
การดึงข้อมูลเอนทิตีสำหรับกราฟความรู้ที่ Google
เผยแพร่แล้ว: 2019-02-15<
Google อาจใช้การแยกเอนทิตี คลาสเอนทิตี คุณสมบัติเอนทิตี และคะแนนการเชื่อมโยงจากเพจเพื่อสร้างกราฟความรู้
เมื่อ Google เปิดตัวกราฟความรู้ในปี 2012 Google บอกเราว่าจะเริ่มมุ่งเน้นไปที่สิ่งต่าง ๆ ไม่ใช่สตริง และจัดทำดัชนีวัตถุในโลกแห่งความเป็นจริง กระบวนการนั้นกำลังเติบโต และเรามีโอกาสได้เห็น Google เรียนรู้วิธีเริ่มรวบรวมข้อมูลเว็บเพื่อขุดข้อมูลและมีส่วนร่วมในการแยกเอนทิตี แทนที่จะขุดข้อมูลเว็บ เช่น เพจและลิงก์ ตามที่ฉันเขียนเมื่อเร็ว ๆ นี้บน Twitter เกี่ยวกับสิ่งนี้:
ในการรวบรวมข้อมูลเว็บ โหนดคือหน้า และขอบคือลิงก์ระหว่างหน้า ในการรวบรวมข้อมูล โหนดคือเอนทิตี และขอบคือความสัมพันธ์ระหว่างเอนทิตี เป็นวิวัฒนาการในการคิดเกี่ยวกับเว็บ
– Bill Slawski (@bill_slawski) วันที่ 10 กุมภาพันธ์ 2019
สิทธิบัตรของ Google ที่เพิ่งได้รับบอกเราว่าเครื่องมือค้นหาสามารถดึงเอนทิตีจากหน้าเว็บและจัดเก็บข้อมูลเกี่ยวกับสิ่งเหล่านี้ได้อย่างไร สิ่งนี้เป็นมากกว่าการใช้ฐานความรู้เป็นแหล่งข้อมูลเกี่ยวกับเอนทิตี และดำเนินการต่อไปเพื่อค้นหามากกว่าที่จะมีอยู่ในแหล่งดังกล่าวโดยการดูข้อความบนหน้าเว็บ นี่น่าจะหมายความว่าเราจะเห็นผลความรู้จากแหล่งต่างๆ มากกว่าที่เคยมีมา เช่น Wikipedia ปัญหาที่สิทธิบัตรนี้แก้ไขได้ในบรรทัดแรกนี้จากสิทธิบัตร:
ฐานความรู้ทั่วไป แต่ไม่สามารถให้ข้อมูลที่เป็นปัจจุบันหรือเชื่อถือได้เกี่ยวกับเอนทิตีและข้อมูลอื่น ๆ ที่ผู้ใช้ต้องการ
เราได้เห็น Google แยกเอนทิตีออกจากตารางและรายการที่คั่นด้วยโคลอนในสถานที่ต่างๆ เช่น Wikipedia และ IMDB จะเกิดอะไรขึ้นหากพวกเขาพบข้อมูลนั้นบนเว็บเพจ และดึงเอนทิตีออกจากเพจเหล่านั้น และรวบรวมคุณสมบัติและแอตทริบิวต์เกี่ยวกับเอนทิตีเหล่านั้นในขณะที่พวกเขารวบรวมข้อมูลหน้าเว็บ อาจมีวิธีวัดระดับความเชื่อมั่นของข้อมูลเกี่ยวกับหน่วยงานเหล่านั้นและความถูกต้องด้วย

ตามที่แสดงในรูปภาพเหล่านี้จากสิทธิบัตร Google จะคำนวณคะแนนการเชื่อมโยงระหว่างหน่วยงานและแอตทริบิวต์ที่เกี่ยวข้อง (เพิ่มเติมเกี่ยวกับคะแนนการเชื่อมโยงด้านล่าง)
