
Entitätsextraktion für Knowledge Graphs bei Google
Veröffentlicht: 2019-02-15<
Google kann Entitätsextraktionen, Entitätsklassen, Entitätseigenschaften und Assoziationsbewertungen von Seiten verwenden, um Knowledge Graphs zu erstellen
Als Google 2012 den Knowledge Graph einführte, sagte er uns, dass er sich auf Dinge und nicht auf Strings konzentrieren und reale Objekte indizieren würde. Dieser Prozess reift, und wir haben die Möglichkeit zu sehen, wie Google lernt, wie man mit dem Crawlen des Webs beginnt, um Daten zu minen und Entitäten zu extrahieren, anstatt Webinformationen wie Seiten und Links zu minen. Wie ich kürzlich auf Twitter dazu geschrieben habe:
Beim Web-Crawling ist ein Node eine Seite und ein Edge ein Link zwischen Seiten. Beim Daten-Crawling ist ein Knoten eine Entität und eine Kante eine Beziehung zwischen Entitäten. Es ist eine Weiterentwicklung des Denkens über das Web.
— Bill Slawski (@bill_slawski) 10. Februar 2019
Ein kürzlich erteiltes Google-Patent sagt uns, wie die Suchmaschine Entitätenextraktionen aus Webseiten durchführen und Informationen darüber speichern kann. Dies geht über die Verwendung von Wissensdatenbanken als Informationsquellen über Entitäten hinaus und geht weiter, um mehr zu finden, als in solchen Quellen möglicherweise verfügbar ist, indem Textpassagen auf Webseiten betrachtet werden. Dies bedeutet wahrscheinlich, dass wir Wissensergebnisse aus mehr Quellen als in der Vergangenheit sehen werden, wie beispielsweise Wikipedia. Das Problem, das dieses Patent in dieser frühen Zeile des Patents löst:
Herkömmliche Wissensdatenbanken können jedoch keine aktuellen oder zuverlässigen Informationen über Entitäten und andere von Benutzern gewünschte Informationen bereitstellen.
Wir haben gesehen, wie Google Entitäten aus Tabellen und durch Doppelpunkte getrennten Listen an Orten wie Wikipedia und IMDB extrahiert hat. Was wäre, wenn sie diese Informationen auf Webseiten finden und Entitäten aus diesen Seiten extrahieren und beim Crawlen von Webseiten Eigenschaften und Attribute zu diesen Entitäten sammeln könnten. Es gibt möglicherweise Möglichkeiten, das Vertrauensniveau von Informationen über diese Entitäten und auch deren Richtigkeit zu messen.

Wie in diesen Bildern aus dem Patent gezeigt, berechnet Google Assoziationsbewertungen zwischen Entitäten und verbundenen Attributen (weitere Informationen zu Assoziationsbewertungen finden Sie weiter unten).
Ich habe über etwas Ähnliches in dem Beitrag geschrieben: Wie sich der Knowledge Graph von Google aktualisiert, indem er Fragen beantwortet. Der Schwerpunkt dieses Beitrags lag darauf, wie Google vorhandene Wissensgraphen aktualisieren könnte, anstatt Informationen über Entitäten auf Webseiten zu finden und sie zu erkennen, wie sie sich mit anderen Klassen von Entitäten verbinden können. Sich auf Wissensdatenbanken zu verlassen, anstatt das Web als große Datenbank zu behandeln, scheint ein Teilschritt zu sein. Wenn es möglich ist, Entitätenextraktionen auf intelligente und nützliche Weise durchzuführen, wäre es nicht notwendig, auf eine von Menschen moderierte Enzyklopädie im Web zu angewiesen zu sein. In der Vergangenheit hatte Google an einigen Stellen erklärt, dass sie webskalierbare Ansätze bevorzugen, um Informationen im Web zu organisieren (z. B. als sie das Google-Verzeichnis eingestellt haben, das aus einer Quelle stammte, die von Menschen stammte).
Dieses kürzlich veröffentlichte Patent offenbart einen anderen Ansatz, der Google dabei hilft, Entitäten-Extraktionen und andere Informationen über diese Entitäten aus Quellen durchzuführen, die dem Web hinzugefügt wurden, anstatt sie einer Wissensdatenbank im Web hinzuzufügen, einschließlich neuer Webseiten und Nachrichtenquellen.
Das Patent hat einen zusammenfassenden Abschnitt in seiner Beschreibung, in dem es uns über das Verfahren informiert, das es schützt. Es fasst diese in wenigen Worten wie folgt zusammen:
Die offenbarten Ausführungsformen können Systeme und Verfahren zum Bestimmen von Klassen und Attributen neuer Entitäten sowie Assoziationsbewertungen bereitstellen, die Grade der Verwandtschaft und Vertrauensniveaus in die bestimmten Beziehungen widerspiegeln. Die offenbarten Ausführungsformen können diese Klassen, Attribute und zugehörigen Bewertungen basierend auf umgebenden lexikalischen Kontexten bestimmen, in denen die neuen Entitäten erscheinen und bekannte Entitäten in der Nähe jeder neuen Entität sind. Aspekte der offenbarten Ausführungsformen stellen auch Systeme und Verfahren zum dynamischen Aktualisieren und Speichern bestimmter Beziehungen in Echtzeit oder nahezu in Echtzeit bereit.
