
Google의 지식 정보를 위한 항목 추출
게시 됨: 2019-02-15<
Google은 페이지의 항목 추출, 항목 클래스, 항목 속성 및 연관 점수를 사용하여 지식 정보를 작성할 수 있습니다.
Google이 2012년 지식 정보를 도입했을 때 문자열이 아닌 사물에 초점을 맞추고 실제 객체를 인덱싱하기 시작할 것이라고 말했습니다. 그 과정은 성숙해지고 있으며 우리는 Google이 페이지 및 링크와 같은 웹 정보를 마이닝하는 대신 데이터를 마이닝하고 엔티티 추출에 참여하기 위해 웹 크롤링을 시작하는 방법을 배우는 것을 볼 기회가 있습니다. 내가 최근에 트위터에 이것에 대해 썼듯이:
웹 크롤링에서 노드는 페이지이고 에지는 페이지 간의 링크입니다. 데이터 크롤링에서 노드는 엔터티이고 에지는 엔터티 간의 관계입니다. 웹에 대한 생각의 진화입니다.
— Bill Slawski(@bill_slawski) 2019년 2월 10일
최근에 부여된 Google 특허는 검색 엔진이 웹 페이지에서 엔티티 추출을 수행하고 이에 대한 정보를 저장하는 방법에 대해 알려줍니다. 이것은 엔터티에 대한 정보 소스로 지식 기반을 사용하는 것을 넘어 웹 페이지의 텍스트 구절을 살펴봄으로써 그러한 소스에서 사용할 수 있는 것보다 더 많은 것을 찾습니다. 이것은 아마도 우리가 Wikipedia와 같은 과거보다 더 많은 출처에서 지식 결과를 보게 될 것임을 의미합니다. 이 특허가 특허의 초기 라인에서 해결하는 문제:
기존의 지식 기반이지만 사용자가 원하는 엔터티 및 기타 정보에 대한 최신 정보 또는 신뢰할 수 있는 정보를 제공하지 못할 수 있습니다.
우리는 Google이 Wikipedia 및 IMDB와 같은 장소의 테이블 및 콜론으로 구분된 목록에서 항목을 추출하는 것을 보았습니다. 웹 페이지에서 해당 정보를 찾고 해당 페이지에서 엔터티를 추출하고 웹 페이지를 크롤링할 때 해당 엔터티에 대한 속성과 속성을 수집할 수 있다면 어떨까요? 해당 엔터티와 해당 엔터티에 대한 정보의 신뢰도 수준을 측정하는 방법도 있을 수 있습니다.

이 특허 이미지에서 볼 수 있듯이 Google은 엔터티와 연결된 속성 간의 연결 점수를 계산합니다(연결 점수에 대한 자세한 내용은 아래 참조).
나는 다음 게시물에서 비슷한 내용을 썼습니다: How Google's Knowledge Graph Updates Itself by Answering Questions. 이 게시물의 초점은 웹 페이지에서 엔터티에 대한 정보를 찾고 이를 인식하여 다른 엔터티 클래스와 결합하는 방법보다 Google이 기존 지식 그래프를 업데이트하는 방법이었습니다. 웹을 대규모 데이터베이스로 취급하는 대신 지식 기반에 의존하는 것은 부분적인 단계처럼 보입니다. 지능적이고 유용한 방식으로 엔티티 추출을 수행할 수 있다면 웹에서 인간이 중재하는 백과사전이 필요하지 않을 것입니다. 과거 몇 곳에서 Google은 웹에서 정보를 구성하기 위해 웹 확장 가능한 접근 방식을 선호한다고 말했습니다(예: 사람들이 소스에서 가져온 Google 디렉토리를 중단했을 때).
이 최근 특허는 Google이 새로운 웹 페이지 및 뉴스 소스를 포함하여 웹의 지식 기반에 추가하는 대신 웹에 추가된 소스에서 해당 엔티티에 대한 엔티티 추출 및 기타 정보를 수행하는 데 도움이 되는 다른 접근 방식을 공개합니다.
특허의 설명에는 보호하는 프로세스에 대해 설명하는 요약 섹션이 있습니다. 다음과 같이 몇 마디로 요약합니다.
개시된 실시예는 새로운 엔티티의 클래스 및 속성을 결정하기 위한 시스템 및 방법, 뿐만 아니라 결정된 관계에서 관련성의 정도 및 신뢰 수준을 반영하는 연관 스코어를 제공할 수 있다. 개시된 실시예는 새로운 엔티티가 나타나고 각각의 새로운 엔티티에 근접한 알려진 엔티티가 있는 주변 어휘 컨텍스트에 기초하여 이러한 클래스, 속성 및 관련 점수를 결정할 수 있다. 개시된 실시예의 양태는 또한 실시간 또는 거의 실시간으로 결정된 관계 를 동적으로 업데이트하고 저장하기 위한 시스템 및 방법을 제공한다.