ฉันได้เขียนเกี่ยวกับสิ่งที่คล้ายกันในโพสต์: กราฟความรู้ของ Google อัปเดตตัวเองอย่างไรโดยการตอบคำถาม จุดเน้นของโพสต์นั้นคือวิธีที่ Google อาจอัปเดตกราฟความรู้ที่มีอยู่ แทนที่จะค้นหาข้อมูลเกี่ยวกับเอนทิตีบนหน้าเว็บ และรับรู้ว่าพวกเขาอาจเข้าร่วมกับหน่วยงานประเภทอื่นได้อย่างไร การอาศัยฐานความรู้แทนการรักษาเว็บเป็นฐานข้อมูลขนาดใหญ่ดูเหมือนเป็นขั้นตอนบางส่วน หากเป็นไปได้ที่จะทำการแยกเอนทิตีด้วยวิธีที่ชาญฉลาดและมีประโยชน์ ขึ้นอยู่กับสารานุกรมที่มีการควบคุมโดยมนุษย์บนเว็บก็ไม่จำเป็น ในบางแห่งในอดีต Google เคยกล่าวว่าพวกเขาต้องการวิธีการที่ปรับขนาดได้ทางเว็บเพื่อจัดระเบียบข้อมูลบนเว็บ (เช่น เมื่อพวกเขาเลิกใช้ Google Directory ซึ่งมาจากแหล่งข้อมูลที่มาจากผู้คน)
สิทธิบัตรล่าสุดนี้เปิดเผยวิธีการต่างๆ ที่ช่วยให้ Google ทำการดึงข้อมูลเอนทิตีและข้อมูลอื่นๆ เกี่ยวกับหน่วยงานเหล่านั้น จากแหล่งที่เพิ่มลงในเว็บ แทนที่จะเพิ่มในฐานความรู้บนเว็บ รวมถึงหน้าเว็บใหม่และแหล่งข่าว
สิทธิบัตรมีส่วนสรุปในคำอธิบายซึ่งบอกเราเกี่ยวกับกระบวนการปกป้อง มันสรุปคำสองสามคำเช่นนี้:
รูปลักษณ์ที่เปิดเผยอาจจัดให้มีระบบและวิธีการสำหรับกำหนดคลาสและคุณลักษณะของเอนทิตีใหม่ เช่นเดียวกับคะแนนการเชื่อมโยงที่สะท้อนระดับของความเกี่ยวข้องและระดับของความเชื่อมั่นในความสัมพันธ์ที่กำหนด รูปลักษณ์ที่เปิดเผยอาจกำหนดคลาส คุณลักษณะ และคะแนนที่เกี่ยวข้องเหล่านี้โดยอิงตามบริบทของคำศัพท์ที่อยู่รอบๆ ซึ่งเอนทิตีใหม่ปรากฏขึ้นและเอนทิตีที่รู้จักใกล้เคียงกับเอนทิตีใหม่แต่ละเอนทิตี แง่มุมของรูปลักษณ์ที่เปิดเผยยังจัดให้มีระบบและวิธีการสำหรับการ อัพเดตแบบไดนามิกและการจัดเก็บความสัมพันธ์ที่กำหนดในแบบเรียลไทม์หรือใกล้เคียงเรียลไทม์
โดยจะขยายไปยังรายละเอียดเพิ่มเติมเล็กน้อยโดยให้เราดูขั้นตอนที่กระบวนการซึ่งเรียกว่า "การระบุผู้สมัครเอนทิตี" แบบเป็นขั้นเป็นตอน
การระบุผู้สมัครรับเลือกตั้งสำหรับการสกัดเอนทิตี
- ผู้สมัครเอนทิตีอยู่ในเอกสารที่สามารถเข้าถึงได้ผ่านเครือข่าย