Es erweitert diese etwas detaillierter, indem es uns einen schrittweisen Einblick in einen Prozess gibt, der als "Identifizierung von Kandidaten für Unternehmen" bezeichnet wird.
Identifizieren von Entitätskandidaten für Entitätsextraktionen
- Ein Entitätskandidat befindet sich in einem Dokument, auf das über ein Netzwerk zugegriffen werden kann.
- Der erkannte Entitätskandidat ist eine neue Entität basierend auf einem oder mehreren Entitätsmodellen, die in einer Datenbank gespeichert sind.
- Eine bekannte Entität befindet sich neben der neuen Entität und die bekannte Entität befindet sich in einem oder mehreren Entitätsmodellen.
- Ein Kontext neben der neuen Entität und der bekannten Entität hat eine lexikalische Beziehung zu der bekannten Entität.
- Eine zweite Entitätsklasse, die der bekannten Entität zugeordnet ist, und eine Kontextklasse sind ebenfalls mit dem Kontext verknüpft.
- Eine erste Entitätsklasse verbindet sich mit der neuen Entität basierend auf der zweiten Entitätsklasse und der Kontextklasse.
- Ein erster Eintrag in der Datenbank hängt von mindestens einem der Entitätsmodelle ab, wobei der Eintrag die Assoziation zwischen der ersten Entitätsklasse und der neuen Entität widerspiegelt.
Das Patent, in dem sich diese Entitäten-Kandidaten befinden, betrifft die Extraktion von Entitäten und das Speichern von Informationen über diese Entitäten:
Computergestützte Systeme und Methoden zum Extrahieren und Speichern von Informationen über Unternehmen
Erfinder: Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli und David Lecomte
Rechtsnachfolger: GOOGLE LLC
US-Patent: 10,198,491
Bewilligt: 5. Februar 2019
Gespeichert: 6. Juli 2015
Abstrakt
Computerimplementierte Systeme und Verfahren werden zum Extrahieren und Speichern von Informationen bezüglich Entitäten aus Dokumenten, wie beispielsweise Webseiten, bereitgestellt. In einer Implementierung wird ein System bereitgestellt, das einen Entitätskandidaten in einem Dokument erkennt und bestimmt, dass der erkannte Kandidat eine neue Entität ist. Das System erkennt auch eine bekannte Entität in der Nähe der bekannten Entität basierend auf dem einen oder den mehreren Entitätsmodellen. Das System erkennt auch einen Kontext in der Nähe der neuen und bekannten Entitäten, die eine lexikalische Beziehung zu der bekannten Entität haben. Das System bestimmt auch eine zweite Entitätsklasse, die der bekannten Entität zugeordnet ist, und eine Kontextklasse, die dem Kontext zugeordnet ist. Das System generiert auch eine erste Entitätsklasse basierend auf der zweiten Entitätsklasse und der Kontextklasse. Das System erzeugt auch einen Eintrag in dem einen oder den mehreren Entitätsmodellen, der eine Assoziation zwischen den neuen und den ersten Entitäten widerspiegelt.
Entitätsextraktionen – Entitäten, Entitätsklassen, Entitätsinstanzen und Entitätsattribute
Einer der ersten Schritte im Prozess dieses Patents beinhaltet das Erkennen von Entitäten. Das Patent enthält einige Informationen darüber, was Entitäten sind, und gibt uns mehrere Beispiele:
In bestimmten Aspekten kann eine Entität eine Person (z. B. George Washington), einen Ort (z. B. San Francisco, Wyoming, eine bestimmte Straße oder Kreuzung usw.) oder eine Sache (z. B. ein Stern, ein Auto, ein Politiker, ein Arzt, ein Gerät) widerspiegeln , Stadion, Person, Buch). Als weiteres Beispiel kann eine Entität ein Stück Literatur, eine Organisation (zB New York Yankees), eine politische Körperschaft oder Partei, ein Unternehmen, eine hoheitliche oder staatliche Körperschaft (zB die Vereinigten Staaten, die NATO, die FDA) usw.), ein Datum (zB 4. Juli 1776), eine Zahl (zB 60, 3.14159, e), ein Buchstabe, ein Zustand, eine Qualität, eine Idee, ein Konzept oder eine beliebige Kombination davon.
Zusätzlich zu diesen Definitionen einer Entität werden wir auch über Entitätsklassen und Unterklassen informiert und erfahren, wie Entitäten in verschiedene Klassen und Unterklassen passen können. Dies ist wichtig, da die Suchmaschine versucht, Entitäten in verschiedene Klassen einzuordnen, wenn sie von ihnen erfährt.
Was ist also eine Entitätsklasse oder Unterklasse?
