
Google'da Bilgi Grafikleri için Varlık Çıkarma
Yayınlanan: 2019-02-15<
Google, Bilgi Grafikleri Oluşturmak için Sayfalardan varlık ayıklamaları, varlık sınıfları, varlık özellikleri ve İlişkilendirme Puanlarını kullanabilir
Google, 2012'de Bilgi Grafiği'ni tanıttığında, bize dizelere değil şeylere odaklanmaya ve gerçek dünyadaki nesneleri dizine eklemeye başlayacağını söyledi. Bu süreç olgunlaşıyor ve Google'ın, sayfalar ve bağlantılar gibi web bilgilerini araştırmak yerine veri madenciliği yapmak ve varlık çıkarımlarına katılmak için Web'i nasıl taramaya başlayacağını öğrenmesini izleme şansımız var. Geçenlerde Twitter'da bununla ilgili yazdığım gibi:
Web taramasında düğüm bir sayfadır ve kenar sayfalar arasındaki bir bağlantıdır; veri taramada, bir düğüm bir varlıktır ve bir uç, varlıklar arasındaki bir ilişkidir. Web hakkında düşünmede bir evrim.
— Bill Slawski (@bill_slawski) 10 Şubat 2019
Yakın zamanda verilen bir Google patenti, arama motorunun web sayfalarından varlık çıkarma işlemlerini nasıl gerçekleştirebileceğini ve bunlar hakkında bilgi depolayabileceğini bize anlatır. Bu, bilgi tabanlarını varlıklar hakkında bilgi kaynakları olarak kullanmanın ötesine geçer ve web sayfalarındaki metinsel pasajlara bakarak bu tür kaynaklarda mevcut olabileceklerden daha fazlasını bulmaya devam eder. Bu muhtemelen Wikipedia gibi geçmişte sahip olduğumuzdan daha fazla kaynaktan bilgi sonuçları göreceğimiz anlamına geliyor. Bu patentin, patentten bu erken satırda çözdüğü sorun:
Geleneksel bilgi tabanları, ancak varlıklar ve kullanıcılar tarafından istenen diğer bilgiler hakkında güncel veya güvenilir bilgiler sağlayamayabilir.
Google'ın Wikipedia ve IMDB gibi yerlerde tablolardan ve iki nokta üst üste ayrılmış listelerden varlık çıkardığını gördük. Ya bu bilgiyi Web sayfalarında bulabilirlerse ve bu sayfalardan varlıkları çıkarabilirlerse ve web sayfalarını tararken bu varlıklarla ilgili özellikleri ve öznitelikleri toplayabilirlerse. Bu varlıklar hakkındaki bilgilerin güven düzeylerini ve bunların doğruluğunu ölçmenin yolları da olabilir.

Patentten alınan bu resimlerde gösterildiği gibi, Google, varlıklar ve bağlantılı nitelikler arasındaki ilişki puanlarını hesaplar (aşağıdaki ilişkilendirme puanları hakkında daha fazla bilgi).
Şu gönderide benzer bir şey hakkında yazmıştım: Google'ın Bilgi Grafiği Soruları Yanıtlayarak Kendini Nasıl Günceller? Bu gönderinin odak noktası, web sayfalarındaki varlıklar hakkında bilgi bulmak ve onları tanımak ve diğer varlık sınıflarıyla nasıl birleşebilecekleri hakkında bilgi bulmak yerine Google'ın mevcut bilgi grafiklerini nasıl güncelleyebileceğiydi. Web'i büyük bir veri tabanı olarak ele almak yerine bilgi tabanlarına güvenmek kısmi bir adım gibi görünüyor. Varlık çıkarımlarını akıllı ve kullanışlı bir şekilde yapmak mümkün olsaydı, Web'de insan tarafından yönetilen bir ansiklopediye bağlı olarak gerekli olmazdı. Geçmişte birkaç yerde Google, web'deki bilgileri düzenlemek için web ölçeklenebilir yaklaşımları tercih ettiklerini söylemişti (örneğin, insanlar tarafından sağlanan bir kaynaktan gelen Google Dizini'ni bıraktıklarında olduğu gibi).
Bu yeni patent, Google'ın yeni Web sayfaları ve haber kaynakları da dahil olmak üzere Web'de bir bilgi tabanına eklemek yerine Web'e eklenen kaynaklardan varlık çıkarmaları ve bu varlıklar hakkında diğer bilgileri gerçekleştirmesine yardımcı olan farklı bir yaklaşımı açıklamaktadır.
Patentin açıklamasında, koruduğu süreç hakkında bize bilgi verdiği bir özet bölümü vardır. Bunları birkaç kelimeyle şöyle özetliyor:
Açıklanan düzenlemeler, yeni varlıkların sınıflarını ve niteliklerini belirlemeye yönelik sistemler ve yöntemlerin yanı sıra, ilgililik derecelerini ve belirlenen ilişkilerde güven düzeylerini yansıtan ilişki puanları sağlayabilir. Açıklanan düzenlemeler, yeni varlıkların göründüğü ve bilinen varlıkların her yeni varlığa yakın olduğu çevreleyen sözlüksel bağlamlara dayalı olarak bu sınıfları, nitelikleri ve ilgili puanları belirleyebilir. Açıklanan düzenlemelerin yönleri, aynı zamanda , gerçek zamanlı veya gerçek zamanlıya yakın olarak belirlenen ilişkileri dinamik olarak güncellemek ve depolamak için sistemler ve yöntemler sağlar.
