
استخراج الكيانات للرسوم البيانية المعرفية في Google
نشرت: 2019-02-15<
قد تستخدم Google عمليات استخراج الكيانات ، وفئات الكيانات ، وخصائص الكيانات ، ونتائج الاقتران من الصفحات لإنشاء الرسوم البيانية المعرفية
عندما قدمت Google الرسم البياني المعرفي في عام 2012 ، أخبرنا أنها ستبدأ في التركيز على الأشياء وليس السلاسل ، وفهرسة كائنات العالم الحقيقي. هذه العملية في طريقها إلى النضج ، ولدينا فرصة لمشاهدة Google وهي تتعلم كيفية البدء في الزحف على الويب لتعدين البيانات والمشاركة في عمليات استخراج الكيانات ، بدلاً من التنقيب عن معلومات الويب مثل الصفحات والروابط. كما كتبت مؤخرًا على Twitter حول هذا:
في زحف الويب ، العقدة هي صفحة ، والحافة هي رابط بين الصفحات ؛ في زحف البيانات ، العقدة هي كيان ، والحافة هي علاقة بين الكيانات. إنه تطور في التفكير في الويب.
- بيل سلاوسكي (Bill_slawski) ١٠ فبراير ٢٠١٩
تخبرنا براءة اختراع Google الممنوحة مؤخرًا عن كيفية قيام محرك البحث باستخراج الكيانات من صفحات الويب وتخزين المعلومات المتعلقة بها. هذا يتجاوز استخدام قواعد المعرفة كمصادر للمعلومات حول الكيانات وينتقل للعثور على أكثر مما قد يكون متاحًا في مثل هذه المصادر من خلال النظر في المقاطع النصية على صفحات الويب. هذا يعني على الأرجح أننا سنرى نتائج المعرفة من مصادر أكثر مما لدينا في الماضي ، مثل ويكيبيديا. المشكلة التي تحلها براءة الاختراع هذه في هذا السطر المبكر من براءة الاختراع:
قواعد المعرفة التقليدية ، ولكن يمكن أن تفشل في توفير معلومات محدثة أو موثوقة حول الكيانات والمعلومات الأخرى التي يرغب فيها المستخدمون.
لقد رأينا Google يستخرج الكيانات من الجداول والقوائم المحددة بنقطتين في أماكن مثل Wikipedia و IMDB. ماذا لو تمكنوا من العثور على تلك المعلومات على صفحات الويب ، واستخراج الكيانات من تلك الصفحات ، وجمع الخصائص والسمات حول تلك الكيانات أثناء قيامهم بالزحف إلى صفحات الويب. قد تكون هناك طرق لقياس مستويات الثقة في المعلومات حول تلك الكيانات وصحتها أيضًا.

كما هو موضح في هذه الصور من براءة الاختراع ، تحسب Google درجات الارتباط بين الكيانات والسمات المتصلة (المزيد حول درجات الارتباط أدناه.)
لقد كتبت عن شيء مشابه في المنشور: كيف تُحدِّث Google Knowledge Graph نفسها من خلال الإجابة على الأسئلة. كان التركيز في هذا المنشور على كيفية قيام Google بتحديث الرسوم البيانية المعرفية الحالية ، بدلاً من العثور على معلومات حول الكيانات على صفحات الويب ، والتعرف عليها ، وكيفية انضمامها إلى فئات أخرى من الكيانات. يبدو الاعتماد على قواعد المعرفة بدلاً من التعامل مع الويب كقاعدة بيانات كبيرة كخطوة جزئية. إذا كان من الممكن إجراء عمليات استخراج الكيانات بطريقة ذكية ومفيدة ، فلن يكون الاعتماد على موسوعة بشرية خاضعة للإشراف على الويب أمرًا ضروريًا. في عدد قليل من الأماكن في الماضي ، قالت Google إنها تفضل أساليب قابلة للتطوير على الويب لتنظيم المعلومات على الويب (مثل عندما توقفوا عن استخدام دليل Google ، الذي كان من مصدر كان بواسطة الأشخاص).
تكشف براءة الاختراع الأخيرة هذه عن نهج مختلف يساعد Google على إجراء عمليات استخراج الكيانات وغيرها من المعلومات حول هذه الكيانات ، من المصادر المضافة إلى الويب بدلاً من الإضافة إلى قاعدة المعرفة على الويب ، بما في ذلك صفحات الويب الجديدة ومصادر الأخبار.
تحتوي براءة الاختراع على قسم ملخص في وصفها حيث تخبرنا عن العملية التي تحميها. يلخص هؤلاء في بضع كلمات مثل هذا:
قد توفر النماذج التي تم الكشف عنها أنظمة وطرق لتحديد فئات وسمات الكيانات الجديدة ، بالإضافة إلى درجات الارتباط التي تعكس درجات الارتباط ومستويات الثقة في العلاقات المحددة. قد تحدد التجسيدات التي تم الكشف عنها هذه الفئات والسمات والنتائج ذات الصلة بناءً على السياقات المعجمية المحيطة التي تظهر فيها الكيانات الجديدة والكيانات المعروفة القريبة من كل كيان جديد. توفر جوانب التجسيدات التي تم الكشف عنها أيضًا أنظمة وطرق للتحديث الديناميكي وتخزين العلاقات المحددة في الوقت الفعلي أو في الوقت الفعلي القريب .