Das Patent beschreibt diese ausführlich:
In einigen Aspekten kann eine Entität einer Entitätsklasse zugeordnet sein. Eine Entitätsklasse kann eine Kategorisierung, einen Typ oder eine Klassifizierung einer Gruppe oder eines fiktiven Modells von Entitäten darstellen. Zur Veranschaulichung können Entitätsklassen beispielsweise „Person“, „Galaxie“, „Baseballspieler“, „Baum“, „Straße“, „Politiker“ usw. umfassen. Eine Entitätsklasse kann einer oder mehreren Unterklassen zugeordnet sein . In einigen Aspekten kann eine Unterklasse eine Klasse von Entitäten widerspiegeln, die in einer größeren Klasse (zB einer „Überklasse“) zusammengefasst sind. In der obigen beispielhaften Klassenliste können beispielsweise die Klassen „Baseballspieler“ und „Politiker“ Unterklassen der Klasse „Person“ sein, da alle Baseballspieler und Politiker Menschen sind. In anderen Ausführungsformen können Unterklassen Klassen von Entitäten darstellen, die fast vollständig, aber nicht vollständig, Teil einer größeren Superklasse sind. Eine solche Vereinbarung kann in Situationen auftreten, die Ausreißer oder fiktive Einheiten enthalten. Beispielsweise kann die Klasse „Politiker“ eine Unterklasse der Klasse „Person“ sein, obwohl einige fiktive Entitäten nichtmenschliche Politiker sind (zB „Mas Amedda“). Die offenbarten Ausführungsformen stellen Wege bereit, diese Arten von Beziehungen zu handhaben und zu verwalten, wie unten weiter beschrieben wird. Sowohl Klassen als auch Unterklassen können Entitätsklassen darstellen und können selbst Entitäten darstellen.
Eine Dateninstanz ist ein Beispiel für eine bestimmte Entität, die in eine Klasse oder Unterklasse passt. Thomas Jefferson ist eine Instanz eines „US-Präsidenten“ und „Mike Trout“ ist eine spezielle Instanz eines „professionellen Baseballspielers“.
Das Patent arbeitet daran, Informationen über Entitäten zu sammeln, und es sammelt Informationen über Entitäten, die es als „Entitätsattribute“ bezeichnet. Wie in dieser Zeichnung aus dem Patent:

Dies können Eigenschaften von Entitäten und auch Beziehungen zwischen Entitätsklassen sein. Das Patent bietet auch einen tiefen Einblick in das, was ein Attribut sein kann:
Entitäten können einem oder mehreren Entitätsattributen und/oder Objektattributen zugeordnet sein. Ein Entitätsattribut kann in einigen Aspekten eine Eigenschaft, ein Merkmal, eine Eigenschaft, eine Qualität oder ein Element einer Entitätsklasse widerspiegeln. In einigen Aspekten teilt jede oder im Wesentlichen jede Instanz einer Entitätsklasse einen gemeinsamen Satz von Entitätsattributen. Beispielsweise kann die Entität „Person“ unter anderem mit den Entitätsattributen „Geburtsdatum“, „Geburtsort“, „Eltern“, „Geschlecht“ oder allgemein „hat Attribut“ verknüpft sein. In einem anderen Beispiel kann eine Entität „professionelles Sportteam“ mit Entitätsattributen wie „Standort“, „Jahresumsatz“, „Kader“ usw. verknüpft sein. In anderen Ausführungsformen kann ein Entitätsattribut beschreiben, wie sich eine Entität auf eine andere Entität bezieht. Entitätsattribute können beispielsweise Beziehungen zwischen Entitätsklassen beschreiben, wie etwa „ist eine“, „ist eine Unterklasse von“ oder „ist eine Oberklasse von“ oder „enthält“. Zum Beispiel kann die Klasse „Stern“ einem Entitätsattribut „ist eine Unterklasse von“ mit der Entitätsklasse „Himmelsobjekt“ zugeordnet sein.
Wenn es um die Extraktion von Entitäten geht, sehen wir am Ende Schlüssel-Wert-Paare, die uns mehr über bestimmte Entitäten erzählen:
In bestimmten Aspekten kann ein Objektattribut eine Beziehung zwischen einer Entitätsklasseninstanz mit einem bestimmten Attributwert widerspiegeln. Beispielsweise kann die Entität „George Washington“ mit einem Objektattribut „hat Geburtsdatum“ mit dem Wert „Feb. 22, 1732.“ In einigen Ausführungsformen kann der Wert eines Objektattributs selbst eine Entität widerspiegeln. Im obigen Beispiel wird beispielsweise das Datum „Feb. 22, 1732” kann eine Entität widerspiegeln.
Dieser Ansatz zum Sammeln von Informationen über Entitäten umfasst Attribute, die in Unterklassen üblich sein können, in denen diese vorhanden sind:
In einigen Ausführungsformen erben Entitäten und Unterklassen die Attribute von den Oberklassen, von denen sie abgeleitet sind. Beispielsweise kann die Klasse „US-Präsident“ das Attribut „Geburtsdatum“ von einer „Person“-Superklasse erben. Darüber hinaus erben Superklassen in bestimmten Ausführungsformen nicht unbedingt die Attribute ihrer Unterklassen. Beispielsweise erbt die Klasse „Person“ nicht unbedingt das Attribut „stolen bases“ von der Unterklasse „professional baseball player“ oder das Attribut „assumed office date“ von der Unterklasse „US President“.