Bize "Varlık Adaylarının Belirlenmesi" olarak atıfta bulunduğu bir sürece adım adım bir bakış vererek, bunları biraz daha ayrıntılı olarak genişletiyor.
Varlık Çıkarımları için Kurum Adaylarının Belirlenmesi
- Bir varlık adayı, bir ağ üzerinden erişilebilen bir belgededir.
- Tespit edilen varlık adayı, bir veritabanında depolanan bir veya daha fazla varlık modeline dayalı yeni bir varlıktır.
- Bilinen bir varlık yeni varlığın yanındadır ve bilinen varlık bir veya daha fazla varlık modelindedir.
- Yeni varlığın ve bilinen varlığın yanındaki bağlam, bilinen varlıkla sözcüksel bir ilişkiye sahiptir.
- Bilinen varlıkla ilişkilendirilen ikinci bir varlık sınıfı ve bir bağlam sınıfı da bağlamla ilişkilendirilir.
- Birinci varlık sınıfı, ikinci varlık sınıfına ve bağlam sınıfına dayalı olarak yeni varlıkla bağlantı kurar.
- Veritabanındaki ilk giriş, varlık modellerinden en az birine bağlıdır; giriş, birinci varlık sınıfı ile yeni varlık arasındaki ilişkiyi yansıtır.
Bu tüzel kişilik Adaylarının sahip olduğu patent, varlık çıkarma ve bu varlıklar hakkında bilgi depolama ile ilgili olandır:
Varlıklarla ilgili bilgileri çıkarmak ve depolamak için bilgisayarlı sistemler ve yöntemler
Mucitler: Christopher Semturs, Lode Vandevenne, Danila Sinopalnikov, Alexander Lyashuk, Sebastian Steiger, Henrik Grimm, Nathanael Martin Scharli ve David Lecomte
Atanan: GOOGLE LLC
ABD Patenti: 10,198.491
Verildi: 5 Şubat 2019
Dosyalanma: 6 Temmuz 2015
Soyut
Web sayfaları gibi belgelerden varlıklarla ilgili bilgileri çıkarmak ve depolamak için bilgisayarla uygulanan sistemler ve yöntemler sağlanır. Bir uygulamada, bir belgedeki varlık adayını tespit eden ve tespit edilen adayın yeni bir varlık olduğunu belirleyen bir sistem sağlanır. Sistem ayrıca bir veya daha fazla varlık modeline dayalı olarak bilinen varlığa yakın bilinen bir varlığı da tespit eder. Sistem ayrıca, bilinen varlıkla sözcüksel bir ilişkisi olan yeni ve bilinen varlıklara yakın bir bağlamı da algılar. Sistem ayrıca, bilinen varlıkla bağlantılı ikinci bir varlık sınıfını ve bağlamla bağlantılı bir bağlam sınıfını da belirler. Sistem ayrıca ikinci varlık sınıfına ve bağlam sınıfına dayalı olarak bir birinci varlık sınıfı oluşturur. Sistem ayrıca, yeni ve ilk varlıklar arasındaki ilişkiyi yansıtan bir veya daha fazla varlık modelinde bir girdi oluşturur.
Varlık Çıkarmaları – Varlıklar, Varlık Sınıfları, Varlık Örnekleri ve Varlık Nitelikleri
Bu patentte yer alan süreçteki ilk adımlardan biri, varlıkların tanınmasını içerir. Patent, varlıkların ne olduğu hakkında bazı bilgiler sağlar ve bize birkaç örnek verir:
Belirli yönlerden bir varlık, bir kişiyi (örneğin George Washington), yeri (örneğin, San Francisco, Wyoming, belirli bir cadde veya kavşak, vb.) veya bir şeyi (örneğin, yıldız, araba, politikacı, doktor, cihaz) yansıtabilir. , stadyum, kişi, kitap). Daha fazla örnek vermek gerekirse, bir kuruluş bir literatürü, bir kuruluşu (örneğin, New York Yankees), bir siyasi organı veya partiyi, bir işletmeyi, bir egemen veya devlet kurumunu (örneğin, Amerika Birleşik Devletleri, NATO, FDA) yansıtabilir. , vb.), bir tarih (ör. 4 Temmuz 1776), bir sayı (ör. 60, 3.14159, e), bir harf, bir durum, bir nitelik, bir fikir, bir kavram veya bunların herhangi bir kombinasyonu.
Bir varlığın bu tanımlarına ek olarak, varlık sınıfları ve alt sınıfları ve varlıkların farklı sınıflara ve alt sınıflara nasıl sığabileceği hakkında da bilgi verilir. Bu önemlidir çünkü arama motoru varlıkları öğrendikçe farklı sınıflara sığdırmaya çalışacaktır.
Peki bir varlık sınıfı veya alt sınıfı nedir?