- ผู้สมัครเอนทิตีที่ตรวจพบคือเอนทิตีใหม่ที่ยึดตามโมเดลเอนทิตีอย่างน้อยหนึ่งโมเดลที่จัดเก็บไว้ในฐานข้อมูล
- เอนทิตีที่รู้จักอยู่ถัดจากเอนทิตีใหม่และเอนทิตีที่รู้จักอยู่ในโมเดลเอนทิตีตั้งแต่หนึ่งโมเดลขึ้นไป
- บริบทที่อยู่ถัดจากเอนทิตีใหม่และเอนทิตีที่รู้จักมีความสัมพันธ์แบบคำศัพท์กับเอนทิตีที่รู้จัก
- คลาสเอนทิตีที่สองที่เกี่ยวข้องกับเอนทิตีที่รู้จักและคลาสบริบทนั้นสัมพันธ์กับบริบทด้วย
- คลาสเอนทิตีแรกเชื่อมต่อกับเอนทิตีใหม่ตามคลาสเอนทิตีที่สองและคลาสบริบท
- รายการแรกในฐานข้อมูลขึ้นอยู่กับโมเดลเอนทิตีอย่างน้อยหนึ่งโมเดล รายการที่สะท้อนถึงความสัมพันธ์ระหว่างคลาสเอนทิตีแรกกับเอนทิตีใหม่
สิทธิบัตรเอนทิตีเหล่านี้ที่ผู้สมัครอยู่ในเป็นสิทธิบัตรนี้เกี่ยวกับการแยกเอนทิตีและการจัดเก็บข้อมูลเกี่ยวกับเอนทิตีเหล่านั้น:
ระบบคอมพิวเตอร์และวิธีการในการดึงและจัดเก็บข้อมูลเกี่ยวกับหน่วยงาน
ผู้ประดิษฐ์: คริสโตเฟอร์ เซมเทิร์ส, โล้ด แวนเดเวน, ดานิลา ซิโนปาลนิคอฟ, อเล็กซานเดอร์ ลีอาชุก, เซบาสเตียน สไตเกอร์, เฮนริก กริมม์, นาธานาเอล มาร์ติน ชาร์ลี และเดวิด เลอคอมเต
ผู้รับมอบหมาย: GOOGLE LLC
สิทธิบัตรสหรัฐอเมริกา: 10,198,491
ได้รับ: กุมภาพันธ์ 5, 2019
ยื่น: 6 กรกฎาคม 2015
เชิงนามธรรม
ระบบและวิธีการที่ใช้คอมพิวเตอร์มีไว้สำหรับดึงและจัดเก็บข้อมูลเกี่ยวกับเอนทิตีจากเอกสาร เช่น เว็บเพจ ในการใช้งานครั้งเดียว จะมีการจัดเตรียมระบบที่ตรวจจับผู้สมัครเอนทิตีในเอกสารและกำหนดว่าผู้สมัครที่ตรวจพบนั้นเป็นเอนทิตีใหม่ ระบบยังตรวจพบเอนทิตีที่รู้จักใกล้เคียงกับเอนทิตีที่รู้จักโดยอิงจากโมเดลเอนทิตีตั้งแต่หนึ่งโมเดลขึ้นไป ระบบยังตรวจพบบริบทที่ใกล้เคียงกับเอนทิตีใหม่และที่รู้จักซึ่งมีความสัมพันธ์แบบคำศัพท์กับเอนทิตีที่รู้จัก ระบบยังกำหนดคลาสเอนทิตีที่สองที่เกี่ยวข้องกับเอนทิตีที่รู้จักและคลาสบริบทที่เกี่ยวข้องกับบริบท ระบบยังสร้างคลาสเอนทิตีแรกตามคลาสเอนทิตีที่สองและคลาสบริบท นอกจากนี้ ระบบยังสร้างรายการในแบบจำลองเอนทิตีตั้งแต่หนึ่งแบบจำลองขึ้นไปซึ่งสะท้อนถึงความเชื่อมโยงระหว่างเอนทิตีใหม่กับเอนทิตีแรก