إنها تتوسع في تلك الموجودة في مزيد من التفاصيل بقليل من خلال إعطائنا نظرة خطوة بخطوة على العملية التي تشير إليها باسم "تحديد مرشحي الكيان".
تحديد مرشحي الكيانات لاستخراج الكيانات
- مرشح الكيان موجود في مستند يمكن الوصول إليه عبر الشبكة.
- الكيان المرشح الذي تم اكتشافه هو كيان جديد يعتمد على واحد أو أكثر من نماذج الكيانات المخزنة في قاعدة بيانات.
- يوجد كيان معروف بجوار الكيان الجديد ويكون الكيان المعروف في نموذج كيان واحد أو أكثر.
- يحتوي السياق الموجود بجانب الكيان الجديد والكيان المعروف على علاقة معجمية بالكيان المعروف.
- ترتبط فئة الكيان الثانية بالكيان المعروف وفئة السياق أيضًا بالسياق.
- تتصل فئة الكيان الأول بالكيان الجديد بناءً على فئة الكيان الثانية وفئة السياق.
- يعتمد الإدخال الأول في قاعدة البيانات على نموذج واحد على الأقل من نماذج الكيان ، ويعكس الإدخال الارتباط بين فئة الكيان الأول والكيان الجديد.
براءة اختراع المرشحون لهذه الكيانات هي تلك المتعلقة باستخراج الكيانات وتخزين المعلومات حول تلك الكيانات:
الأنظمة والطرق المحوسبة لاستخراج وتخزين المعلومات المتعلقة بالكيانات
المخترعون: كريستوفر سيمتور ولود فانديفين ودانيلا سينوبالنيكوف وألكسندر لياشوك وسيباستيان شتايجر وهنريك جريم ونثنائيل مارتن شارلي وديفيد ليكومتي
الوكيل: GOOGLE LLC
براءات الاختراع الأمريكية: 10198491
تم المنح: 5 فبراير 2019
تاريخ التقديم: 6 يوليو 2015
الملخص
يتم توفير الأنظمة والطرق التي يتم تنفيذها بواسطة الكمبيوتر لاستخراج وتخزين المعلومات المتعلقة بالكيانات من المستندات ، مثل صفحات الويب. في أحد التطبيقات ، يتم توفير نظام يكتشف الكيان المرشح في مستند ويحدد أن المرشح الذي تم اكتشافه هو كيان جديد. يكتشف النظام أيضًا كيانًا معروفًا قريبًا من الكيان المعروف بناءً على نموذج كيان واحد أو أكثر. يكتشف النظام أيضًا سياقًا قريبًا من الكيانات الجديدة والمعروفة التي لها علاقة معجمية بالكيان المعروف. يحدد النظام أيضًا فئة الكيان الثانية المرتبطة بالكيان المعروف وفئة السياق المرتبطة بالسياق. يقوم النظام أيضًا بإنشاء فئة كيان أولى بناءً على فئة الكيان الثانية وفئة السياق. يقوم النظام أيضًا بإنشاء إدخال في نموذج كيان واحد أو أكثر يعكس ارتباطًا بين الكيانين الجديد والأول.
عمليات استخراج الكيانات - الكيانات وفئات الكيانات ومثيلات الكيانات وخصائص الكيانات
تتضمن إحدى الخطوات الأولى في العملية المتضمنة في هذه البراءة الاعتراف بالكيانات. توفر براءة الاختراع بعض المعلومات حول ماهية الكيانات ، وتعطينا عدة أمثلة:
في جوانب معينة ، قد يعكس الكيان شخصًا (مثل ، جورج واشنطن) ، أو مكانًا (على سبيل المثال ، سان فرانسيسكو ، وايومنغ ، شارع أو تقاطع معين ، إلخ) ، أو شيء (على سبيل المثال ، نجم ، سيارة ، سياسي ، طبيب ، جهاز ، ملعب ، شخص ، كتاب). على سبيل المثال ، قد يعكس الكيان قطعة من الأدب ، أو منظمة (على سبيل المثال ، نيويورك يانكيز) ، أو هيئة أو حزب سياسي ، أو شركة ، أو هيئة ذات سيادة أو حكومية (على سبيل المثال ، الولايات المتحدة ، الناتو ، إدارة الغذاء والدواء ، إلخ) ، تاريخ (على سبيل المثال ، 4 يوليو 1776) ، رقم (على سبيل المثال ، 60 ، 3.14159 ، هـ) ، حرف ، حالة ، جودة ، فكرة ، مفهوم ، أو أي مزيج منها.
علاوة على تلك التعريفات للكيان ، يتم إخبارنا أيضًا عن فئات الكيانات والفئات الفرعية ، وكيف يمكن للكيانات أن تتناسب مع الفئات والفئات الفرعية المختلفة. هذا مهم لأن محرك البحث سيحاول ملاءمة الكيانات في فئات مختلفة عندما يتعلم عنها.