Patent bunları derinlemesine açıklar:
Bazı yönlerden bir varlık, bir varlık sınıfıyla ilişkilendirilebilir. Bir varlık sınıfı, bir grup veya kavramsal varlık modelinin kategorizasyonunu, türünü veya sınıflandırmasını temsil edebilir. Örnekleme amacıyla, örneğin varlık sınıfları "kişi", "galaksi", "beyzbol oyuncusu", "ağaç", "yol", "politikacı" vb. içerebilir. Bir varlık sınıfı bir veya daha fazla alt sınıfla ilişkilendirilebilir. . Bazı yönlerden, bir alt sınıf, daha büyük bir sınıfa dahil edilen bir varlık sınıfını yansıtabilir (örneğin, bir "üst sınıf"). Örneğin, yukarıdaki örnek sınıf listesinde, "beyzbolcu" ve "politikacı" sınıfları, "kişi" sınıfının alt sınıfları olabilir, çünkü tüm beyzbol oyuncuları ve politikacılar insandır. Diğer düzenlemelerde, alt sınıflar, daha büyük bir üst sınıfın neredeyse tamamen, ancak tamamen olmayan bir parçası olan varlık sınıflarını temsil edebilir. Bu tür bir düzenleme, aykırı değerler veya kurgusal varlıklar içeren durumlarda ortaya çıkabilir. Örneğin, "politikacı" sınıfı, bazı hayali varlıklar insan olmayan politikacılar olsa bile (örneğin, "Mas Amedda") "kişi" sınıfının bir alt sınıfı olabilir. Açıklanan düzenlemeler, aşağıda daha ayrıntılı olarak açıklandığı gibi bu tür ilişkilerin ele alınması ve yönetilmesi için yollar sağlar. Hem sınıflar hem de alt sınıf, varlık sınıflarını temsil edebilir ve varlıkları kendileri oluşturabilir.
Veri örneği, bir sınıfa veya alt sınıfa uyan belirli bir varlığın örneğidir. Thomas Jefferson, bir "ABD Başkanı" örneğidir ve "Mike Trout", "profesyonel Beyzbol Oyuncusu"nun özel bir örneğidir.
Patent, varlıklar hakkında bilgi toplamaya çalışır ve "Varlık Nitelikleri" olarak adlandırdığı varlıklar hakkında bilgi toplar. Patentten alınan bu çizimde olduğu gibi:

Bunlar, varlıkların özelliklerini ve ayrıca varlık sınıfları arasındaki ilişkileri içerebilir. Patent, bir özelliğin de ne olabileceğine dair derinlemesine bir bakış sağlar:
Varlıklar, bir veya daha fazla varlık niteliği ve/veya nesne niteliği ile ilişkilendirilebilir. Bir varlık niteliği, bazı yönlerden bir varlık sınıfının bir özelliğini, niteliğini, niteliğini, niteliğini veya öğesini yansıtabilir. Bazı yönlerden, bir varlık sınıfının her veya büyük ölçüde her örneği, ortak bir varlık nitelikleri kümesini paylaşacaktır. Örneğin, "kişi" varlığı, diğerleri arasında "doğum tarihi", "doğum yeri", "ebeveynler", "cinsiyet" veya genel olarak "özniteliği vardır" varlık nitelikleriyle ilişkilendirilebilir. Başka bir örnekte, bir varlık "profesyonel spor takımı", "yer", "yıllık gelir", "kadro" gibi varlık özellikleriyle ilişkilendirilebilir. Diğer düzenlemelerde, bir varlık özelliği, bir varlığın başka bir varlıkla nasıl ilişkili olduğunu açıklayabilir. Örneğin, varlık öznitelikleri, "bir", "bir alt sınıfıdır" veya "bir üst sınıfıdır" veya "içerir" gibi varlık sınıfları arasındaki ilişkileri tanımlayabilir. Örneğin, "yıldız" sınıfı, "gök nesnesi" varlık sınıfı ile "bir alt sınıfıdır" varlık özniteliği ile ilişkilendirilebilir.
Varlık çıkarma söz konusu olduğunda, bize belirli varlıklar hakkında daha fazla bilgi vermek için kullanılan anahtar/değer çiftlerini görüyoruz:
Belirli yönlerden, bir nesne özniteliği, belirli bir öznitelik değerine sahip bir varlık sınıfı örneği arasındaki bir ilişkiyi yansıtabilir. Örneğin, "George Washington" varlığı, "Şubat. 22, 1732.” Bazı düzenlemelerde, bir nesne özniteliğinin değerinin kendisi bir varlığı yansıtabilir. Örneğin, yukarıdaki örnekte “Şubat. 22, 1732” bir varlığı yansıtabilir.
Varlıklar hakkında bilgi toplamaya yönelik bu yaklaşım, içinde var olan alt sınıflarda ortak olabilecek özellikleri içerir:
Bazı düzenlemelerde, varlıklar ve alt sınıflar, öznitelikleri türettikleri üst sınıflardan devralır. Örneğin, "ABD Başkanı" sınıfı, "kişi" üst sınıfından "doğum tarihi" niteliğini devralabilir. Ayrıca, belirli düzenlemelerde üst sınıflar, alt sınıflarının niteliklerini zorunlu olarak devralmayabilir. Örnek olarak, "kişi" sınıfı, "profesyonel beyzbol oyuncusu" alt sınıfından "çalıntı üsler" niteliğini veya "ABD Başkanı" alt sınıfından "varsayılan görev tarihi" niteliğini almak zorunda olmayabilir.