การแยกเอนทิตี – เอนทิตี คลาสเอนทิตี อินสแตนซ์ของเอนทิตี และแอททริบิวต์ของเอนทิตี
ขั้นตอนแรกในกระบวนการที่เกี่ยวข้องกับสิทธิบัตรนี้เกี่ยวข้องกับการรับรู้หน่วยงานต่างๆ สิทธิบัตรให้ข้อมูลบางอย่างเกี่ยวกับสิ่งที่เป็นหน่วยงาน และให้ตัวอย่างหลายประการแก่เรา:
ในบางแง่มุม ตัวตนอาจสะท้อนถึงบุคคล (เช่น จอร์จ วอชิงตัน) สถานที่ (เช่น ซานฟรานซิสโก ไวโอมิง ถนนหรือทางแยกเฉพาะ เป็นต้น) หรือสิ่งของ (เช่น ดาว รถยนต์ นักการเมือง แพทย์ อุปกรณ์ , สนามกีฬา, คน, หนังสือ). ตัวอย่างเพิ่มเติม นิติบุคคลอาจสะท้อนถึงวรรณกรรม องค์กร (เช่น นิวยอร์กแยงกี้) องค์กรหรือพรรคการเมือง ธุรกิจ หน่วยงานอธิปไตยหรือหน่วยงานของรัฐ (เช่น สหรัฐอเมริกา NATO, FDA เป็นต้น) วันที่ (เช่น 4 ก.ค. 1776) ตัวเลข (เช่น 60 3.14159 จ) จดหมาย สถานะ คุณภาพ แนวคิด แนวคิด หรือการผสมผสานใดๆ
นอกเหนือจากคำจำกัดความของเอนทิตีแล้ว เรายังได้รับการบอกเล่าเกี่ยวกับคลาสเอนทิตีและคลาสย่อย และวิธีที่เอนทิตีอาจเข้ากับคลาสและคลาสย่อยต่างๆ นี่เป็นสิ่งสำคัญเนื่องจากเสิร์ชเอ็นจิ้นจะพยายามปรับเอนทิตีในคลาสต่างๆ เมื่อเรียนรู้เกี่ยวกับเอนทิตี
ดังนั้นคลาสเอนทิตีหรือคลาสย่อยคืออะไร?
สิทธิบัตรอธิบายในเชิงลึกเหล่านั้น:
ในบางลักษณะ เอนทิตีอาจเชื่อมโยงกับคลาสเอนทิตี คลาสเอนทิตีอาจแสดงถึงการจัดประเภท ประเภท หรือการจัดประเภทของกลุ่มหรือแบบจำลองตามแนวคิดของเอนทิตี เพื่อวัตถุประสงค์ของภาพประกอบ ตัวอย่างเช่น คลาสเอนทิตีอาจรวมถึง "บุคคล" "กาแลคซี่" "นักเบสบอล" "ต้นไม้" "ถนน" "นักการเมือง" เป็นต้น คลาสเอนทิตีอาจเชื่อมโยงกับคลาสย่อยตั้งแต่หนึ่งคลาสขึ้นไป . ในบางลักษณะ คลาสย่อยอาจสะท้อนถึงคลาสของเอนทิตีที่ถูกรวมไว้ในคลาสที่ใหญ่กว่า (เช่น “ซูเปอร์คลาส”) ในรายการคลาสที่แสดงตัวอย่างด้านบน ตัวอย่างเช่น คลาส "นักเบสบอล" และ "นักการเมือง" อาจเป็นคลาสย่อยของ "บุคคล" ของคลาส เพราะผู้เล่นเบสบอลและนักการเมืองทุกคนเป็นมนุษย์ ในรูปลักษณ์อื่น คลาสย่อยอาจเป็นตัวแทนของคลาสของเอนทิตีที่เกือบทั้งหมด แต่ไม่สมบูรณ์ เป็นส่วนหนึ่งของซูเปอร์คลาสที่ใหญ่กว่า การจัดการดังกล่าวอาจเกิดขึ้นในสถานการณ์ที่มีสิ่งผิดปกติหรือสิ่งที่สมมติขึ้น ตัวอย่างเช่น กลุ่ม "นักการเมือง" อาจเป็นกลุ่มย่อยของ "บุคคล" ระดับ แม้ว่าหน่วยงานที่สมมติขึ้นบางกลุ่มจะเป็นนักการเมืองที่ไม่ใช่มนุษย์ (เช่น "Mas Amedda") รูปลักษณ์ที่เปิดเผยมีวิธีการจัดการและการจัดการความสัมพันธ์ประเภทนี้ ตามที่อธิบายเพิ่มเติมด้านล่าง ทั้งคลาสและคลาสย่อยอาจเป็นตัวแทนของคลาสเอนทิตีและอาจประกอบขึ้นเอง
อินสแตนซ์ข้อมูลเป็นตัวอย่างของเอนทิตีเฉพาะที่เหมาะกับคลาสหรือคลาสย่อย โธมัส เจฟเฟอร์สันเป็นตัวอย่างของ “ประธานาธิบดีสหรัฐฯ” และ “ไมค์เทราต์” เป็นตัวอย่างเฉพาะของ “นักเบสบอลมืออาชีพ”
สิทธิบัตรทำงานในการรวบรวมข้อมูลเกี่ยวกับหน่วยงานและรวบรวมข้อมูลเกี่ยวกับหน่วยงานที่อ้างถึงว่าเป็น "แอตทริบิวต์ของนิติบุคคล" ตามที่อยู่ในภาพวาดนี้จากสิทธิบัตร:

สิ่งเหล่านี้อาจรวมถึงคุณสมบัติของเอนทิตีและความสัมพันธ์ระหว่างคลาสเอนทิตีด้วย สิทธิบัตรให้ข้อมูลเชิงลึกเกี่ยวกับคุณลักษณะที่อาจเป็นไปได้เช่นกัน:
เอนทิตีอาจเชื่อมโยงกับแอตทริบิวต์เอนทิตีและ/หรือแอตทริบิวต์ของออบเจ็กต์ตั้งแต่หนึ่งรายการขึ้นไป แอตทริบิวต์ของเอนทิตีอาจสะท้อนถึงคุณสมบัติ ลักษณะ คุณลักษณะ คุณภาพ หรือองค์ประกอบของคลาสเอนทิตีในบางลักษณะ ในบางลักษณะ ทุกอินสแตนซ์หรือเกือบทั้งหมดของคลาสเอนทิตีจะใช้ชุดแอตทริบิวต์ร่วมกันร่วมกัน ตัวอย่างเช่น เอนทิตี "บุคคล" อาจเชื่อมโยงกับแอตทริบิวต์ "วันเกิด" "สถานที่เกิด" "พ่อแม่" "เพศ" หรือโดยทั่วไป "มีแอตทริบิวต์" เป็นต้น ในอีกตัวอย่างหนึ่ง เอนทิตี "ทีมกีฬาอาชีพ" อาจเชื่อมโยงกับแอตทริบิวต์ของเอนทิตี เช่น "สถานที่" "รายได้ประจำปี" "บัญชีรายชื่อ" เป็นต้น ในรูปลักษณ์อื่นๆ แอตทริบิวต์ของเอนทิตีอาจอธิบายว่าเอนทิตีเกี่ยวข้องกับเอนทิตีอื่นอย่างไร ตัวอย่างเช่น แอตทริบิวต์ของเอนทิตีอาจอธิบายความสัมพันธ์ระหว่างคลาสเอนทิตี เช่น "เป็น" "เป็นคลาสย่อยของ" หรือ "เป็นซูเปอร์คลาสของ" หรือ "ประกอบด้วย" ตัวอย่างเช่น คลาส "ดาว" อาจเชื่อมโยงกับแอตทริบิวต์เอนทิตี "เป็นคลาสย่อยของ" กับคลาสเอนทิตี "วัตถุท้องฟ้า"