إذن ما هي فئة الكيان أو الفئة الفرعية؟
تصف براءة الاختراع تلك بالتفصيل:
في بعض الجوانب ، قد يرتبط الكيان بفئة الكيان. قد تمثل فئة الكيان تصنيفًا أو نوعًا أو تصنيفًا لمجموعة أو نموذجًا نظريًا للكيانات. لأغراض التوضيح ، على سبيل المثال ، قد تتضمن فئات الكيانات "شخص" و "مجرة" و "لاعب بيسبول" و "شجرة" و "طريق" و "سياسي" وما إلى ذلك. قد يتم ربط فئة الكيان بفئة فرعية واحدة أو أكثر . في بعض الجوانب ، قد تعكس فئة فرعية فئة من الكيانات المدرجة في فئة أكبر (على سبيل المثال ، "فئة فائقة"). في قائمة الفصل التوضيحي أعلاه ، على سبيل المثال ، قد تكون فصول "لاعب البيسبول" و "السياسي" فئتين فرعيتين من فئة "الشخص" ، لأن جميع لاعبي البيسبول والسياسيين هم بشر. في تجسيدات أخرى ، قد تمثل الفئات الفرعية فئات من الكيانات التي هي تقريبًا بالكامل ، ولكن ليس بالكامل ، جزءًا من طبقة عظمى أكبر. قد ينشأ مثل هذا الترتيب في المواقف التي تحتوي على قيم متطرفة أو كيانات خيالية. على سبيل المثال ، قد تكون فئة "السياسي" فئة فرعية من فئة "الشخص" ، على الرغم من أن بعض الكيانات الوهمية هم سياسيون غير بشريين (على سبيل المثال ، "ماس عمدة"). توفر النماذج التي تم الكشف عنها طرقًا للتعامل مع هذه الأنواع من العلاقات وإدارتها ، كما هو موضح بمزيد من التفصيل أدناه. قد تمثل كل من الفئات والفئات الفرعية فئات الكيانات وقد تشكل كيانات بحد ذاتها.
مثيل البيانات هو مثال لكيان محدد يناسب فئة أو فئة فرعية. توماس جيفرسون هو مثال على "رئيس الولايات المتحدة" ، و "مايك تراوت" هو مثال محدد لـ "لاعب بيسبول محترف".
تعمل براءة الاختراع على جمع المعلومات حول الكيانات ، وتقوم بجمع معلومات حول الكيانات التي تشير إليها باسم "سمات الكيان". كما في هذا الرسم من براءة الاختراع:

يمكن أن تتضمن هذه خصائص الكيانات وكذلك العلاقات بين فئات الكيانات. توفر براءة الاختراع نظرة عميقة على ما يمكن أن تكون عليه السمة أيضًا:
قد ترتبط الكيانات بواحدة أو أكثر من سمات الكيان و / أو سمات الكائن. قد تعكس سمة الكيان خاصية أو سمة أو خاصية أو جودة أو عنصرًا من فئة الكيان في بعض الجوانب. في بعض الجوانب ، كل مثيل لفئة الكيان أو كل مثيل له إلى حد كبير سيشترك في مجموعة مشتركة من سمات الكيان. على سبيل المثال ، قد يرتبط الكيان "الشخص" بسمات الكيان "تاريخ الميلاد" أو "مكان الميلاد" أو "الوالدين" أو "الجنس" أو ، بشكل عام ، "له سمة" ، من بين أمور أخرى. في مثال آخر ، قد يكون الكيان "فريق رياضي محترف" مرتبطًا بسمات الكيان مثل "الموقع" ، "الإيرادات السنوية" ، "القائمة" ، وهكذا. في تجسيدات أخرى ، قد تصف سمة الكيان كيفية ارتباط كيان بكيان آخر. على سبيل المثال ، قد تصف سمات الكيان العلاقات بين فئات الكيانات مثل "هي" ، أو "فئة فرعية من" ، أو "فئة فائقة لـ" ، أو "تحتوي على". على سبيل المثال ، قد ترتبط الفئة "star" بسمة الكيان "هي فئة فرعية من" بفئة الكيان "كائن سماوي".
عندما يتعلق الأمر باستخراج الكيانات ، ينتهي بنا الأمر برؤية أزواج ذات قيمة رئيسية تُستخدم لإخبارنا بالمزيد عن كيانات محددة:
في جوانب معينة ، قد تعكس سمة الكائن علاقة بين مثيل فئة الكيان بقيمة سمة معينة. على سبيل المثال ، قد يتم ربط الكيان "جورج واشنطن" بسمة كائن "له تاريخ ميلاد" بقيمة "فبراير. 22 ، 1732. " في بعض النماذج ، قد تعكس قيمة سمة كائن كيانًا في حد ذاته. على سبيل المثال ، في المثال أعلاه ، التاريخ "فبراير. 22 ، 1732 "قد تعكس كيانًا.
يتضمن هذا النهج لجمع المعلومات حول الكيانات السمات التي قد تكون شائعة في الفئات الفرعية الموجودة داخل:
في بعض النماذج ، ترث الكيانات والفئات الفرعية السمات من الطبقات الفائقة التي تشتق منها. على سبيل المثال ، قد ترث فئة "رئيس الولايات المتحدة" السمة "تاريخ الميلاد" من الطبقة الفائقة "شخص". علاوة على ذلك ، في تجسيدات معينة ، قد لا ترث الفئات الفائقة بالضرورة سمات فئاتها الفرعية. على سبيل المثال ، قد لا ترث الفئة "شخص" بالضرورة السمة "القواعد المسروقة" من الفئة الفرعية "لاعب البيسبول المحترف" أو السمة "تاريخ المكتب المفترض" من الفئة الفرعية "رئيس الولايات المتحدة".