Kontextdatenbanken und Entitätsextraktionen
Ich habe „Kontexte“ aus einigen der Schemata erkannt, die ich in der Vergangenheit gesehen habe. Es gibt ein anhängiges Schema-Vokabular, das den Begriff „Kennt über“ verwendet, mit dem Sie eine Person beschreiben können, die in einem bestimmten Beruf tätig ist und Erfahrung mit einer bestimmten Art hat. Diese Kontextbegriffe sind ähnlich, da sie dazu beitragen, mehr Informationen über Entitäten bereitzustellen, die Ihnen Informationen über sie geben. Die Passage über Kontextdatenbanken aus dem Patent beschreibt sie gut:
In einigen Ausführungsformen kann die Kontextdatenbank Informationen in Verbindung mit einem oder mehreren Kontexten speichern, in Beziehung setzen, verwalten und/oder bereitstellen. Ein Kontext kann eine lexikalische Konstruktion oder Darstellung eines oder mehrerer Wörter (zB eines Wortes, einer Phrase, eines Satzes, eines Absatzes usw.) widerspiegeln, die einem oder mehreren Wörtern (zB einer Entität) in seiner Nähe Bedeutung verleiht. In bestimmten Ausführungsformen befindet sich ein Kontext in einem N-Gramm. Ein n-Gramm kann eine Folge von n Wörtern widerspiegeln, wobei n eine positive ganze Zahl ist. Zum Beispiel kann ein Kontext 1-Gramm wie „ist“, „war“ oder „concurre“ enthalten. die zweite Basis gestohlen hat“ oder „eine Meinungsverschiedenheit geschrieben hat“. Kontexte (und N-Gramme) können auch Lücken beliebiger Länge enthalten, wie z. B. das 2-Gramm „from . . . noch bis . . . .“ Wie hierin beschrieben, kann ein n-Gramm eine beliebige derartige Sequenz darstellen, und zwei n-Gramm müssen nicht die Namensanzahl von Wörtern darstellen. Zum Beispiel können „ein Tor erzielt“ und „in der letzten Minute“ beide N-Gramm darstellen, obwohl sie eine unterschiedliche Anzahl von Wörtern enthalten.
Das Erlernen von Entitäten und Kontexten erfordert das Erlernen eines sinnvollen Vokabulars, da dies hilfreich sein kann, um zu erfahren, wie der Prozess hinter diesem Patent funktioniert und wie Google Data Mining betreiben kann, um Informationen über Entitäten, ihre Attribute, und Eigenschaften und die Kontexte, in denen wir sie sehen. Kontexte sind komplexer als nur ein kurzes N-Gramm, das dazu beiträgt, einer Entität Kontext bereitzustellen. Dieser nächste Abschnitt des Patents informiert uns über Kontextklassen und Kontextentitäten:
In bestimmten Ausführungsformen kann ein Kontext das potenzielle Vorhandensein einer oder mehrerer Entitäten anzeigen. Die eine oder mehreren potentiellen Entitäten, die durch einen Kontext spezifiziert werden, können hierin als „Kontextklassen“ oder „Kontextentitäten“ bezeichnet werden. Diese Bezeichnungen dienen jedoch nur illustrativen Zwecken, da sie nicht einschränkend sein sollen. Kontextklassen können einen Satz von Klassen widerspiegeln, die typischerweise in Verbindung mit dem Kontext auftreten (z. B. eine lexikalische Beziehung zu diesem aufweisen). In einigen Aspekten können „Kontextklassen“ spezifische Entitätsklassen widerspiegeln. Beispielsweise kann der Kontext „ist verheiratet mit“ einer Kontextklasse der Entität „Person“ zugeordnet sein, da der Kontext „ist verheiratet mit“ normalerweise eine lexikalische Beziehung zu Menschen hat (z. B. eine lexikalische Beziehung zu Instanzen hat). der Klasse „Person“). In diesem Beispiel zeigt beispielsweise der Satz „Jack ist mit Jill verheiratet“ an, dass sowohl „Jack“ als auch „Jill“ der Klasse „Person“ angehören, zumindest teilweise aufgrund der Kontextklasse(n) des Kontexts "ist verheiratet mit." In einem anderen Beispiel kann der Kontext „hat ein Haustier“ mit Kontextklassen wie „Tier“, „Katze, „Hund“, „Haustier“ und dergleichen verknüpft sein. Darüber hinaus kann in diesem alternativen Beispiel der Kontext „hat ein Haustier“ das Vorhandensein von Entitätsklassen signalisieren, die nicht koextensiv sind, da zwei Instanzen derselben Klasse typischerweise keine lexikalische Beziehung teilen (z. B. eine Haustier-Master-Attributbeziehung). . Die Interpretation und Generierung von Kontextklassen werden im Folgenden näher erläutert.