เมื่อพูดถึงการแยกเอนทิตี เราพบว่าคู่คีย์-ค่าใช้เพื่อบอกเราเพิ่มเติมเกี่ยวกับเอนทิตีเฉพาะ:
ในบางลักษณะ คุณลักษณะของอ็อบเจ็กต์อาจสะท้อนถึงความสัมพันธ์ระหว่างอินสแตนซ์คลาสเอนทิตีที่มีค่าแอตทริบิวต์เฉพาะ ตัวอย่างเช่น เอนทิตี "จอร์จ วอชิงตัน" อาจเชื่อมโยงกับแอตทริบิวต์อ็อบเจ็กต์ "มีวันเกิด" ด้วยค่า "ก.พ. 22, 1732” ในบางรูปลักษณ์ ค่าของแอ็ตทริบิวต์ของอ็อบเจ็กต์อาจสะท้อนถึงเอนทิตีด้วยตัวมันเอง ตัวอย่างเช่น ในตัวอย่างข้างต้น วันที่ “ก.พ. 22, 1732” อาจสะท้อนถึงนิติบุคคล
วิธีการรวบรวมข้อมูลเกี่ยวกับเอนทิตีนี้รวมถึงแอตทริบิวต์ที่อาจพบได้ทั่วไปในคลาสย่อยที่มีอยู่ภายใน:
ในบางรูปลักษณ์ เอนทิตีและคลาสย่อยสืบทอดแอ็ตทริบิวต์จากซูเปอร์คลาสที่พวกมันได้รับมา ตัวอย่างเช่น คลาส "ประธานาธิบดีสหรัฐฯ" อาจสืบทอดแอตทริบิวต์ "วันเกิด" จากซูเปอร์คลาส "บุคคล" นอกจากนี้ ในบางรูปลักษณ์ ซูเปอร์คลาสอาจไม่จำเป็นต้องสืบทอดแอ็ตทริบิวต์ของคลาสย่อยของพวกมัน ตัวอย่างเช่น คลาส "บุคคล" อาจไม่จำเป็นต้องสืบทอดแอตทริบิวต์ "ฐานที่ขโมยมา" จากคลาสย่อย "ผู้เล่นเบสบอลมืออาชีพ" หรือแอตทริบิวต์ "วันที่ดำรงตำแหน่ง" จากซับคลาส "ประธานาธิบดีสหรัฐฯ"
ฐานข้อมูลบริบทและการแยกเอนทิตี
ฉันจำ "บริบท" จากสคีมาบางอันที่ฉันเคยเห็นในอดีตได้ มีคำศัพท์หนึ่งที่อยู่ระหว่างการพิจารณาของ Schema โดยใช้คำว่า "รู้เกี่ยวกับ" ซึ่งคุณสามารถใช้เพื่ออธิบายบุคคลที่ทำหน้าที่ในวิชาชีพเฉพาะว่ามีประสบการณ์บางประเภท เงื่อนไขบริบทเหล่านี้คล้ายคลึงกันเนื่องจากช่วยให้ข้อมูลเพิ่มเติมเกี่ยวกับเอนทิตีที่ให้ข้อมูลเกี่ยวกับพวกเขา ข้อความเกี่ยวกับฐานข้อมูลบริบทจากสิทธิบัตรอธิบายได้ดี:
ในบางรูปลักษณ์ ฐานข้อมูลบริบทอาจจัดเก็บ เชื่อมโยง จัดการ และ/หรือให้ข้อมูลที่เกี่ยวข้องกับบริบทหนึ่งบริบทหรือมากกว่า บริบทอาจสะท้อนถึงการสร้างคำศัพท์หรือการแสดงคำตั้งแต่หนึ่งคำขึ้นไป (เช่น คำ วลี อนุประโยค ประโยค ย่อหน้า ฯลฯ) ที่สื่อความหมายให้กับคำหนึ่งคำขึ้นไป (เช่น เอนทิตี) ที่อยู่ใกล้เคียง