قواعد بيانات السياق واستخراج الكيانات
لقد تعرفت على "السياقات" من بعض المخططات التي رأيتها في الماضي. هناك أحد مفردات المخطط المعلقة ، باستخدام مصطلح "يعرف" ، حيث يمكنك استخدامه لوصف شخص يتصرف في مهنة معينة على أنه لديه خبرة من نوع معين. تتشابه مصطلحات السياق هذه لأنها تساعد في توفير مزيد من المعلومات حول الكيانات التي توفر لك معلومات عنها. يصف المقطع حول قواعد بيانات السياق من براءة الاختراع جيدًا:
في بعض النماذج ، قد تقوم قاعدة بيانات السياق بتخزين و / أو ربط وإدارة و / أو توفير المعلومات المرتبطة بسياق واحد أو أكثر. قد يعكس السياق بناءًا معجميًا أو تمثيلًا لكلمة أو أكثر (على سبيل المثال ، كلمة ، عبارة ، جملة ، جملة ، فقرة ، إلخ) تضفي معنى لكلمة واحدة أو أكثر (على سبيل المثال ، كيان) بالقرب منها. في تجسيدات معينة ، يكون السياق في n-gram. قد يعكس n-gram سلسلة من الكلمات n ، حيث n هي عدد صحيح موجب. على سبيل المثال ، قد يشتمل السياق على 1 جرام مثل "is" أو "was" أو "concurreBesidestion ، وقد تتضمن السياقات النموذجية 3 جرامًا مثل ، على سبيل المثال ،" ولدت في "،" متزوجة من "،" سرق القاعدة الثانية "أو" كتب معارضة ". قد تتضمن السياقات (و n-grams) أيضًا فجوات من أي طول ، مثل 2-gram "from. . . حتى . . . . " كما هو موصوف هنا ، قد يمثل n-gram أي تسلسل من هذا القبيل ، ولا يلزم أن يمثل اثنان n-grams اسم عدد الكلمات. على سبيل المثال ، "سجل هدفًا" و "في الدقيقة الأخيرة" يمكن أن يشكل كلاهما n-grams ، على الرغم من احتوائهما على عدد مختلف من الكلمات.
إن التعرف على الكيانات والسياقات هو مسألة تعلم مفردات ذات مغزى لأن القيام بذلك يمكن أن يكون مفيدًا عندما يتعلق الأمر بالتعرف على كيفية عمل العملية الكامنة وراء براءة الاختراع هذه ، وكيف يمكن لـ Google المشاركة في التنقيب عن البيانات لاستخراج معلومات حول الكيانات وخصائصها ، والخصائص والسياقات التي نراها فيها. السياقات أكثر تعقيدًا من مجرد n-gram قصير يساعد في توفير سياق لكيان. يخبرنا القسم التالي من براءة الاختراع عن فئات السياق وكيانات السياق:
في تجسيدات معينة ، قد يشير السياق إلى الوجود المحتمل لكيان واحد أو أكثر. قد تتم الإشارة هنا إلى واحد أو أكثر من الكيانات المحتملة المحددة بواسطة سياق باسم "فئات السياق" أو "كيانات السياق". ومع ذلك ، فإن هذه التعيينات هي لأغراض توضيحية فقط حيث لا يقصد منها أن تكون مقيدة. قد تعكس فئات السياق مجموعة من الفئات تنشأ عادةً فيما يتعلق (على سبيل المثال ، وجود علاقة معجمية مع) السياق. في بعض الجوانب ، قد تعكس "فئات السياق" فئات كيانات معينة. على سبيل المثال ، قد يرتبط السياق "متزوج من" بفئة سياق للكيان "شخص" ، لأن السياق "متزوج من" عادة ما يكون له علاقة معجمية بالبشر (على سبيل المثال ، لديه علاقة معجمية مع الأمثلة من فئة "الشخص"). في هذا المثال ، على سبيل المثال ، تشير الجملة "Jack is married to Jill" إلى أن كلا من "Jack" و "Jill" من فئة "person" ، بسبب ، جزئيًا على الأقل ، فئة (فئات) سياق السياق "متزوج من." في مثال آخر ، قد يرتبط السياق "لديه حيوان أليف" بفئات السياق مثل "حيوان" و "قطة" و "كلب" و "حيوان أليف" وما شابه. علاوة على ذلك ، في هذا المثال البديل ، قد يشير السياق "لديه حيوان أليف" إلى وجود فئات كيان ليست مترابطة ، لأن مثيلين من نفس الفئة لا يشتركان عادةً في علاقة معجمية (على سبيل المثال ، علاقة سمة رئيسي بين حيوان أليف) . يتم شرح تفسير وإنشاء فئات السياق بمزيد من التفصيل أدناه.