Assoziations-Scores mit Entitätsextraktionen
Das Patent geht detaillierter auf Kontextklassen und Kontextentitäten ein, und diese sind es wert, genauer betrachtet zu werden. Aber ein Abschnitt des Patents, der es wert schien, etwas darüber zu erfahren, bezog sich auf die Berechnung von Assoziationswerten während der Extraktion von Entitäten:
In einigen Aspekten können die Entitätsdatenbank und/oder die Kontextdatenbank auch Informationen bezüglich einer oder mehrerer Assoziationsbewertungen speichern. Eine Assoziationsbewertung kann eine Wahrscheinlichkeit oder einen Vertrauensgrad widerspiegeln, dass ein Attribut, ein Attributwert, eine Beziehung, eine Klassenhierarchie, eine bestimmte Kontextklasse oder eine andere derartige Assoziation gültig, korrekt und/oder legitim ist. Beispielsweise kann in einigen Ausführungsformen eine Assoziationsbewertung einen Grad der Verwandtschaft zwischen zwei Entitäten oder einem Kontext und einer Entität widerspiegeln. Assoziationsbewertungen können über einen beliebigen Prozess in Übereinstimmung mit den offenbarten Ausführungsformen bestimmt werden. Wie unten ausführlicher erläutert wird, kann ein Computersystem (z. B. ein Server) beispielsweise Assoziationsbewertungen unter Verwendung von Faktoren und Gewichten bestimmen, wie z zwei Entitäten im Inhalt (z. B. als Funktion der Gesamtvorkommen, die Gesamtzahl der Dokumente, die eine oder beide Entitäten enthalten usw.), die Attribute der Entitäten selbst (z. B. ob eine Entität eine Unterklasse einer anderen ist), die Aktualität der entdeckten Beziehungen (z. B. indem neueren oder älteren Assoziationen mehr Gewicht beigemessen wird), ob ein Attribut eine bekannte Neigung zu Schwankungen aufweist (z. B. periodisch oder sporadisch), die relative Anzahl von Instanzen zwischen Entitätsklassen, die Popularität der Entitäten als ein Paar, die durchschnittliche, mediane, statistische und/oder gewichtete Nähe zwischen zwei Entitäten in analysierten Dokumenten und/oder jedem anderen hierin offenbarten Prozess. In einigen Aspekten kann das System selbst eine oder mehrere Zuordnungsbewertungen erzeugen. In bestimmten Aspekten kann das System eine oder mehrere Assoziationsbewertungen basierend auf vorgenerierten Datenstrukturen (zB in den Datenbanken 140 und/oder 150 gespeichert) vorab laden.

Interessanterweise können Dinge wie die Zuverlässigkeit von Quellen eine Rolle bei den Assoziationswerten spielen, die einer Beziehung zwischen einer Entität oder einem Kontext und einer Entität zugewiesen werden. Der nächste Abschnitt befasst sich mit dem, was sie „das Verhältnis von gemeinsamen Vorkommnissen zwischen einem Kontext und einer Entität“ nennen:
In einer Ausführungsform kann beispielsweise ein Computersystem (z. B. ein Server) eine Assoziationsbewertung zwischen einem Kontext und einer Entität durch Bestimmen des Verhältnisses von gemeinsamen Vorkommnissen zwischen dem Kontext und der Entität (z. B. der spezifischen Entität, einer Instanz von die Entitätsklasse usw.) auf alle Vorkommen dieses Kontexts und/oder dieser Entität in Netzwerkdokumenten. Ein veranschaulichender Ausdruck kann beispielsweise die Form A=P(E, C)/P(C) annehmen, wobei A ein beispielhafter Assoziationswert zwischen der Entität und dem Kontext ist, P(C) die Wahrscheinlichkeit ist, den Kontext zu finden in einem Textabschnitt (z. B. einem Dokument, einer oder mehreren Webseiten, einem Korpus usw.), und P(E, C) ist die Wahrscheinlichkeit, dass beide Kontextentitäten gleichzeitig in dem Abschnitt vorkommen. In diesem Beispiel kann die Assoziationsbewertung die bedingte Wahrscheinlichkeit des Auffindens einer Entität E widerspiegeln, wenn der Kontext C erscheint. Ein anderer veranschaulichender Ausdruck für eine Assoziationsbewertung kann die Form A=N(E, C)/(N(E)+N(C) – N(E, C)) annehmen, wobei N(E) die Anzahl der Instanzen ist die Entität erscheint in einem Abschnitt (z. B. einem Korpus), N(C) ist die Anzahl der Instanzen, die der Kontext im Abschnitt vorkommt, und N(E, C) ist die Anzahl der Instanzen von Entität E und Kontext C, die zusammen vorkommen im Bereich. Ähnliche Ausdrücke können verwendet werden, um Assoziationsbewertungen zwischen zwei Entitäten zu erzeugen.
Dieses Beispiel für bestimmte Entitätsklassen und Kontexte macht deutlich, wie Assoziationsbewertungen helfen können zu verstehen, wie nützlich solche Bewertungen sein könnten:
Beispielsweise kann der Server bestimmen, dass der Kontext „erhält einen Pass von“ zusammen mit Instanzen der Entitätsklassen „Basketballspieler“ und „Person“ in 35 und 97 Prozent der Fälle vorkommt, in denen der Kontext in allen analysierten Dokumenten vorkommt. bzw. Das System kann diese Häufigkeiten des gemeinsamen Auftretens bestimmen, indem es zumindest teilweise Entitäts- und Kontextmodelle verwendet, um Beziehungen zwischen Entitäten zu bestimmen (z. B. um zu bestimmen, dass „LeBron James“ eine Instanz der Klasse „Basketballspieler“ ist). In diesem Beispiel kann der Server bestimmen, dass die Assoziationsergebnisse in Bezug auf den Kontext „erhält einen Pass von“ zu „Basketballspieler“ und „Person“ 0,35 bzw. 0,97 betragen.
