasa „osoba” jest podklasą „zwierzę”. Na przykład RYS. 2B przedstawia klasę „zawodowy zawodnik baseballu” powiązaną z klasą „osoba” z atrybutem podmiotu „jest podklasą” z wynikiem 1,0. W przeciwieństwie do tego, węzeł klasy „osoba” może być powiązany z węzłem „zawodowy gracz baseballu” poprzez atrybut „is a” z wynikiem powiązania 0,01. Ten niższy wynik asocjacji może odzwierciedlać, na przykład, silną przewagę podmiotów z klasy „osoba”, które nie należą do klasy „zawodowy baseballista” (np. większość ludzi nie jest zawodowymi baseballistami). FIGA. 2B przedstawia ponadto, w jaki sposób węzeł klasy zawodowej baseballisty może skojarzyć się z węzłem jednostki „Bryce Harper” poprzez atrybut „ma zawód”, jak omówiono w związku z FIG. 2A.
Powiązania między typami encji i klasami kontekstu na grafie kontekstu mogą dostarczyć nam konkretnych informacji o tych typach encji i kontekstach:
W niektórych przykładach wykonania klasy jednostek zawarte na wykresie kontekstu mogą reprezentować klasy kontekstu związane z określonym kontekstem (np. kontekstem). W takich przykładach wykonania wynik powiązania łączący konteksty z ich klasami kontekstu (i wszelkimi zawartymi podklasami itp.) może odzwierciedlać stopień ważności lub powiązania między klasą kontekstu a kontekstem (np. krawędzią) i/lub stopień pokrewieństwa między klasami samych encji (np. edge). W niektórych aspektach wynik powiązania może zatem odzwierciedlać prawdopodobieństwo, że kontekst sygnalizuje obecność skojarzonej klasy kontekstu lub wystąpienia tej klasy kontekstu. Na przykład, jak pokazano na FIG. 2D, węzeł kontekstu „odbierz(e) przepustkę” może być powiązany z pięcioma klasami kontekstu. W tym przykładzie kontekst „odbiera przepustkę” jest powiązany z klasami kontekstu „osoba”, „gracz baseballu”, „koszykarz”, „hokeista” i „piłkarz”. Każde z tych powiązań może obejmować odpowiedni wynik stowarzyszenia, taki jak wyniki. Te wyniki asocjacji są zilustrowane towarzyszącym wyrażeniem „przyjmuje klasę”, aby wskazać prawdopodobieństwo lub prawdopodobieństwo, że kontekst wskazuje na obecność określonej klasy lub wystąpienia klasy.
Na przykład, ponieważ członek klasy „piłkarz” może rzadko „otrzymywać podanie od” (kontekst) innego gracza, wynik skojarzenia związany z tą klasą kontekstu wynosi 0,02, jak pokazano w elemencie wiersza . Jak wyjaśniono powyżej, wartość ta może być generowana na podstawie częstości współwystępowania kontekstu i instancji klasy „gracza baseballa” w źródłach sieciowych, wiarygodności tych źródeł itp. W przeciwieństwie do tego, wyniki skojarzeń między kontekstem a instancją pozostałe klasy podmiotów są relatywnie wyższe. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019