عشرات الرابطة التي تنطوي على استخراج الكيانات
تتناول براءة الاختراع مزيدًا من التفاصيل حول فئات السياق وكيانات السياق ، وتلك التي تستحق النظر فيها بمزيد من التفصيل. لكن قسمًا من براءة الاختراع يبدو أنه يستحق التعلم حول شيء متضمن يشير إلى حساب درجات الارتباط أثناء عمليات استخراج الكيان:
في بعض الجوانب ، قد تقوم قاعدة بيانات الكيان و / أو قاعدة بيانات السياق أيضًا بتخزين المعلومات المتعلقة بواحد أو أكثر من درجات الارتباط. قد تعكس درجة الارتباط احتمالية أو درجة ثقة بأن السمة أو قيمة السمة أو العلاقة أو التدرج الهرمي للفئة أو فئة السياق المعينة أو أي ارتباط آخر صحيح و / أو صحيح و / أو شرعي. على سبيل المثال ، في بعض النماذج ، قد تعكس درجة الارتباط درجة الارتباط بين كيانين أو سياق وكيان. يمكن تحديد درجات الرابطة من خلال أي عملية تتفق مع النماذج التي تم الكشف عنها. على سبيل المثال ، كما هو موضح بمزيد من التفصيل أدناه ، قد يحدد نظام الحوسبة (على سبيل المثال ، الخادم) درجات الارتباط باستخدام عوامل وأوزان مثل موثوقية المصادر التي يتم من خلالها إنشاء درجة الاقتران ، وتكرار أو عدد التكرارات المشتركة بين كيانان في المحتوى (على سبيل المثال ، كدالة لإجمالي التكرارات ، العدد الإجمالي للمستندات التي تحتوي على كيان واحد أو كلا الكيانين ، إلخ) ، سمات الكيانات نفسها (على سبيل المثال ، ما إذا كان الكيان فئة فرعية من فئة أخرى) ، حداثة للعلاقات المكتشفة (على سبيل المثال ، من خلال إعطاء وزن أكبر للارتباطات الأحدث أو الأقدم) ، وما إذا كانت السمة لها ميل معروف للتقلب (على سبيل المثال ، بشكل دوري أو متقطع) ، والعدد النسبي للحالات بين فئات الكيانات ، وشعبية الكيانات مثل زوج و / أو متوسط و / أو متوسط و / أو إحصائي و / أو تقارب مرجح بين كيانين في المستندات التي تم تحليلها و / أو أي عملية أخرى تم الكشف عنها هنا. في بعض الجوانب ، قد يُنشئ النظام نفسه درجة ارتباط واحدة أو أكثر. في جوانب معينة ، قد يقوم النظام بتحميل واحد أو أكثر من نقاط الارتباط مسبقًا بناءً على هياكل البيانات التي تم إنشاؤها مسبقًا (على سبيل المثال ، المخزنة في قواعد البيانات 140 و / أو 150).

ومن المثير للاهتمام ، أن أشياء مثل موثوقية المصادر قد تلعب دورًا في درجات الارتباط المخصصة لعلاقة بين كيان أو سياق وكيان. يبحث القسم التالي في ما يسمونه "نسبة التكرارات المشتركة بين السياق والكيان".:
في أحد التجسيدات ، على سبيل المثال ، قد ينتج عن نظام الحوسبة (على سبيل المثال ، الخادم) درجة ارتباط بين السياق والكيان عن طريق تحديد نسبة التكرارات المشتركة بين السياق والكيان (على سبيل المثال ، الكيان المحدد ، مثيل فئة الكيان ، وما إلى ذلك) لجميع تكرارات هذا السياق و / أو الكيان عبر مستندات الشبكة. أحد التعبيرات التوضيحية ، على سبيل المثال ، قد يتخذ الشكل A = P (E ، C) / P (C) ، حيث A مثال لقيمة الارتباط بين الكيان والسياق ، P (C) هو احتمال العثور على السياق في قسم من النص (على سبيل المثال ، مستند ، صفحة ويب واحدة أو أكثر ، مجموعة ، وما إلى ذلك) ، و P (E ، C) هي احتمالية العثور على كيان السياق المتزامن في القسم. في هذا المثال ، قد تعكس درجة الاقتران الاحتمال الشرطي لإيجاد كيان E عندما يظهر السياق C. قد يأخذ تعبير توضيحي آخر لدرجة الارتباط شكل A = N (E ، C) / (N (E) + N (C) -N (E ، C)) ، حيث N (E) هو عدد المثيلات يظهر الكيان في قسم (على سبيل المثال ، مجموعة) ، N (C) هو عدد الحالات التي يظهر فيها السياق في القسم ، و N (E ، C) هو عدد مثيلات كل من الكيان E والسياق C يظهران معًا في القسم. يمكن استخدام تعبيرات مماثلة لتوليد درجات اقتران بين كيانين.