Beachten Sie, dass diese gemeinsamen Vorkommnisse aus über einem Korpus von Dokumenten stammen und nicht aus einem.
Wir haben einige andere Beispiele für andere Faktoren, die bei der Berechnung der Assoziationspunkte eine Rolle spielen können:
Assoziationsbewertungen können andere Überlegungen berücksichtigen, indem sie eine oder mehrere Gewichtungen für jedes Vorkommen einer Entität oder eines Kontexts einbeziehen. In einigen Aspekten kann das Computersystem Gewichtungen anwenden, um Faktoren wie etwa zeitliche Gewichtungen (z. B. um neuere Dokumente oder Vorkommnisse stärker zu gewichten), Zuverlässigkeitsgewichtungen (z. um populärere Quellen stärker zu gewichten), Näherungsgewichte (z. B. um Entitäten/Kontexte, die in engerer Nähe zueinander auftreten, stärker zu gewichten) und jede andere Art von Gewichtung, die mit den offenbarten Ausführungsformen übereinstimmt. In bestimmten Aspekten kann eine Gewichtung die relative Bedeutung eines bestimmten Dokuments oder einzelnen Vorkommens im Vergleich zu anderen widerspiegeln (z. B. summieren sich die Gewichte für alle Vorkommen auf 1,0), die Bedeutung eines Dokuments oder Vorkommens auf einer absoluten Skala (z eine unabhängige Bewertung widerspiegelt) oder jedes andere Maß, das die Verwandtschaft zwischen zwei Entitäten oder Kontexten anzeigt (z. B. die Nähe zwischen einem Kontext und einer Entität).
Was kann ein niedriger Assoziationswert bedeuten?
Somit kann in einigen Ausführungsformen eine niedrige Assoziationsbewertung anzeigen, dass eine Datenquelle, auf der eine Beziehung basiert, im Allgemeinen nicht vertrauenswürdig oder unzuverlässig ist. In anderen Ausführungsformen kann eine niedrige Assoziationsbewertung anzeigen, dass gemeinsame Vorkommen des Subjektpaars in neueren Dokumenten nicht vorkommen. In noch anderen Ausführungsformen kann eine niedrige Assoziationspunktzahl anzeigen, dass das gemeinsame Auftreten zwischen dem Paar selten ist (z. B. sind wenige „Politiker“ „professionelle Basketballspieler“). In noch anderen Ausführungsformen kann die Assoziationsbewertung eine Kombination vieler solcher Faktoren widerspiegeln. In einigen Aspekten kann ein System (z. B. ein Server oder ein Computersystem in Verbindung mit Datenbanken) Assoziationsbewertungen im Laufe der Zeit aktualisieren und modifizieren (z. B. basierend auf neuen Dokumenten, Kontexten und Attributen).
Assoziationspunkte geben uns eine Vorstellung von Wahrscheinlichkeiten:
Eine Assoziationsbewertung kann die Form einer numerischen Zahl (z. B. 0,0 bis 1,0, 0 bis 100 usw.), einer qualitativen Skala (z. B. unwahrscheinlich, wahrscheinlich, sehr wahrscheinlich), einer farbcodierten Skala und/oder einer beliebigen . annehmen andere Maß- oder Bewertungsschemata, die in der Lage sind, Abschlüsse zu spezifizieren. Beispielsweise kann in einer Ausführungsform eine Entitätsdatenbank eine Zuordnungsbewertung von 0,84 speichern, was widerspiegelt, dass die Wahrscheinlichkeit, dass die Entität „Bryce Harper“ mit einem Attribut „Geburtsdatum“ mit einem Wert „Okt. 16., 1992.“ Dies kann zum Beispiel darauf hinweisen, dass das System Bryce Harpers Geburtsdatum mit einer Genauigkeit von 84 % als den 16. Oktober 1992 ansieht. Außerdem kann „Bryce Harper“ einer Entitätsklasse „Person“ über das Attribut oder die Beziehung „ist a“ mit einem Assoziationswert von 1,0 zugeordnet werden, was eine Gewissheit anzeigt, dass Bryce Harper eine Person ist. In einem anderen Beispiel kann der Kontext „hat ein Tor geschossen“ den Kontextklassen „Fußballspieler“, „Hockeyspieler“ und „Person“ mit Assoziationswerten von 0,64, 0,49 bzw. 0,98 zugeordnet sein. Diese beispielhaften Werte können beispielsweise anzeigen, dass es wahrscheinlicher ist, dass der Kontext eher Fußballspieler als Hockeyspieler betrifft, und noch wahrscheinlicher, dass sich der Satz auf eine oder mehrere Personen bezieht, im Allgemeinen gegenüber Fußballspielern im Besonderen. Wie oben angegeben, können die eine oder mehreren Entitätsdatenbanken (z. B. Entitätsdatenbank) und Kontextdatenbanken (z. B. Kontextdatenbank), der Server und/oder das Clientgerät Entitäten, Attribute, Kontexte, Kontextklassen, Assoziationsbewertungen und alle anderen Informationen in irgendeiner Form in Übereinstimmung mit den offenbarten Ausführungsformen.