"엔티티 후보 식별"이라고 하는 프로세스를 단계별로 살펴봄으로써 좀 더 자세히 설명합니다.
엔티티 추출을 위한 엔티티 후보 식별
- 엔티티 후보는 네트워크를 통해 액세스할 수 있는 문서에 있습니다.
- 탐지된 엔터티 후보는 데이터베이스에 저장된 하나 이상의 엔터티 모델을 기반으로 하는 새 엔터티입니다.
- 알려진 엔터티는 새 엔터티 옆에 있고 알려진 엔터티는 하나 이상의 엔터티 모델에 있습니다.
- 새 엔터티 및 알려진 엔터티 옆에 있는 컨텍스트는 알려진 엔터티와 어휘 관계가 있습니다.
- 알려진 엔티티 및 컨텍스트 클래스와 연관된 두 번째 엔티티 클래스도 컨텍스트와 연관됩니다.
- 첫 번째 엔터티 클래스는 두 번째 엔터티 클래스 및 컨텍스트 클래스를 기반으로 새 엔터티와 연결됩니다.
- 데이터베이스의 첫 번째 항목은 항목 모델 중 하나 이상에 따라 달라지며 항목은 첫 번째 항목 클래스와 새 항목 간의 연관을 반영합니다.
이 엔터티 후보가 있는 특허는 엔터티 추출 및 해당 엔터티에 대한 정보 저장에 대한 것입니다.
엔티티에 관한 정보를 추출하고 저장하기 위한 컴퓨터화된 시스템 및 방법
발명가: Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli 및 David Lecomte
양수인: GOOGLE LLC
미국 특허: 10,198,491
부여됨: 2019년 2월 5일
출원일: 2015년 7월 6일
추상적 인
웹페이지와 같은 문서로부터 엔티티에 관한 정보를 추출 및 저장하기 위한 컴퓨터 구현 시스템 및 방법이 제공됩니다. 일 구현에서, 문서에서 엔티티 후보를 검출하고 검출된 후보가 새로운 엔티티임을 결정하는 시스템이 제공된다. 시스템은 또한 하나 이상의 개체 모델을 기반으로 알려진 개체에 근접한 알려진 개체를 감지합니다. 시스템은 또한 알려진 엔터티와 어휘 관계가 있는 새 엔터티와 알려진 엔터티에 근접한 컨텍스트를 감지합니다. 시스템은 또한 알려진 엔티티와 연관된 두 번째 엔티티 클래스 및 컨텍스트와 연관된 컨텍스트 클래스를 결정합니다. 시스템은 또한 두 번째 엔티티 클래스와 컨텍스트 클래스를 기반으로 첫 번째 엔티티 클래스를 생성합니다. 시스템은 또한 새로운 엔티티와 첫 번째 엔티티 간의 연관을 반영하는 하나 이상의 엔티티 모델에 항목을 생성합니다.
엔티티 추출 - 엔티티, 엔티티 클래스, 엔티티 인스턴스 및 엔티티 속성
이 특허와 관련된 프로세스의 첫 번째 단계 중 하나는 엔티티를 인식하는 것입니다. 이 특허는 엔티티가 무엇인지에 대한 몇 가지 정보를 제공하고 몇 가지 예를 제공합니다.
특정 측면에서 엔터티는 사람(예: George Washington), 장소(예: 샌프란시스코, 와이오밍, 특정 거리 또는 교차로 등) 또는 사물(예: 스타, 자동차, 정치인, 의사, 장치)을 반영할 수 있습니다. , 경기장, 사람, 책). 추가 예로서, 엔터티는 문헌, 조직(예: New York Yankees), 정치 단체 또는 정당, 기업, 주권 또는 정부 기관(예: 미국, NATO, FDA)을 반영할 수 있습니다. 등), 날짜(예: 1776년 7월 4일), 숫자(예: 60, 3.14159, e), 문자, 상태, 품질, 아이디어, 개념 또는 이들의 조합.
엔터티에 대한 이러한 정의 외에도 엔터티 클래스 및 하위 클래스, 엔터티가 다른 클래스 및 하위 클래스에 맞는 방법에 대해서도 설명합니다. 이것은 검색 엔진이 엔티티에 대해 학습할 때 엔티티를 다른 클래스에 맞추려고 하기 때문에 중요합니다.
그렇다면 엔티티 클래스 또는 하위 클래스는 무엇입니까?
이 특허는 다음을 자세히 설명합니다.