Bağlam veritabanları ve Varlık Çıkarmaları
Geçmişte gördüğüm bazı şemalardan “Bağlamları” tanıdım. Belirli bir meslekte faaliyet gösteren bir kişiyi belirli bir tür deneyime sahip olarak tanımlamak için kullanabileceğiniz “Hakkında bilir” terimini kullanan, beklemede olan bir Şema sözlüğü var. Bu bağlam terimleri benzerdir çünkü size onlar hakkında bilgi veren varlıklar hakkında daha fazla bilgi sağlamaya yardımcı olurlar. Patentten alınan bağlam veritabanları ile ilgili pasaj onları iyi tanımlıyor:
Bazı düzenlemelerde bağlam veri tabanı, bir veya daha fazla bağlamla ilişkili bilgileri depolayabilir, ilişkilendirebilir, yönetebilir ve/veya sağlayabilir. Bir bağlam, yakınındaki bir veya daha fazla kelimeye (örneğin bir varlık) anlam kazandıran bir veya daha fazla kelimenin (örneğin bir kelime, deyim, yan tümce, cümle, paragraf, vb.) sözlüksel bir yapısını veya temsilini yansıtabilir. Bazı düzenlemelerde, bir bağlam bir n-gram'dadır. Bir n-gram, n'nin pozitif bir tam sayı olduğu bir n sözcük dizisini yansıtabilir. Örneğin, bir bağlam "is", "oldu" veya "concurre" gibi 1 gram içerebilir. ikinci üssü çaldı” veya “bir muhalefet yazdı”. Bağlamlar (ve n-gramlar), 2 gramlık "'den" gibi herhangi bir uzunluktaki boşlukları da içerebilir. . . a kadar . . . ” Burada açıklandığı gibi, bir n-gram, bu tür herhangi bir diziyi temsil edebilir ve iki n-gramın, kelimelerin isim sayısını temsil etmesi gerekmez. Örneğin, "bir gol attı" ve "son dakikada", farklı sayıda kelime içermesine rağmen, n-gram'ı oluşturabilir.
Varlıklar ve bağlamlar hakkında bilgi edinmek, anlamlı bir kelime dağarcığı öğrenme meselesidir çünkü bunu yapmak konu bu patentin arkasındaki sürecin nasıl işlediğini ve Google'ın varlıklar, onların nitelikleri, ve özellikler ve onları içinde gördüğümüz bağlamlar. Bağlamlar, bir varlığa bağlam sağlamaya yardımcı olan kısa bir n-gramdan daha karmaşıktır. Patentin bu sonraki bölümü bize bağlam sınıfları ve bağlam varlıkları hakkında bilgi verir:
Belirli düzenlemelerde, bir bağlam, bir veya daha fazla varlığın potansiyel varlığını gösterebilir. Bir bağlam tarafından belirtilen bir veya daha fazla potansiyel varlık, burada "bağlam sınıfları" veya "bağlam varlıkları" olarak adlandırılabilir. Bununla birlikte, bu tanımlamalar, sınırlayıcı olmaları amaçlanmadığından yalnızca açıklama amaçlıdır. Bağlam sınıfları, tipik olarak bağlamla bağlantılı olarak ortaya çıkan (örneğin, sözcüksel bir ilişkiye sahip olan) bir sınıflar kümesini yansıtabilir. Bazı açılardan, "bağlam sınıfları" belirli varlık sınıflarını yansıtabilir. Örnek olarak, "evli olduğu" bağlamı "kişi"nin bağlam sınıfıyla ilişkilendirilebilir, çünkü "evli olduğu" bağlamının genellikle insanlarla sözcüksel bir ilişkisi vardır (örneğin, örneklerle sözcüksel bir ilişkisi vardır). "kişi" sınıfından). Bu örnekte, örneğin, "Jack, Jill ile evlidir" cümlesi, en azından kısmen bağlamın bağlam sınıf(lar)ı nedeniyle hem "Jack" hem de "Jill"in "kişi" sınıfına ait olduğunu gösterir. “ile evlidir.” Başka bir örnekte, "evcil hayvanı var" bağlamı, "hayvan", "kedi, "köpek", "evcil hayvan" ve benzeri gibi bağlam sınıflarıyla ilişkilendirilebilir. Ayrıca, bu alternatif örnekte, "evcil hayvanı var" bağlamı, aynı sınıfın iki örneği tipik olarak sözcüksel bir ilişkiyi paylaşmadığından (örneğin, bir evcil hayvan-ana nitelik ilişkisi) birlikte kapsamlı olmayan varlık sınıflarının varlığına işaret edebilir. . Bağlam sınıflarının yorumlanması ve oluşturulması aşağıda daha ayrıntılı olarak açıklanmıştır.