Wissensgraphen mit Assoziationswerten während der Entitätsextraktion
Das Patent beschreibt ein Beispiel für einen Wissensgraphen mit Assoziationsbewertungen, die in jeder Kante enthalten sind, die Entitäten mit Attributen oder Werten verbindet:
In einigen Aspekten kann der Wissensgraph eine Vielzahl von Knoten umfassen, wobei jeder Knoten eine Entität widerspiegelt. Der Wissensgraph kann auch eine oder mehrere Kanten enthalten, die Attribute widerspiegeln, die Beziehungen zwischen den Entitäten und den Werten bestimmter Attribute beschreiben. In bestimmten Ausführungsformen kann der Wissensgraph auch eine Assoziationsbewertung für jede darin enthaltene Kante (zB jedes Attribut oder zugeordnete Wert) enthalten, obwohl solche Assoziationsbewertungen nicht erforderlich sind. In dem veranschaulichenden Wissensgraphen, der in FIG. In 2A ist beispielsweise der Entitätsknoten „Bryce Harper“, der eine bestimmte Entität widerspiegelt, mit einer anderen Entität, „Washington Nationals“, über das Objektattribut „spielt für“ mit einer Assoziationspunktzahl von 0,96 verbunden. Diese Werte und Beziehungen können zum Beispiel darauf hinweisen, dass Bryce Harper ein Spieler der Washington Nationals ist und dass das System diesem Attribut einen Vertrauensgrad von 0,96 zuordnet. Die Entität „Washington Nationals“ selbst kann anderen nicht gezeigten Entitäten zugeordnet sein, was durch die vom Knoten ausgehenden Strichlinien angezeigt wird. Andere Einheiten sind in den Fig. 1 und 2 dargestellt. 2A – 2C und 3 können in ähnlicher Weise anderen nicht gezeigten Knoten und Attributen zugeordnet werden, und die Darstellung bestimmter Beziehungen und Werte darin dient lediglich der Veranschaulichung.
Die Assoziationsbewertungen können ein Gefühl des Vertrauens in die Richtigkeit einer Tatsache vermitteln, die sich auf eine Entität bezieht. Eine weitere Reihe von Beispielen im Zusammenhang mit Bryce Harper:
FEIGE. 2A zeigt auch das Zuordnen des Knotens „Bryce Harper“ mit dem Datumsentitätsknoten „Okt. 16, 1992“ und den Wertentitätsknoten „60 Home Runs“ über die Attribute „hat Geburtstag“ bzw. „hat Karriere HR insgesamt“. Diese Attribute haben entsprechende Assoziationsbewertungen von 0,84 und 0,37, was darauf hinweist, dass das System dem Wert, der mit der Attributbeziehung „hat Geburtsdatum“ verbunden ist, sicherer ist als dem Wert, der mit „hat Karriere-HR-Gesamt“ verbunden ist. Der Unterschied in diesen Assoziationswerten kann beispielsweise aufgrund der Zuverlässigkeit der Quellen, die verwendet werden, um solche Beziehungen zu erzeugen, der Häufigkeit des gemeinsamen Auftretens zwischen den Entitäten, der Tatsache, dass einer der Werte der Attribute (Knoten 204) ist sich mit der Zeit ändern und/oder andere Faktoren, die mit den offenbarten Ausführungsformen übereinstimmen.
Stellen Sie sich einen riesigen Wissensgraphen vor, der viele verschiedene Typen abdeckt, von denen jeder viele Eigenschaften oder Attribute hat, und Assoziationsbewertungen, die Konfidenzniveaus zwischen den Entitäten und Klassen und Unterklassen bereitstellen. Das Patent zeigt uns, dass dies wahrscheinlich wäre:
Ein Entitätsknoten kann auch Entitätsklassen und Unterklassen zugeordnet sein, die über Attribute verbunden sind, die die Art der Beziehung zwischen einer Entität und einer Entitätsklasse beschreiben. Zum Beispiel FIG. 2A zeigt Verbindungen zwischen dem Knoten „Bryce Harper“ und den Entitätsklassen „Person“ und „professioneller Baseballspieler“ über jeweilige Kanten „ist ein“ und „hat einen Beruf“. Diese Attribute haben Assoziationsbewertungen von 1,0 bzw. 0,99. Die veranschaulichenden Attribute und Verbandsbewertungen zeigen, dass das System Bryce Harper mit Sicherheit oder fast mit Sicherheit als eine Person ansieht, deren Beruf ein professioneller Baseballspieler ist.