일부 양상들에서, 엔티티는 엔티티 클래스와 연관될 수 있다. 엔터티 클래스는 엔터티의 그룹 또는 개념적 모델의 범주화, 유형 또는 분류를 나타낼 수 있습니다. 예를 들어, 엔티티 클래스는 "사람", "은하수", "야구 선수", "나무", "도로", "정치인" 등을 포함할 수 있습니다. 엔티티 클래스는 하나 이상의 하위 클래스와 연관될 수 있습니다. . 일부 양상들에서, 서브클래스는 더 큰 클래스(예를 들어, "수퍼클래스")에 포함된 엔티티들의 클래스를 반영할 수 있습니다. 예를 들어 위의 예시적인 클래스 목록에서 "야구 선수"와 "정치인" 클래스는 "사람" 클래스의 하위 클래스일 수 있습니다. 왜냐하면 모든 야구 선수와 정치인은 인간이기 때문입니다. 다른 실시예에서, 서브클래스는 더 큰 슈퍼클래스의 일부이지만 완전히는 아니지만 거의 전부인 엔티티의 클래스를 나타낼 수 있습니다. 이러한 배열은 이상값이나 가상의 개체가 포함된 상황에서 발생할 수 있습니다. 예를 들어, 일부 가상 개체가 비인간 정치인(예: "Mas Amedda")인 경우에도 "정치인" 클래스는 "사람" 클래스의 하위 클래스일 수 있습니다. 개시된 실시예는 아래에서 추가로 설명되는 바와 같이 이러한 종류의 관계를 처리하고 관리하는 방법을 제공합니다. 클래스와 하위 클래스는 모두 엔터티 클래스를 나타낼 수 있으며 엔터티 자체를 구성할 수 있습니다.
데이터 인스턴스는 클래스 또는 하위 클래스에 맞는 특정 엔터티의 예입니다. Thomas Jefferson은 "미국 대통령"의 예이고 "Mike Trout"은 "프로 야구 선수"의 특정 예입니다.
이 특허는 엔터티에 대한 정보를 수집하는 작업을 하며 "엔티티 속성"이라고 하는 엔터티에 대한 정보를 수집합니다. 특허의 이 도면에서와 같이:

여기에는 엔터티의 속성과 엔터티 클래스 간의 관계가 포함될 수 있습니다. 이 특허는 속성이 무엇인지에 대해서도 자세히 설명합니다.
엔티티는 하나 이상의 엔티티 속성 및/또는 객체 속성과 연관될 수 있습니다. 엔티티 속성은 일부 측면에서 엔티티 클래스의 속성, 특성, 특성, 품질 또는 요소를 반영할 수 있습니다. 일부 측면에서 엔티티 클래스의 모든 또는 실질적으로 모든 인스턴스는 공통 엔티티 속성 세트를 공유합니다. 예를 들어, 엔티티 "사람"은 엔티티 속성 "생년월일", "출생지", "부모", "성별" 또는 일반적으로 "속성이 있음"과 연관될 수 있습니다. 다른 예에서, 엔티티 "프로 스포츠 팀"은 "위치", "연간 수익", "명단" 등과 같은 엔티티 속성과 연관될 수 있습니다. 다른 실시예에서, 엔티티 속성은 엔티티가 다른 엔티티와 어떻게 관련되는지를 기술할 수 있다. 예를 들어, 엔티티 속성은 "~이다", "~의 하위 클래스", "~의 상위 클래스" 또는 "포함"과 같은 엔티티 클래스 간의 관계를 설명할 수 있습니다. 예를 들어, 클래스 "star"는 엔티티 속성 "is subclass of"와 엔티티 클래스 "celestial object"와 연관될 수 있습니다.
엔터티 추출과 관련하여 특정 엔터티에 대해 자세히 알려주는 데 사용되는 키-값 쌍이 표시됩니다.
특정 양상에서, 객체 속성은 엔티티 클래스 인스턴스와 특정 속성 값 사이의 관계를 반영할 수 있습니다. 예를 들어, 엔티티 "George Washington"은 "Feb. 1732년 2월 22일.” 일부 실시예에서, 객체 속성의 값은 그 자체가 엔티티를 반영할 수 있다. 예를 들어 위의 예에서 날짜 "Feb. 22, 1732"는 개체를 반영할 수 있습니다.
엔터티에 대한 정보를 수집하는 이 접근 방식에는 다음 내에 존재하는 하위 클래스에서 공통적일 수 있는 속성이 포함됩니다.
일부 실시예에서, 엔티티 및 서브클래스는 이들이 파생되는 슈퍼클래스로부터 속성을 상속합니다. 예를 들어, "US President" 클래스는 "person" 슈퍼클래스에서 "birthdate" 속성을 상속할 수 있습니다. 더욱이, 특정 실시예에서 슈퍼클래스는 반드시 서브클래스의 속성을 상속하지 않을 수 있습니다. 예를 들어, "사람" 클래스는 "프로야구 선수" 하위 클래스에서 "도둑질된 기지" 속성을 상속하거나 "미국 대통령" 하위 클래스에서 "임시 날짜" 속성을 반드시 상속하지 않을 수 있습니다.