يوضح هذا المثال لفئات وسياقات كيانات معينة كيف يمكن أن تساعد درجات الارتباط في فهم كيف يمكن أن تكون هذه الدرجات مفيدة:
على سبيل المثال ، قد يحدد الخادم أن السياق "يتلقى تمريرة من" يحدث بشكل مشترك مع حالات فئات الكيان "لاعب كرة السلة" و "الشخص" 35 و 97 بالمائة من الوقت الذي يظهر فيه السياق في جميع المستندات التي تم تحليلها ، على التوالى. قد يحدد النظام هذه الترددات من التواجد المشترك عن طريق استخدام ، على الأقل جزئيًا ، نماذج الكيانات والسياق لتحديد العلاقات بين الكيانات (على سبيل المثال ، لتحديد "LeBron James" هو مثال من فئة "لاعب كرة السلة"). في هذا المثال ، قد يحدد الخادم أن درجات الاتحاد المتعلقة بالسياق "تتلقى تمريرة من" إلى "لاعب كرة السلة" و "شخص" هي على التوالي 0.35 و 0.97.
لاحظ أن هذه التكرارات هي من أكثر من مجموعة من المستندات ، بدلاً من واحدة.
لدينا بعض الأمثلة الأخرى للعوامل الأخرى التي قد تلعب في حساب درجات الارتباط:
قد تراعي درجات الرابطة اعتبارات أخرى من خلال دمج واحد أو أكثر من الأوزان لكل تواجد لكيان أو سياق. في بعض الجوانب ، قد يطبق نظام الحوسبة أوزانًا لحساب عوامل مثل الأوزان الزمنية (على سبيل المثال ، لوزن المستندات أو الأحداث الأخيرة بشكل أكبر) ، وأوزان الموثوقية (على سبيل المثال ، لوزن المصادر الأكثر موثوقية بشكل أكبر) ، وأوزان الشعبية (على سبيل المثال ، لوزن المصادر الأكثر شيوعًا بشكل أكبر) ، وأوزان القرب (على سبيل المثال ، لوزن الكيانات / السياقات التي تحدث بالقرب من بعضها البعض بشكل أكبر) وأي نوع آخر من الوزن يتوافق مع النماذج التي تم الكشف عنها. في جوانب معينة ، قد يعكس الوزن الأهمية النسبية لوثيقة معينة أو حدث فردي مقارنة بالآخرين (على سبيل المثال ، مجموع أوزان جميع التكرارات 1.0) ، وأهمية مستند أو حدث على مقياس مطلق (على سبيل المثال ، كل وزن يعكس تصنيفًا مستقلاً) ، أو أي مقياس آخر يشير إلى العلاقة بين كيانين أو سياقين (على سبيل المثال ، القرب بين السياق والكيان).
ماذا قد تعني درجة ارتباط منخفضة؟
وبالتالي ، في بعض النماذج ، قد تشير درجة الارتباط المنخفضة إلى أن مصدر البيانات الذي تستند إليه العلاقة بشكل عام غير جدير بالثقة أو غير موثوق به. في تجسيدات أخرى ، قد تشير درجة الارتباط المنخفضة إلى أن التكرارات المشتركة للزوج الموضوع لا تحدث في المستندات الحديثة. في تجسيدات أخرى ، قد تشير درجة الارتباط المنخفضة إلى أن التكرارات المشتركة بين الزوجين نادرة (على سبيل المثال ، قلة من "السياسيين" هم "لاعبو كرة سلة محترفون"). في تجسيدات أخرى حتى الآن ، قد تعكس درجة الارتباط مجموعة من العديد من هذه العوامل. في بعض الجوانب ، قد يقوم النظام (على سبيل المثال ، الخادم أو نظام الحوسبة المرتبط بقواعد البيانات) بتحديث وتعديل درجات الاقتران بمرور الوقت (على سبيل المثال ، بناءً على المستندات والسياقات والسمات الجديدة).
تمنحنا نتائج الرابطة فكرة عن الاحتمالات:
قد تأخذ درجة الارتباط شكل رقم عددي (على سبيل المثال ، 0.0 إلى 1.0 ، 0 إلى 100 ، إلخ) ، مقياس نوعي (على سبيل المثال ، غير مرجح ، محتمل ، محتمل جدًا) ، مقياس مرمز بالألوان ، و / أو أي مخطط قياس أو تصنيف آخر قادر على تحديد مستويات الدرجة. على سبيل المثال ، في أحد النماذج ، قد تخزن قاعدة بيانات الكيان درجة ارتباط تبلغ 0.84 ، مما يعكس احتمال ارتباط الكيان "برايس هاربر" بسمة "تاريخ ميلاد" لها قيمة "أكتوبر. 16 ، 1992. " قد يشير هذا ، على سبيل المثال ، إلى أن النظام يعتبر أن تاريخ ميلاد برايس هاربر هو 16 أكتوبر 1992 ، بدقة 84٪. أيضًا ، قد يرتبط "Bryce Harper" بفئة كيان "person" عبر السمة أو العلاقة "is a" بدرجة ارتباط 1.0 ، مما يشير إلى اليقين بأن Bryce Harper هو شخص. في مثال آخر ، قد يرتبط السياق "سجل هدفًا" بفئات السياق "لاعب كرة قدم" و "لاعب هوكي" و "شخص" مع درجات ارتباط 0.64 و 0.49 و 0.98 على التوالي. قد تشير هذه القيم النموذجية ، على سبيل المثال ، إلى أنه من الأرجح أن السياق يتعلق بلاعبي كرة القدم أكثر من لاعبي الهوكي ، والأكثر احتمالية أن الجملة تتعلق بشخص واحد أو أكثر بشكل عام على لاعبي كرة القدم على وجه الخصوص. كما هو موضح أعلاه ، فإن قاعدة بيانات الكيان أو أكثر (على سبيل المثال ، قاعدة بيانات الكيان) وقواعد بيانات السياق (على سبيل المثال ، قاعدة بيانات السياق) ، والخادم ، و / أو جهاز العميل قد يخزن ، ويولد ، ويحدد ، ويؤرشف ، ويفهرس الكيانات والسمات والسياقات ، فئات السياق ودرجات الاقتران وأي معلومات أخرى بأي شكل يتفق مع التجسيدات التي تم الكشف عنها.