Varlık Çıkarımlarını İçeren İlişkilendirme Puanları
Patent, bağlam sınıfları ve bağlam varlıkları hakkında daha fazla ayrıntıya giriyor ve bunlar daha ayrıntılı olarak incelenmeye değer. Ancak patentin öğrenmeye değer görünen bir bölümü, varlık çıkarımları sırasında ilişkilendirme puanlarının hesaplanmasına atıfta bulunan bir şey içeriyordu:
Bazı yönlerden, varlık veri tabanı ve/veya bağlam veri tabanı, bir veya daha fazla ilişki puanıyla ilgili bilgileri de depolayabilir. Bir ilişki puanı, bir öznitelik, öznitelik değeri, ilişki, sınıf hiyerarşisi, belirlenmiş bağlam sınıfı veya bu tür başka bir ilişkinin geçerli, doğru ve/veya meşru olduğuna dair bir olasılık veya güven derecesini yansıtabilir. Örneğin, bazı düzenlemelerde, bir ilişki puanı, iki varlık veya bir bağlam ve bir varlık arasındaki bir ilişki derecesini yansıtabilir. İlişkilendirme puanları, açıklanan düzenlemelerle tutarlı herhangi bir işlem yoluyla belirlenebilir. Örneğin, aşağıda daha ayrıntılı olarak açıklandığı gibi, bir bilgisayar sistemi (örneğin sunucu), ilişkilendirme puanının oluşturulduğu kaynakların güvenilirliği, aralarındaki birlikte oluşumların sıklığı veya sayısı gibi faktörleri ve ağırlıkları kullanarak ilişki puanlarını belirleyebilir. içerikteki iki varlık (örneğin, toplam oluşumların bir fonksiyonu olarak, bir veya her iki varlığı içeren belgelerin toplam sayısı, vb.), varlıkların kendilerinin nitelikleri (örneğin, bir varlığın diğerinin alt sınıfı olup olmadığı), güncellik keşfedilen ilişkilerin sayısı (örneğin, daha yeni veya daha eski çağrışımlara daha fazla ağırlık vererek), bir özniteliğin bilinen bir dalgalanma eğilimi olup olmadığı (örneğin, periyodik olarak veya ara sıra), varlık sınıfları arasındaki nispi örnek sayısı, varlıkların popülaritesi analiz edilen belgelerde ve/veya burada açıklanan diğer herhangi bir süreçte iki varlık arasındaki bir çift, ortalama, medyan, istatistiksel ve/veya ağırlıklı yakınlık. Bazı yönlerden, sistemin kendisi bir veya daha fazla ilişkilendirme puanı üretebilir. Belirli yönlerden sistem, önceden oluşturulmuş veri yapılarına (örneğin, veri tabanlarında 140 ve/veya 150'de depolanan) dayalı olarak bir veya daha fazla ilişkilendirme puanını önceden yükleyebilir.

İlginç bir şekilde, kaynakların güvenilirliği gibi şeyler, bir varlık veya bir bağlam ile bir varlık arasındaki ilişkiye atanan ilişkilendirme puanlarında rol oynayabilir. Bir sonraki bölüm, "bir bağlam ve bir varlık arasındaki birlikte oluşumların oranı" olarak adlandırdıkları şeye bakar:
Bir düzenlemede, örneğin, bir bilgisayar sistemi (örneğin sunucu), bağlam ve varlık (örneğin, belirli varlık, bir varlık sınıfı, vb.) bu bağlamın ve/veya varlığın ağ belgeleri genelindeki tüm oluşumlarına. Örneğin bir açıklayıcı ifade A=P(E, C)/P(C) şeklini alabilir; burada A, varlık ve bağlam arasındaki örnek bir ilişkilendirme değeridir, P(C) bağlamı bulma olasılığıdır. metnin bir bölümünde (örneğin, bir belge, bir veya daha fazla web sayfası, bir derlem, vb.) ve P(E, C) her iki bağlam öğesinin bölümde birlikte ortaya çıkma olasılığıdır. Bu örnekte, ilişki puanı, C bağlamı göründüğünde bir E varlığının bulunmasının koşullu olasılığını yansıtabilir. Bir ilişkilendirme puanı için başka bir açıklayıcı ifade A=N(E, C)/(N(E)+N(C)-N(E, C)) şeklinde olabilir, burada N(E) örnek sayısıdır varlık bir bölümde görünür (örneğin, bir bütünlem), N(C) bağlamın bölümde göründüğü örneklerin sayısıdır ve N(E, C) hem E varlığının hem de bağlam C'nin birlikte göründüğü örneklerin sayısıdır bölümde. İki varlık arasında ilişki puanları oluşturmak için benzer ifadeler kullanılabilir.