컨텍스트 데이터베이스 및 엔티티 추출
나는 과거에 본 일부 스키마에서 "컨텍스트"를 인식했습니다. "Knows about"이라는 용어를 사용하는 보류 중인 스키마 어휘가 있습니다. 여기에서 특정 직업에서 특정 유형의 경험이 있는 사람을 설명하는 데 사용할 수 있습니다. 이러한 컨텍스트 용어는 관련 정보를 제공하는 엔터티에 대한 추가 정보를 제공하는 데 도움이 되기 때문에 유사합니다. 특허의 컨텍스트 데이터베이스에 대한 구절은 이를 잘 설명합니다.
일부 실시예에서, 컨텍스트 데이터베이스는 하나 이상의 컨텍스트와 연관된 정보를 저장, 관련, 관리 및/또는 제공할 수 있습니다. 컨텍스트는 근접한 하나 이상의 단어(예: 개체)에 의미를 부여하는 하나 이상의 단어(예: 단어, 구, 절, 문장, 단락 등)의 어휘 구성 또는 표현을 반영할 수 있습니다. 특정 실시양태에서, 컨텍스트는 n-그램에 있다. n-그램은 n 단어의 시퀀스를 반영할 수 있으며, 여기서 n은 양의 정수입니다. 예를 들어, 컨텍스트는 "is", "was" 또는 "concurreBesidestion"과 같은 1-그램을 포함할 수 있고, 예시적인 컨텍스트는 "~에 태어났다", "결혼했다", "와 같은 3-그램을 포함할 수 있습니다. 2루를 훔쳤습니다." 또는 "반대를 작성했습니다." 컨텍스트(및 n-그램)에는 2-그램 "from . . . 까지 . . . .” 본 명세서에 기술된 바와 같이, n-그램은 임의의 그러한 시퀀스를 나타낼 수 있고, 2개의 n-그램은 단어의 이름 번호를 나타낼 필요는 없다. 예를 들어, "골을 넣었다"와 "최종 1분에"는 모두 다른 수의 단어를 포함함에도 불구하고 n-그램을 구성할 수 있습니다.
엔티티와 컨텍스트에 대해 배우는 것은 의미 있는 어휘를 배우는 문제입니다. 그렇게 하면 이 특허 이면의 프로세스가 작동하는 방식과 Google이 데이터 마이닝에 참여하여 엔티티, 해당 속성, 컨텍스트는 엔터티에 컨텍스트를 제공하는 데 도움이 되는 짧은 n-gram보다 더 복잡합니다. 이 특허의 다음 섹션에서는 컨텍스트 클래스와 컨텍스트 엔티티에 대해 설명합니다.
특정 실시예에서, 컨텍스트는 하나 이상의 엔티티의 잠재적인 존재를 나타낼 수 있습니다. 컨텍스트에 의해 지정된 하나 이상의 잠재적 엔티티는 본 명세서에서 "컨텍스트 클래스" 또는 "컨텍스트 엔티티"로 지칭될 수 있다. 그러나, 이러한 명칭은 제한하려는 의도가 아니므로 단지 예시적인 목적을 위한 것입니다. 컨텍스트 클래스는 일반적으로 컨텍스트와 관련하여 발생하는(예를 들어, 어휘적 관계를 갖는) 클래스 세트를 반영할 수 있습니다. 일부 측면에서 "컨텍스트 클래스"는 특정 엔티티 클래스를 반영할 수 있습니다. 예를 들어, 컨텍스트 "결혼했다"는 엔티티 "사람"의 컨텍스트 클래스와 연관될 수 있습니다. 왜냐하면 "~와 결혼했습니다" 컨텍스트는 일반적으로 인간과 어휘 관계를 갖기 때문입니다(예: 인스턴스에 대한 어휘 관계가 있습니다. "사람" 클래스). 예를 들어 이 예에서 "Jack은 Jill과 결혼했습니다"라는 문장은 "Jack"과 "Jill"이 둘 다 "person" 클래스에 속한다는 것을 나타냅니다. "결혼했다." 다른 예에서, 컨텍스트 "애완동물이 있다"는 "동물", "고양이," "개", "가축 동물" 등과 같은 컨텍스트 클래스와 연관될 수 있다. 더욱이, 이 대안적인 예에서 컨텍스트 "has a pet"은 같은 클래스의 두 인스턴스가 일반적으로 어휘 관계(예: 애완동물-마스터 속성 관계)를 공유하지 않기 때문에 같은 공간에 있지 않은 엔터티 클래스의 존재를 나타낼 수 있습니다. . 컨텍스트 클래스의 해석 및 생성은 아래에서 더 자세히 설명합니다.