الرسوم البيانية المعرفية مع الدرجات المرتبطة أثناء عمليات استخراج الكيانات
تصف براءة الاختراع مثالاً للرسم البياني للمعرفة مع درجات الارتباط المضمنة مع كل حافة تربط الكيانات بالسمات أو القيم:
في بعض الجوانب ، قد يشتمل الرسم البياني المعرفي على مجموعة من العقد ، كل عقدة تعكس كيانًا. قد يشتمل الرسم البياني للمعرفة أيضًا على حافة واحدة أو أكثر تعكس السمات التي تصف العلاقات بين الكيانات وقيم سمات معينة. في تجسيدات معينة ، قد يشتمل الرسم البياني للمعرفة أيضًا على درجة ارتباط لكل حافة (على سبيل المثال ، كل سمة أو قيمة مرتبطة) متضمنة فيه ، على الرغم من أن درجات الارتباط هذه غير مطلوبة. في الرسم البياني المعرفي التوضيحي الموضح في FIG. 2A ، على سبيل المثال ، عقدة الكيان "Bryce Harper" ، التي تعكس كيانًا معينًا ، مرتبطة بكيان آخر ، "Washington Nationals" ، عبر سمة الكائن "play for" بدرجة ارتباط تبلغ 0.96. قد تشير هذه القيم والعلاقات ، على سبيل المثال ، إلى أن برايس هاربر هو لاعب لمواطني واشنطن وأن النظام يربط هذه السمة بدرجة ثقة تبلغ 0.96. قد يكون الكيان "مواطني واشنطن" نفسه مرتبطًا بكيانات أخرى غير معروضة ، مشار إليها بالخطوط المجزأة المنبثقة من العقدة. يتم وصف الكيانات الأخرى في التين. يمكن ربط 2A-2C و 3 بالمثل مع عقد وسمات أخرى غير معروضة ، وتصوير بعض العلاقات والقيم الواردة فيهما هو مجرد توضيح.
يمكن أن توفر درجات الارتباط إحساسًا بالثقة في صحة حقيقة تتعلق بكيان ما. مجموعة أخرى من الأمثلة المتعلقة ببرايس هاربر:
تين. يصور 2A أيضًا ربط العقدة "Bryce Harper" بعقدة كيان التاريخ "October. 16 ، 1992 "وعقدة كيان القيمة" 60 عملية تشغيل رئيسية "عبر السمتين" له تاريخ ميلاد "و" لديه إجمالي موارد بشرية وظيفي "، على التوالي. تحتوي هذه السمات على درجات ارتباط ذات صلة تبلغ 0.84 و 0.37 ، مما يشير إلى أن النظام أكثر ثقة في القيمة المرتبطة بعلاقة السمة "لها تاريخ ميلاد" من القيمة المرتبطة بـ "إجمالي الموارد البشرية الوظيفي". قد ينشأ الاختلاف في درجات الارتباط هذه ، على سبيل المثال ، بسبب موثوقية المصادر المستخدمة لإنشاء مثل هذه العلاقات ، وتكرار التكرار بين الكيانات ، وحقيقة أن إحدى قيم السمات (العقدة 204) هي تتغير بمرور الوقت ، و / أو عوامل أخرى ، بما يتفق مع النماذج التي تم الكشف عنها.
صورة رسم بياني معرفي ضخم يغطي العديد من الأنواع المختلفة ، ولكل منها العديد من الخصائص أو السمات المرتبطة بها ، وتوفر درجات الارتباط مستويات الثقة بين الكيانات والفئات والفئات الفرعية. توضح لنا براءة الاختراع أن هذا من المحتمل:
قد ترتبط عقدة الكيان أيضًا بفئات الكيانات والفئات الفرعية ، متصلة عبر سمات تصف طبيعة العلاقة بين الكيان وفئة الكيان. على سبيل المثال ، FIG. يصور 2A الروابط بين العقدة "Bryce Harper" وفئات الكيان "person" و "لاعب البيسبول المحترف" عبر الحواف المعنية "هو" و "لديه مهنة". هذه السمات لها درجات اقتران 1.0 و 0.99 على التوالي. تشير السمات التوضيحية ودرجات الارتباط إلى أن النظام يعتبر Bryce Harper شخصًا مهنته لاعب بيسبول محترف مع اليقين أو شبه اليقين.