Bu belirli varlık sınıfları ve bağlamları örneği, ilişkilendirme puanlarının bu tür puanların nasıl yararlı olabileceğini anlamaya nasıl yardımcı olabileceğini açıkça ortaya koymaktadır:
Örnek olarak, sunucu, "pas aldı" bağlamının, "basketbolcu" ve "kişi" varlık sınıflarının örnekleriyle birlikte gerçekleştiğini, bağlamın analiz edilen tüm belgelerde göründüğü zamanın yüzde 35 ve 97'sini belirleyebilir, sırasıyla. Sistem, varlıklar arasındaki ilişkileri belirlemek için en azından kısmen varlık ve bağlam modellerini kullanarak bu birlikte ortaya çıkma sıklıklarını belirleyebilir (örneğin, "LeBron James"in bir "basketbol oyuncusu" sınıfı örneği olduğunu belirlemek için). Bu örnekte, sunucu “pas alır” bağlamı ile “basketbolcu” ve “kişi” arasındaki ilişki puanlarının sırasıyla 0.35 ve 0.97 olduğunu belirleyebilir.
Bu birlikteliklerin tek bir belge yerine birden fazla belgeden oluştuğunu unutmayın.
İlişkilendirme puanlarının hesaplanmasında rol oynayabilecek başka faktörlere ilişkin başka örneklerimiz de var:
İlişkilendirme puanları, bir varlığın veya bağlamın her bir oluşumu için bir veya daha fazla ağırlık ekleyerek diğer hususları hesaba katabilir. Bazı yönlerden, bilgi işlem sistemi, zamansal ağırlıklar (örneğin, son belgeleri veya olayları daha ağır bir şekilde tartmak için), güvenilirlik ağırlıkları (örneğin, daha güvenilir kaynakları daha ağır bir şekilde tartmak için), popülerlik ağırlıkları (örneğin, daha popüler kaynakları daha ağır bir şekilde tartmak için), yakınlık ağırlıklarını (örneğin, birbirine daha yakın olan varlıkları/bağlamları daha ağır bir şekilde tartmak için) ve açıklanan düzenlemelerle tutarlı diğer herhangi bir ağırlık türünü. Belirli yönlerden ağırlık, diğerlerine kıyasla belirli bir belgenin veya münferit olayın göreceli önemini (örneğin, tüm olayların ağırlıkları toplamı 1.0'a eşittir), bir belgenin veya mutlak bir ölçekteki oluşumun önemini (örneğin, her bir ağırlık) yansıtabilir. bağımsız bir derecelendirmeyi yansıtır) veya iki varlık veya bağlam arasındaki ilişkiyi gösteren başka herhangi bir ölçü (örneğin, bir bağlam ile bir kuruluş arasındaki yakınlık).
Düşük bir ilişkilendirme puanı ne anlama gelebilir?
Bu nedenle, bazı düzenlemelerde düşük bir ilişki puanı, bir ilişkinin temel aldığı bir veri kaynağının genellikle güvenilmez veya güvenilmez olduğunu gösterebilir. Diğer düzenlemelerde, düşük bir ilişkilendirme puanı, yakın tarihli belgelerde özne çiftinin birlikte ortaya çıkmadığını gösterebilir. Yine başka düzenlemelerde, düşük bir çağrışım puanı, çift arasındaki birlikteliklerin nadir olduğunu gösterebilir (örneğin, birkaç "politikacı" "profesyonel basketbolcudur"). Yine başka düzenlemelerde, ilişkilendirme puanı, bu tür birçok faktörün bir kombinasyonunu yansıtabilir. Bazı yönlerden, bir sistem (örneğin, veri tabanlarıyla bağlantılı bir sunucu veya bir bilgisayar sistemi) zaman içinde ilişkilendirme puanlarını güncelleyebilir ve değiştirebilir (örneğin, yeni belgelere, bağlamlara ve niteliklere dayalı olarak).
İlişkilendirme puanları bize olasılıklar hakkında bir fikir verir:
Bir ilişki puanı, sayısal bir sayı (örneğin, 0.0 ila 1.0, 0 ila 100, vb.), nitel bir ölçek (örneğin, olası değil, olası, çok olası), renk kodlu bir ölçek ve/veya herhangi bir şekilde olabilir. derece seviyelerini belirleyebilen diğer ölçü veya derecelendirme şeması. Örneğin, bir düzenlemede, bir varlık veritabanı, "Bryce Harper" varlığının "Oct. 16, 1992.” Bu, örneğin, sistemin Bryce Harper'ın doğum tarihini %84 doğrulukla 16 Ekim 1992 olarak kabul ettiğini gösterebilir. Ayrıca, "Bryce Harper", bir ilişki puanı 1,0 olan "is a" özniteliği veya ilişkisi aracılığıyla bir varlık sınıfı "kişi" ile ilişkilendirilebilir ve bu, Bryce Harper'ın bir kişi olduğunun kesinliğini gösterir. Başka bir örnekte, "gol attı" bağlamı, sırasıyla 0.64, 0.49 ve 0.98 ilişki puanları olan "futbolcu", "hokey oyuncusu" ve "kişi" bağlam sınıflarıyla ilişkilendirilebilir. Bu örnek değerler, örneğin, bağlamın hokey oyuncularından ziyade futbolcularla ilgili olmasının daha muhtemel olduğunu ve yine de cümlenin genellikle özellikle futbolcular üzerinden bir veya daha fazla kişiye ait olduğunu gösterebilir. Yukarıda belirtildiği gibi, bir veya daha fazla varlık veritabanı (örneğin varlık veritabanı) ve bağlam veritabanları (örneğin bağlam veritabanı), sunucu ve/veya istemci cihaz varlıkları, nitelikleri, bağlamları depolayabilir, oluşturabilir, belirleyebilir, arşivleyebilir ve indeksleyebilir, bağlam sınıfları, ilişki puanları ve açıklanan düzenlemelerle tutarlı herhangi bir biçimdeki diğer bilgiler.