엔티티 추출과 관련된 연관 점수
이 특허는 컨텍스트 클래스와 컨텍스트 엔터티에 대해 더 자세히 설명하고 있으며 더 자세히 살펴볼 가치가 있습니다. 그러나 배울 가치가 있는 것으로 보이는 특허 섹션은 엔터티 추출 중 연관 점수 계산을 참조하는 것과 관련되어 있습니다.
일부 양상에서, 엔티티 데이터베이스 및/또는 컨텍스트 데이터베이스는 또한 하나 이상의 연관 점수에 관한 정보를 저장할 수 있습니다. 연관 점수는 속성, 속성 값, 관계, 클래스 계층, 지정된 컨텍스트 클래스 또는 기타 연관이 유효하고 정확하며/또는 적법하다는 가능성 또는 신뢰도를 반영할 수 있습니다. 예를 들어, 일부 실시예에서, 연관 점수는 2개의 엔티티 또는 컨텍스트와 엔티티 사이의 관련성의 정도를 반영할 수 있다. 연관 점수는 개시된 실시예와 일치하는 임의의 프로세스를 통해 결정될 수 있다. 예를 들어, 아래에서 더 자세히 설명되는 바와 같이, 컴퓨팅 시스템(예: 서버)은 연관 점수가 생성되는 소스의 신뢰도, 콘텐츠의 두 개체(예: 전체 발생의 함수로서, 하나 또는 두 개체 모두를 포함하는 문서의 총 수 등), 개체 자체의 속성(예: 개체가 다른 개체의 하위 클래스인지 여부), 최신성 발견된 관계의 비율(예: 더 최근 또는 더 오래된 연관에 더 많은 가중치 부여), 속성이 알려진 변동 경향(예: 주기적으로 또는 산발적으로)을 가지고 있는지 여부, 엔티티 클래스 간의 상대적 인스턴스 수, 다음과 같은 엔티티의 인기도 쌍, 분석된 문서의 두 엔티티 사이의 평균, 중앙값, 통계적 및/또는 가중 근접성, 및/또는 여기에 공개된 임의의 다른 프로세스. 일부 양상에서, 시스템은 자체적으로 하나 이상의 연관 점수를 생성할 수 있습니다. 특정 양상에서, 시스템은 미리 생성된 데이터 구조(예를 들어, 데이터베이스(140 및/또는 150)에 저장됨)에 기초하여 하나 이상의 연관 점수를 미리 로드할 수 있습니다.
흥미롭게도 출처의 신뢰성과 같은 것들이 엔터티 또는 컨텍스트와 엔터티 간의 관계에 할당된 연관 점수에서 역할을 할 수 있습니다. 다음 섹션에서는 "컨텍스트와 엔터티 간의 동시 발생 비율"이라고 부르는 것을 살펴봅니다.
일 실시예에서, 예를 들어, 컴퓨팅 시스템(예를 들어, 서버)은 컨텍스트와 엔티티(예를 들어, 특정 엔티티, 엔티티 클래스 등) 네트워크 문서 전반에 걸쳐 해당 컨텍스트 및/또는 엔티티의 모든 발생에 적용됩니다. 예를 들어, 하나의 예시적인 표현은 A=P(E, C)/P(C) 형식을 취할 수 있습니다. 여기서 A는 엔티티와 컨텍스트 간의 예시적인 연관 값이고, P(C)는 컨텍스트를 찾을 확률입니다. 텍스트 섹션(예: 문서, 하나 이상의 웹 페이지, 말뭉치 등)에서 P(E, C)는 해당 섹션에서 두 컨텍스트 엔터티가 동시에 발생할 확률입니다. 이 예에서 연관 점수는 컨텍스트 C가 나타날 때 엔티티 E를 찾을 조건부 확률을 반영할 수 있다. 연관 점수에 대한 또 다른 예시적인 표현은 A=N(E, C)/(N(E)+N(C)-N(E, C))의 형태를 취할 수 있으며, 여기서 N(E)는 인스턴스의 수입니다. 엔티티가 섹션(예: 말뭉치)에 나타나는 경우, N(C)는 컨텍스트가 섹션에 나타나는 인스턴스의 수이고 N(E, C)는 엔티티 E와 컨텍스트 C가 함께 나타나는 인스턴스의 수입니다. 섹션에서. 유사한 표현을 사용하여 두 엔터티 간의 연관 점수를 생성할 수 있습니다.

특정 엔터티 클래스 및 컨텍스트의 이 예는 연관 점수가 그러한 점수가 어떻게 유용할 수 있는지 이해하는 데 어떻게 도움이 될 수 있는지 명확하게 합니다.