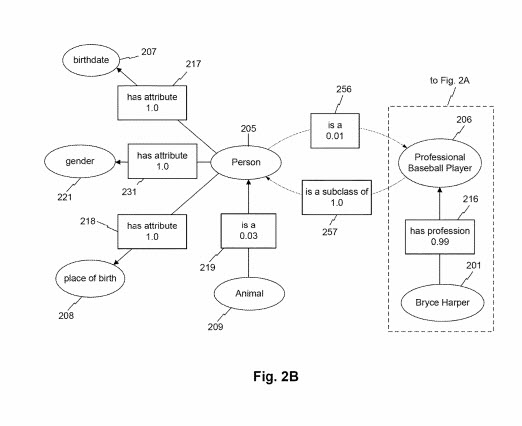
Wir lernen auch aus niedrigen Assoziationswerten über Entitätsklassen und andere Entitätsklassen:
Wie in FIG. In 2B kann eine Entitätsklasse auch anderen Entitätsklassen durch Entitätsattribute zugeordnet werden. Beispielsweise kann die Klasse „Tier“ der Klasse „Person“ über das Attribut „ist ein“ zugeordnet werden. In diesem Beispiel beträgt die dem Attribut entsprechende Assoziationsbewertung 0,03. Dies kann zum Beispiel darauf hinweisen, dass Fälle der Klasse „Tier“ 209 seltene Fälle der Klasse „Person“ sind (z. B. aufgrund der Prävalenz nichtmenschlicher Tiere wie andere Säugetiere, Insekten, Vögel, Fische usw.). Obwohl es in FIG. In 2B kann der Klasse „Person“ ein reziprokes Attribut „ist ein“ oder „ist eine Unterklasse von“ usw. in Verbindung mit dem „Tier“-Knoten zugeordnet sein. Ein solches Attribut kann mit einem höheren Assoziationswert (z. B. 0,94) verbunden sein, was darauf hinweist, dass die Klasse „Person“ eine Unterklasse von „Tier“ ist. Zum Beispiel FIG. 2B stellt die Klasse „professioneller Baseballspieler“ dar, die mit der Klasse „Person“ mit dem Entitätsattribut „ist eine Unterklasse von“ mit Assoziationspunktzahl 1,0 assoziiert. Im Gegensatz dazu kann der Klassenknoten „Person“ über das Attribut „ist a“ mit einem Assoziationsscore von 0,01 dem Knoten „Profi-Baseballspieler“ zugeordnet werden. Diese niedrigere Assoziationspunktzahl kann zum Beispiel die starke Prävalenz von Entitäten der Klasse „Person“ widerspiegeln, die nicht der Klasse „professioneller Baseballspieler“ angehören (z. B. sind die meisten Menschen keine professionellen Baseballspieler). FEIGE. 2B zeigt ferner, wie der Klassenknoten professioneller Baseballspieler mit dem Entitätsknoten „Bryce Harper“ über das Attribut „hat einen Beruf“ assoziieren kann, wie in Verbindung mit 1 erörtert. 2A.
Assoziationen zwischen Entitätstypen und Kontextklassen in einem Kontextdiagramm können uns spezifische Informationen über diese Entitätstypen und Kontexte liefern:
In einigen Ausführungsformen können die im Kontextgraphen enthaltenen Entitätsklassen Kontextklassen darstellen, die mit einem bestimmten Kontext (zB Kontext) verbunden sind. In solchen Ausführungsformen kann eine Assoziationsbewertung, die Kontexte mit ihren Kontextklassen (und allen eingeschlossenen Unterklassen usw.) verknüpft, einen Gültigkeitsgrad oder Bezugsgrad zwischen der Kontextklasse und dem Kontext (z. B. Rand) und/oder den Bezugsgrad widerspiegeln zwischen Entitätsklassen selbst (zB Edge). In einigen Aspekten kann die Assoziationsbewertung somit eine Wahrscheinlichkeit widerspiegeln, dass der Kontext das Vorhandensein der zugeordneten Kontextklasse oder einer Instanz dieser Kontextklasse signalisiert. Wie beispielsweise in FIG. In 2D kann der Kontextknoten „empfangen(en) einen Pass von” fünf Kontextklassen zugeordnet sein. In diesem Beispiel ist der Kontext „einen Pass erhalten von“ den Kontextklassen „Person“, „Baseballspieler“, „Basketballspieler“, „Hockeyspieler“ und „Fußballspieler“ zugeordnet eine entsprechende Assoziationsbewertung, wie z. B. Bewertungen. Diese Assoziationsbewertungen werden mit der begleitenden Phrase „takes class“ veranschaulicht, um eine Wahrscheinlichkeit oder Wahrscheinlichkeit anzugeben, dass der Kontext das Vorhandensein einer bestimmten Klasse oder Klasseninstanz anzeigt.
Da es beispielsweise selten vorkommt, dass ein Mitglied der Klasse „Baseballspieler“ von einem anderen Spieler „einen Pass erhält(n)“ (Kontext), beträgt die dieser Kontextklasse zugeordnete Assoziationspunktzahl 0,02, wie in der Position gezeigt . Wie oben erläutert, kann dieser Wert aus der Häufigkeit des gemeinsamen Auftretens zwischen dem Kontext und einer Instanz der Klasse „Baseballspieler“ über Netzwerkquellen, der Zuverlässigkeit dieser Quellen usw. generiert werden. Im Gegensatz dazu wird die Zuordnung zwischen Kontext und die übrigen Entitätsklassen sind relativ höher. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019