Varlık Çıkarımları Sırasında İlişkilendirme Puanlarına Sahip Bilgi Grafikleri
Patent, varlıkları niteliklere veya değerlere bağlayan her bir kenarda bulunan ilişki puanlarına sahip bir örnek Bilgi grafiğini açıklar:
Bazı yönlerde, bilgi grafiği, her biri bir varlığı yansıtan çok sayıda düğüm içerebilir. Bilgi grafiği ayrıca varlıklar ve belirli niteliklerin değerleri arasındaki ilişkileri tanımlayan nitelikleri yansıtan bir veya daha fazla kenar içerebilir. Bazı düzenlemelerde, bilgi grafiği ayrıca, bu tür ilişkilendirme puanları gerekli olmasa da, burada yer alan her kenar (örneğin her bir nitelik veya ilişkili değer) için bir ilişkilendirme puanı içerebilir. Şekil l'de gösterilen açıklayıcı bilgi grafiğinde; 2A, örneğin, belirli bir varlığı yansıtan varlık düğümü "Bryce Harper", 0.96'lık bir ilişki puanı ile "oynadığı" nesne özniteliği aracılığıyla başka bir varlık olan "Washington Nationals"a bağlıdır. Bu değerler ve ilişkiler, örneğin, Bryce Harper'ın Washington Nationals için bir oyuncu olduğunu ve sistemin bu özelliği 0.96'lık bir güven derecesi ile ilişkilendirdiğini gösterebilir. “Washington Nationals” kuruluşunun kendisi, düğümden çıkan karma çizgilerle gösterilen, gösterilmeyen diğer kuruluşlarla ilişkilendirilebilir. Diğer varlıklar, ŞEK. 2A-2C ve 3, benzer şekilde, gösterilmeyen diğer düğümler ve niteliklerle ilişkilendirilebilir ve buradaki belirli ilişkilerin ve değerlerin tasviri, yalnızca açıklayıcıdır.
İlişkilendirme puanları, bir varlıkla ilgili bir gerçeğin doğruluğuna dair bir güven duygusu sağlayabilir. Bryce Harper ile ilgili başka bir örnek dizisi:
İNCİR. 2A ayrıca "Bryce Harper" düğümünü "Oct. 16, 1992” ve değer varlık düğümü “60 Home Runs”, sırasıyla “doğum günü var” ve “kariyer İK toplamına sahip” öznitelikleri aracılığıyla. Bu niteliklerin ilgili ilişki puanları 0.84 ve 0.37'dir, bu da sistemin "doğum tarihi var" nitelik ilişkisiyle ilişkili değere, "kariyer İK toplamına sahip" ile ilişkili değerden daha fazla güvendiğini gösterir. Bu ilişki puanlarındaki fark, örneğin, bu tür ilişkileri oluşturmak için kullanılan kaynakların güvenilirliğinden, varlıklar arasında birlikte bulunma sıklığından, niteliklerin değerlerinden birinin (düğüm 204) olması gerçeğinden dolayı ortaya çıkabilir. zaman içinde değişen ve/veya açıklanan düzenlemelerle tutarlı diğer faktörler.
Her biri kendileriyle ilişkili birçok özellik veya özniteliğe sahip birçok farklı türü ve varlıklar, sınıflar ve alt sınıflar arasında güven düzeyleri sağlayan ilişkilendirme puanlarını kapsayan devasa bir bilgi grafiği hayal edin. Patent bize bunun muhtemel olacağını gösteriyor:
Bir varlık düğümü, bir varlık ile bir varlık sınıfı arasındaki ilişkinin doğasını tanımlayan nitelikler aracılığıyla bağlanan varlık sınıfları ve alt sınıflarıyla da ilişkilendirilebilir. Örneğin, ŞEK. 2A, "Bryce Harper" düğümü ile "kişi" ve "profesyonel beyzbol oyuncusu" varlık sınıfları arasındaki bağlantıları "is a" ve "mesleğe sahip" kenarları aracılığıyla gösterir. Bu niteliklerin sırasıyla 1.0 ve 0.99 ilişkilendirme puanları vardır. Açıklayıcı nitelikler ve ilişki puanları, sistemin Bryce Harper'ı mesleği kesin veya kesine yakın profesyonel bir beyzbol oyuncusu olan bir kişi olarak gördüğünü gösterir.
Varlık sınıfları ve diğer varlık sınıfları hakkında düşük ilişkilendirme puanlarından da öğreniyoruz:
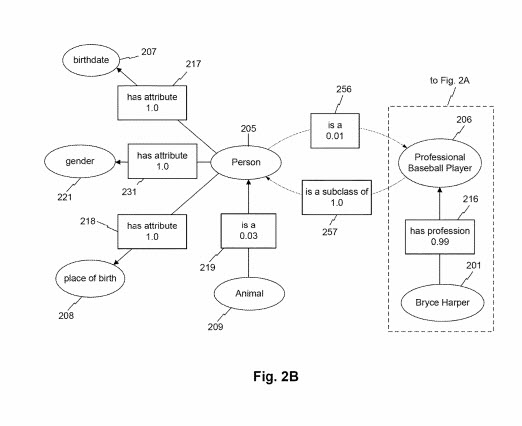
Şekil 2'de gösterildiği gibi. 2B'de, bir varlık sınıfı, varlık nitelikleri aracılığıyla diğer varlık sınıflarıyla da ilişkilendirilebilir. Örneğin, “hayvan” sınıfı, “is a” özniteliği aracılığıyla “kişi” sınıfıyla ilişkilendirilebilir. Bu örnekte, özniteliğe karşılık gelen ilişkilendirme puanı 0,03'tür. Bu, örneğin, "hayvan" sınıfı 209'un örneklerinin "kişi" sınıfının nadir örnekleri olduğunu gösterebilir (örneğin, diğer memeliler, böcekler, kuşlar, balıklar gibi insan dışı hayvanların yaygınlığı nedeniyle). Şekil 2'de gösterilmemesine rağmen. 2B'de, "kişi" sınıfı, "hayvan" düğümü ile bağlantılı olarak "bir" veya "bir alt sınıftır" vb. karşılıklı bir öznitelikle ilişkilendirilebilir. Böyle bir nitelik, "kişi" sınıfının "hayvan"ın bir alt sınıfı olduğunu gösteren daha yüksek bir ilişkilendirme puanı (örn., 0.94) ile ilişkilendirilebilir. Örneğin, ŞEK. 2B, ilişki puanı 1.0 olan "bir alt sınıftır" varlık özelliğiyle "kişi" sınıfıyla ilişkilendirilen "profesyonel beyzbol oyuncusu" sınıfını gösterir. Buna karşılık, “kişi” sınıf düğümü, “is a” özniteliği aracılığıyla “profesyonel beyzbol oyuncusu” düğümü ile 0,01 ilişki puanıyla ilişkilendirilebilir. Bu düşük ilişki puanı, örneğin, "profesyonel beyzbol oyuncusu" sınıfına ait olmayan "kişi" sınıfı varlıkların güçlü yaygınlığını yansıtabilir (örneğin, çoğu insan profesyonel beyzbol oyuncusu değildir). İNCİR. 2B ayrıca, profesyonel beyzbol oyuncusu sınıfı düğümünün, ŞEKİL 4 ile bağlantılı olarak tartışıldığı gibi, "bir mesleği vardır" özelliği aracılığıyla "Bryce Harper" varlık düğümü ile nasıl ilişkilendirilebileceğini gösterir. 2A.
Bir bağlam grafiğindeki varlık türleri ve bağlam sınıfları arasındaki ilişkilendirmeler, bize bu varlık türleri ve bağlamları hakkında belirli bilgiler verebilir:
Bazı düzenlemelerde, bağlam grafiğine dahil edilen varlık sınıfları, belirli bir bağlam (örn. bağlam) ile ilişkili bağlam sınıflarını temsil edebilir. Bu tür düzenlemelerde, bağlamları bağlam sınıflarına (ve dahil edilen herhangi bir alt sınıfa vb.) bağlayan bir ilişki puanı, bağlam sınıfı ile bağlam (örneğin kenar) arasındaki bir geçerlilik veya ilişki derecesini ve/veya ilgililik derecesini yansıtabilir. varlık sınıflarının kendileri arasında (örneğin, kenar). Bazı yönlerden, ilişkilendirme puanı, bağlamın ilişkili bağlam sınıfının veya bu bağlam sınıfının bir örneğinin varlığına işaret etme olasılığını yansıtabilir. Örneğin, Şekil 2'de gösterildiği gibi. 2D'de, "geçiş alan" bağlam düğümü, beş bağlam sınıfıyla ilişkilendirilebilir. Bu örnekte, "pası alan" bağlamı, "kişi", "beyzbol oyuncusu", "basketbol oyuncusu", "hokey oyuncusu" ve "futbol oyuncusu" bağlam sınıflarıyla ilişkilidir. puanlar gibi karşılık gelen bir ilişki puanı. Bu ilişki puanları, bağlamın belirli bir sınıf veya sınıf örneğinin varlığını belirtme olasılığını veya olasılığını belirtmek için eşlik eden "sınıf alır" ifadesi ile gösterilir.
Örneğin, "beyzbol oyuncusu" sınıfının bir üyesinin başka bir oyuncudan "pas alması" (bağlam) nadir olabileceğinden, satır öğesinde gösterildiği gibi bu bağlam sınıfıyla ilişkili ilişkilendirme puanı 0,02'dir. . Yukarıda açıklandığı gibi, bu değer, bağlam ile ağ kaynakları üzerinden “beyzbol oyuncusu” sınıfının bir örneği arasındaki ortak oluşum sıklığından, bu kaynakların güvenilirliğinden vb. kalan varlık sınıfları nispeten daha yüksektir. For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019