예를 들어, 서버는 컨텍스트가 분석된 모든 문서에 나타나는 시간의 35% 및 97%에서 "농구 선수" 및 "사람" 엔티티 클래스의 인스턴스와 "통과를 수신함" 컨텍스트가 동시에 발생한다고 결정할 수 있습니다. 각기. 시스템은 엔티티 간의 관계를 결정하기 위해 엔티티 및 컨텍스트 모델을 적어도 부분적으로 사용하여 이러한 동시 발생 빈도를 결정할 수 있습니다(예: "LeBron James"가 "농구 선수" 클래스의 인스턴스임을 결정함). 이 예에서, 서버는 컨텍스트 "receives from" to "basketball player" 및 "person"과 관련된 연관 점수가 각각 0.35 및 0.97인 것으로 결정할 수 있다.
이러한 동시 발생은 하나가 아닌 문서 모음에서 발생합니다.
연관 점수 계산에 영향을 줄 수 있는 다른 요소의 몇 가지 다른 예가 있습니다.
연관 점수는 엔터티 또는 컨텍스트의 각 발생에 대해 하나 이상의 가중치를 통합하여 다른 고려 사항을 설명할 수 있습니다. 일부 양상들에서, 컴퓨팅 시스템은 시간적 가중치(예를 들어, 최근 문서 또는 발생에 더 무겁게 가중하기 위해), 신뢰성 가중치(예를 들어, 더 신뢰할 수 있는 소스에 더 무겁게 가중하기 위해), 인기도 가중치(예를 들어, 더 많이 사용되는 소스를 더 무겁게 가중하기 위해), 근접성 가중함(예를 들어, 서로 더 가깝게 근접하여 발생하는 엔티티/컨텍스트에 더 무겁게 가중함) 및 개시된 실시예와 일치하는 임의의 다른 유형의 웨이트. 특정 양상들에서, 가중치는 다른 것들에 비해 특정 문서 또는 개별 발생의 상대적 중요성(예를 들어, 모든 발생에 대한 가중치의 합은 1.0임), 절대 척도(예를 들어, 각 가중치 독립 등급을 반영함), 또는 두 엔터티 또는 컨텍스트 간의 관련성을 나타내는 기타 측정값(예: 컨텍스트와 엔터티 간의 근접성).
낮은 연관성 점수는 무엇을 의미합니까?
따라서, 일부 실시예에서, 낮은 연관 점수는 관계의 기반이 되는 데이터 소스가 일반적으로 신뢰할 수 없거나 신뢰할 수 없음을 나타낼 수 있습니다. 다른 실시예에서, 낮은 연관 점수는 주제 쌍의 동시 발생이 최근 문서에서 발생하지 않음을 표시할 수 있습니다. 또 다른 실시예에서, 낮은 연관성 점수는 쌍 사이의 동시 발생이 드물다는 것을 나타낼 수 있다(예를 들어, 소수의 "정치인"이 "프로 농구 선수"임). 또 다른 실시예에서, 연관 스코어는 많은 그러한 인자의 조합을 반영할 수 있다. 일부 양상들에서, 시스템(예를 들어, 서버 또는 데이터베이스와 관련된 컴퓨팅 시스템)은 (예를 들어, 새로운 문서, 컨텍스트, 및 속성에 기초하여) 시간이 지남에 따라 연관 점수를 업데이트 및 수정할 수 있습니다.
연관 점수는 가능성에 대한 아이디어를 제공합니다.
연관 점수는 숫자(예: 0.0 ~ 1.0, 0 ~ 100 등), 정성적 척도(예: 있을 것 같지 않음, 가능성 있음, 매우 가능성 있음), 색상으로 구분된 척도 및/또는 학위 수준을 지정할 수 있는 기타 측정 또는 등급 체계. 예를 들어, 일 실시예에서, 엔티티 데이터베이스는 엔티티 "Bryce Harper"가 값 "Oct. 1992년 1월 16일.” 이것은 예를 들어 시스템이 Bryce Harper의 생년월일을 84% 정확도로 1992년 10월 16일로 간주함을 나타낼 수 있습니다. 또한 "Bryce Harper"는 속성 또는 관계 "is a"를 통해 엔티티 클래스 "person"과 연관될 수 있으며, 이는 Bryce Harper가 사람이라는 확실성을 나타내는 연관 점수가 1.0입니다. 다른 예에서, 컨텍스트 "골을 넣었다"는 컨텍스트 클래스 "축구 선수", "하키 선수" 및 "사람"과 연관 점수가 각각 0.64, 0.49 및 0.98인 컨텍스트와 연관될 수 있습니다. 이러한 예시적인 값은, 예를 들어 컨텍스트가 하키 선수보다 축구 선수에 관한 것일 가능성이 더 높고, 문장이 특히 축구 선수보다 일반적으로 한 명 이상의 사람에 관한 것일 가능성이 더 높다는 것을 나타낼 수 있습니다. 위에서 나타낸 바와 같이, 하나 이상의 엔티티 데이터베이스(예를 들어, 엔티티 데이터베이스) 및 컨텍스트 데이터베이스(예를 들어, 컨텍스트 데이터베이스), 서버 및/또는 클라이언트 장치는 엔티티, 속성, 컨텍스트, 컨텍스트 클래스, 연관 스코어, 및 개시된 실시예와 일치하는 임의의 형태의 임의의 다른 정보.