نتعلم أيضًا من درجات الارتباط المنخفضة حول فئات الكيانات وفئات الكيانات الأخرى:
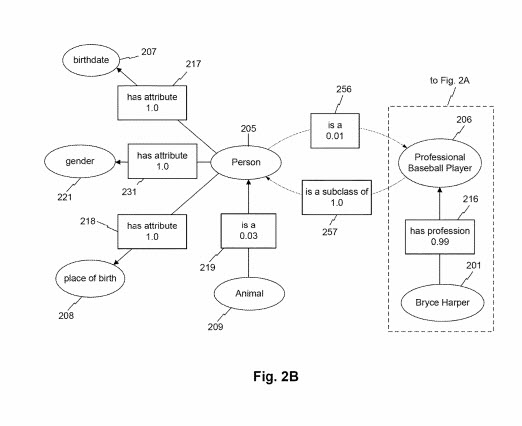
كما هو مبين في FIG. 2 ب ، قد ترتبط فئة الكيان أيضًا بفئات الكيانات الأخرى من خلال سمات الكيان. على سبيل المثال ، قد ترتبط الفئة "حيوان" بالفئة "شخص" عبر السمة "is a." في هذا المثال ، درجة الاقتران المقابلة للسمة هي 0.03. قد يشير هذا ، على سبيل المثال ، إلى أن حالات فئة "الحيوان" 209 هي حالات نادرة لفئة "الشخص" (على سبيل المثال ، بسبب انتشار الحيوانات غير البشرية مثل الثدييات الأخرى ، والحشرات ، والطيور ، والأسماك ، وما إلى ذلك). بينما لا يصور في FIG. 2B ، قد ترتبط الفئة "شخص" بسمة متبادلة "هي" أو "فئة فرعية من" ، وما إلى ذلك ، فيما يتعلق بالعقدة "الحيوانية". قد ترتبط هذه السمة بدرجة ارتباط أعلى (على سبيل المثال ، 0.94) ، مما يشير إلى أن الفئة "شخص" هي فئة فرعية من "حيوان". على سبيل المثال ، FIG. يصور 2B فئة "لاعب البيسبول المحترف" المرتبط بالفئة "الشخص" مع سمة الكيان "هي فئة فرعية من" بدرجة الارتباط 1.0. في المقابل ، قد ترتبط عقدة الفصل "شخص" بالعقدة "لاعب بيسبول محترف" عبر السمة "is a" مع درجة ارتباط 0.01. قد تعكس درجة الارتباط المنخفضة هذه ، على سبيل المثال ، الانتشار القوي لكيانات فئة "الشخص" التي ليست من فئة "لاعب بيسبول محترف" (على سبيل المثال ، معظم الناس ليسوا لاعبي بيسبول محترفين). تين. يصف 2B أيضًا كيف يمكن أن ترتبط عقدة فئة لاعب البيسبول المحترف بعقدة الكيان "Bryce Harper" عبر السمة "لديها مهنة" ، كما تمت مناقشته فيما يتعلق بـ FIG. 2 أ.
قد تخبرنا الارتباطات بين أنواع الكيانات وفئات السياق في الرسم البياني للسياق بمعلومات محددة حول أنواع وسياقات الكيانات تلك:
في بعض التجسيدات ، قد تمثل فئات الكيانات المضمنة في الرسم البياني للسياق فئات السياق المرتبطة بسياق معين (على سبيل المثال ، السياق). في مثل هذه النماذج ، قد تعكس درجة الارتباط التي تربط السياقات بفئات السياق الخاصة بها (وأي فئات فرعية مضمنة ، وما إلى ذلك) درجة من الصلاحية أو الارتباط بين فئة السياق والسياق (على سبيل المثال ، الحافة) و / أو درجة الارتباط بين فئات الكيان نفسها (على سبيل المثال ، الحافة). في بعض الجوانب ، قد تعكس درجة الارتباط بالتالي احتمالية أن يشير السياق إلى وجود فئة السياق المرتبطة أو مثيل لفئة السياق هذه. على سبيل المثال ، كما هو موضح في الشكل. 2D ، قد ترتبط عقدة السياق "تلقي (استقبالات) مرور من" بخمس فئات سياق. في هذا المثال ، يرتبط سياق "تلقي (استقبالات) تمريرة من" بفئات السياق "شخص" و "لاعب بيسبول" و "لاعب كرة سلة" و "لاعب هوكي" و "لاعب كرة قدم" قد تتضمن كل من هذه الاتحادات نتيجة ارتباط مقابلة ، مثل الدرجات. يتم توضيح درجات الارتباط هذه مع العبارة المصاحبة "تأخذ فئة" للإشارة إلى احتمالية أو احتمال أن يشير السياق إلى وجود فئة معينة أو حالة فئة معينة.
على سبيل المثال ، نظرًا لأنه قد يكون نادرًا بالنسبة لعضو في الفصل الدراسي "لاعب بيسبول" "تلقي (تمريرة) من" (سياق) لاعب آخر ، فإن درجة الارتباط المرتبطة بفئة السياق هذه هي 0.02 ، كما هو موضح في عنصر السطر . كما هو موضح أعلاه ، يمكن إنشاء هذه القيمة من تكرار التكرارات المشتركة بين السياق ومثيل لفئة "لاعب البيسبول" عبر مصادر الشبكة ، وموثوقية هذه المصادر ، وما إلى ذلك. وعلى النقيض من ذلك ، فإن درجات الارتباط بين السياق و فئات الكيانات المتبقية أعلى نسبيًا. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019