항목 추출 중 연관 점수가 있는 지식 그래프
이 특허는 엔티티를 속성 또는 값에 연결하는 각 에지에 포함된 연관 점수가 있는 예시 지식 그래프를 설명합니다.
일부 양상들에서, 지식 그래프는 복수의 노드들을 포함할 수 있고, 각각의 노드는 엔티티를 반영한다. 지식 그래프는 엔티티와 특정 속성 값 간의 관계를 설명하는 속성을 반영하는 하나 이상의 에지를 포함할 수도 있습니다. 특정 실시예에서, 지식 그래프는 그 안에 포함된 각각의 에지에 대한 연관 점수(예를 들어, 각각의 속성 또는 연관된 값)를 또한 포함할 수 있지만, 그러한 연관 점수는 요구되지 않는다. 도 1에 도시된 예시적인 지식 그래프에서. 예를 들어, 2A에서 특정 엔티티를 반영하는 엔티티 노드 "Bryce Harper"는 연관 점수가 0.96인 오브젝트 속성 "plays for"를 통해 다른 엔티티 "Washington Nationals"에 연결됩니다. 이러한 값과 관계는 예를 들어 Bryce Harper가 Washington Nationals의 선수이고 시스템이 이 속성을 0.96의 신뢰도와 연관시킨다는 것을 나타낼 수 있습니다. 엔티티 "워싱턴 내셔널" 자체는 노드에서 나오는 해시 라인으로 표시된 표시되지 않은 다른 엔티티와 연관될 수 있습니다. 다른 엔티티는 도 1 및 도 2에 도시되어 있다. 도 2a 내지 도 2c 및 도 3은 도시되지 않은 다른 노드 및 속성과 유사하게 연관될 수 있고, 그 안의 특정 관계 및 값의 묘사는 단지 예시적이다.
연관 점수는 엔터티와 관련된 사실의 정확성에 대한 확신을 제공할 수 있습니다. Bryce Harper와 관련된 또 다른 예:
무화과. 도 2a는 또한 노드 "Bryce Harper"를 날짜 엔티티 노드 "Oct. 1992년 16월 16일" 및 "생일 있음" 및 "경력 HR 합계 있음" 속성을 통해 각각 값 엔터티 노드 "60 홈런". 이러한 속성은 각각 0.84 및 0.37의 연관 점수를 가지며, 이는 시스템이 "경력 HR 합계 있음"과 연관된 값보다 "생년월일 있음" 속성 관계와 연관된 값에 더 확신이 있음을 나타냅니다. 이러한 연관 점수의 차이는 예를 들어 이러한 관계를 생성하는 데 사용된 소스의 신뢰성, 엔티티 간의 동시 발생 빈도, 속성(노드 204) 값 중 하나가 다음과 같다는 사실로 인해 발생할 수 있습니다. 개시된 실시예와 일치하는, 시간 및/또는 다른 요인에 따라 변화한다.
각각 많은 속성이나 속성이 연결된 다양한 유형과 엔터티와 클래스 및 하위 클래스 간의 신뢰 수준을 제공하는 연관 점수를 포함하는 거대한 지식 그래프를 이미지화하십시오. 이 특허는 다음과 같은 가능성이 있음을 보여줍니다.
엔터티 노드는 엔터티와 엔터티 클래스 간의 관계 특성을 설명하는 속성을 통해 연결된 엔터티 클래스 및 하위 클래스와도 연결될 수 있습니다. 예를 들어, 도. 도 2a는 노드 "Bryce Harper"와 엔티티 클래스 "사람" 및 "프로 야구 선수" 사이의 연결을 각각의 에지 "이다" 및 "직업을 갖는다"를 통해 도시한다. 이러한 속성의 연관 점수는 각각 1.0 및 0.99입니다. 예시적인 속성과 연관 점수는 시스템이 Bryce Harper를 직업이 확실하거나 거의 확실한 프로 야구 선수인 사람으로 간주함을 나타냅니다.
또한 엔티티 클래스 및 기타 엔티티 클래스에 대한 낮은 연관 점수에서 학습합니다.
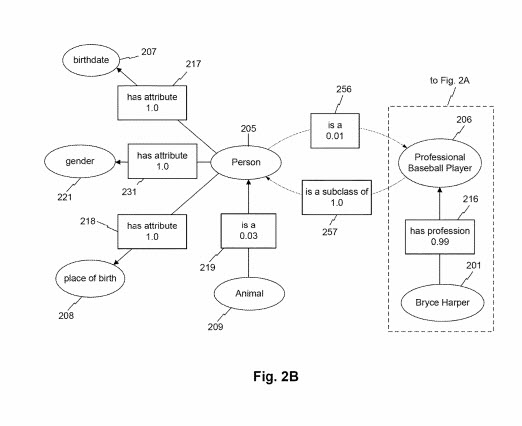
도 4에 도시된 바와 같이. 도 2b에 도시된 바와 같이, 엔티티 클래스는 또한 엔티티 속성을 통해 다른 엔티티 클래스와 연관될 수 있다. 예를 들어, "animal" 클래스는 "is a" 속성을 통해 "person" 클래스와 연관될 수 있습니다. 이 예에서 속성에 해당하는 연관 점수는 0.03입니다. 이것은 예를 들어 "동물" 클래스 209의 인스턴스가 "사람" 클래스의 드문 인스턴스임을 나타낼 수 있습니다(예: 다른 포유동물, 곤충, 새, 물고기 등과 같은 비인간 동물의 만연으로 인해). 도 1에 도시되지는 않았지만. 도 2b에 도시된 바와 같이, 클래스 "사람"은 "동물" 노드와 관련하여 상호 속성 "이다" 또는 "~의 서브클래스이다" 등과 연관될 수 있다. 그러한 속성은 "사람" 클래스가 "동물"의 하위 클래스임을 나타내는 더 높은 연관 점수(예를 들어, 0.94)와 연관될 수 있습니다. 예를 들어, 도. 도 2b는 연관 점수가 1.0인 엔티티 속성 "is a subclass"를 갖는 클래스 "person"과 연관시키는 클래스 "프로 야구 선수"를 도시한다. 대조적으로, 클래스 노드 "person"은 0.01의 연관 점수를 갖는 "is a" 속성을 통해 "프로 야구 선수" 노드와 연관될 수 있습니다. 이 낮은 연관성 점수는 예를 들어 "프로 야구 선수" 클래스가 아닌 클래스 "사람"의 엔터티의 강한 보급을 반영할 수 있습니다(예: 대부분의 사람들은 프로 야구 선수가 아닙니다). 무화과. 도 2b는 도 1과 관련하여 논의된 바와 같이, 프로 야구 선수 클래스 노드가 "직업을 가짐" 속성을 통해 엔티티 노드 "Bryce Harper"와 연관시킬 수 있는 방법을 추가로 도시한다. 2A.
컨텍스트 그래프에서 엔티티 유형과 컨텍스트 클래스 간의 연관은 이러한 엔티티 유형 및 컨텍스트에 대한 특정 정보를 알려줄 수 있습니다.
일부 실시예에서, 컨텍스트 그래프에 포함된 엔티티 클래스는 특정 컨텍스트(예를 들어, 컨텍스트)와 연관된 컨텍스트 클래스를 나타낼 수 있다. 이러한 실시예에서, 컨텍스트를 컨텍스트 클래스(및 임의의 포함된 서브클래스 등)에 연결하는 연관 점수는 컨텍스트 클래스와 컨텍스트(예: 에지) 사이의 유효성 또는 관련성의 정도 및/또는 관련성의 정도를 반영할 수 있습니다. 엔티티 클래스 자체 사이(예: edge). 일부 양상들에서, 연관 스코어는 따라서 컨텍스트가 연관된 컨텍스트 클래스의 존재 또는 해당 컨텍스트 클래스의 인스턴스를 신호할 가능성을 반영할 수 있다. 예를 들어, 도 2에 도시된 바와 같이. 도 2d에 도시된 바와 같이, 컨텍스트 노드 "통과를 수신(들)"은 5개의 컨텍스트 클래스와 연관될 수 있다. 이 예에서 컨텍스트 "receive(s) a pass from"은 컨텍스트 클래스 "사람", "야구 선수", "농구 선수", "하키 선수" 및 "축구 선수"와 연관됩니다. 이러한 연관 각각은 다음을 포함할 수 있습니다. 점수와 같은 해당 연관 점수. 이러한 연관 점수는 컨텍스트가 특정 클래스 또는 클래스 인스턴스의 존재를 나타낼 가능성 또는 확률을 나타내기 위해 "take class"라는 문구와 함께 설명됩니다.
예를 들어, "야구 선수" 클래스의 구성원이 다른 선수로부터 "패스를 수신"(컨텍스트)하는 경우는 드물기 때문에 이 컨텍스트 클래스와 연결된 연관 점수는 라인 항목에 표시된 것처럼 0.02입니다. . 위에서 설명한 바와 같이 이 값은 네트워크 소스를 통해 컨텍스트와 "야구 선수" 클래스의 인스턴스 간의 동시 발생 빈도, 해당 소스의 신뢰성 등에서 생성될 수 있습니다. 대조적으로 컨텍스트와 컨텍스트 간의 연관 점수는 나머지 엔터티 클래스는 상대적으로 높습니다. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019