ในบางรูปลักษณ์ บริบทอยู่ใน n-กรัม n-gram อาจสะท้อนถึงลำดับของ n คำ โดยที่ n เป็นจำนวนเต็มบวก ตัวอย่างเช่น บริบทอาจรวมถึง 1 กรัมเช่น "คือ" "เคยเป็น" หรือ "เห็นด้วย นอกจากนี้บริบทที่เป็นแบบอย่างอาจรวมถึง 3 กรัมเช่น "เกิดเมื่อ" "แต่งงานกับ" " ขโมยฐานที่สอง” หรือ “เขียนความขัดแย้ง” บริบท (และ n-กรัม) อาจรวมถึงช่องว่างที่มีความยาวเท่าใดก็ได้ เช่น 2 กรัม “จาก . . . จนกระทั่ง . . . ” ตามที่อธิบายไว้ในที่นี้ n-gram อาจแสดงลำดับใดๆ ดังกล่าว และ n-gram สองตัวไม่จำเป็นต้องแสดงถึงจำนวนชื่อของคำ ตัวอย่างเช่น “ทำประตูได้” และ “ในนาทีสุดท้าย” อาจประกอบเป็น n-grams แม้ว่าจะมีจำนวนคำต่างกันก็ตาม
การเรียนรู้เกี่ยวกับหน่วยงานและบริบทเป็นเรื่องของการเรียนรู้คำศัพท์ที่มีความหมายเพราะการทำเช่นนี้จะเป็นประโยชน์เมื่อต้องเรียนรู้เกี่ยวกับกระบวนการเบื้องหลังสิทธิบัตรนี้ และวิธีที่ Google อาจมีส่วนร่วมในการขุดข้อมูลเพื่อดึงข้อมูลเกี่ยวกับหน่วยงาน คุณลักษณะของพวกเขา และคุณสมบัติ และบริบทที่เราเห็น บริบทมีความซับซ้อนมากกว่าแค่ n-gram สั้นๆ ที่ช่วยจัดเตรียมบริบทให้กับเอนทิตี ส่วนถัดไปของสิทธิบัตรนี้บอกเราเกี่ยวกับคลาสบริบทและเอนทิตีบริบท:
ในบางรูปลักษณ์ บริบทอาจบ่งชี้ถึงการมีอยู่ของเอนทิตีหนึ่งรายการหรือมากกว่า เอนทิตีที่เป็นไปได้หนึ่งรายการหรือมากกว่าที่ระบุโดยบริบทอาจถูกอ้างถึงในที่นี้ว่าเป็น “คลาสบริบท” หรือ “เอนทิตีบริบท” อย่างไรก็ตาม การกำหนดเหล่านี้มีขึ้นเพื่อจุดประสงค์ในการอธิบายเท่านั้น เนื่องจากไม่ได้มีวัตถุประสงค์เพื่อจำกัด คลาสบริบทอาจสะท้อนถึงชุดของคลาสที่เกิดขึ้นโดยทั่วไปซึ่งเกี่ยวข้องกับ (เช่น มีความสัมพันธ์แบบศัพท์กับ) บริบท ในบางลักษณะ “คลาสบริบท” อาจสะท้อนถึงคลาสเอนทิตีเฉพาะ ตัวอย่างเช่น บริบท "แต่งงานกับ" อาจเกี่ยวข้องกับคลาสบริบทของเอนทิตี "บุคคล" เพราะบริบท "แต่งงานกับ" มักจะมีความสัมพันธ์ทางศัพท์กับมนุษย์ (เช่น มีความสัมพันธ์ระหว่างคำศัพท์กับอินสแตนซ์ ของประเภท "บุคคล") ในตัวอย่างนี้ ตัวอย่างเช่น ประโยค "Jack is married to Jill" ระบุว่าทั้ง "Jack" และ "Jill" เป็น "บุคคล" ระดับเดียวกัน เนื่องจากอย่างน้อยก็ในบางส่วน คลาสบริบทของบริบท “แต่งงานแล้ว” ในอีกตัวอย่างหนึ่ง บริบท "มีสัตว์เลี้ยง" อาจเกี่ยวข้องกับคลาสบริบท เช่น "สัตว์" "แมว" "สุนัข" "สัตว์ในบ้าน" และอื่นๆ ในทำนองเดียวกัน นอกจากนี้ ในตัวอย่างทางเลือกนี้ บริบท "มีสัตว์เลี้ยง" อาจส่งสัญญาณถึงการมีอยู่ของคลาสเอนทิตีที่ไม่อยู่ร่วมกัน เนื่องจากสองอินสแตนซ์ของคลาสเดียวกันมักไม่มีความสัมพันธ์เกี่ยวกับคำศัพท์ (เช่น ความสัมพันธ์แอตทริบิวต์ pet-master) . การตีความและการสร้างคลาสบริบทมีรายละเอียดเพิ่มเติมด้านล่าง
คะแนนสมาคมที่เกี่ยวข้องกับการแยกเอนทิตี
สิทธิบัตรมีรายละเอียดเพิ่มเติมเกี่ยวกับคลาสบริบทและเอนทิตีบริบท และสิ่งเหล่านี้ควรค่าแก่การดูในรายละเอียดเพิ่มเติม แต่ส่วนหนึ่งของสิทธิบัตรที่ดูเหมือนจะคุ้มค่าที่จะเรียนรู้เกี่ยวกับบางสิ่งที่เกี่ยวข้องกับการคำนวณคะแนนการเชื่อมโยงระหว่างการแยกเอนทิตี:
ในบางลักษณะ ฐานข้อมูลเอนทิตีและ/หรือฐานข้อมูลบริบทอาจจัดเก็บข้อมูลที่เกี่ยวข้องกับคะแนนความสัมพันธ์ตั้งแต่หนึ่งคะแนนขึ้นไป คะแนนการเชื่อมโยงอาจสะท้อนถึงความเป็นไปได้หรือระดับความเชื่อมั่นว่าแอตทริบิวต์ ค่าแอตทริบิวต์ ความสัมพันธ์ ลำดับชั้นของคลาส คลาสบริบทที่กำหนด หรือการเชื่อมโยงอื่นๆ นั้นถูกต้อง ถูกต้อง และ/หรือถูกต้องตามกฎหมาย ตัวอย่างเช่น ในบางรูปลักษณ์ คะแนนการเชื่อมโยงอาจสะท้อนถึงระดับความเกี่ยวข้องระหว่างสองเอนทิตีหรือบริบทและเอนทิตี คะแนนการเชื่อมโยงอาจถูกกำหนดโดยกระบวนการใดๆ ที่สอดคล้องกับรูปลักษณ์ที่เปิดเผย ตัวอย่างเช่น ตามที่อธิบายไว้ในรายละเอียดที่มากขึ้นด้านล่าง ระบบคอมพิวเตอร์ (เช่น เซิร์ฟเวอร์) อาจกำหนดคะแนนการเชื่อมโยงโดยใช้ปัจจัยและน้ำหนัก เช่น ความน่าเชื่อถือของแหล่งที่มาซึ่งสร้างคะแนนการเชื่อมโยง ความถี่หรือจำนวนการเกิดขึ้นร่วมระหว่าง สองเอนทิตีในเนื้อหา (เช่น เป็นหน้าที่ของจำนวนการเกิดขึ้นทั้งหมด จำนวนเอกสารทั้งหมดที่มีหนึ่งหรือทั้งสองเอนทิตี เป็นต้น) คุณลักษณะของเอนทิตีเอง (เช่น เอนทิตีเป็นคลาสย่อยของอีกเอนทิตีหนึ่งหรือไม่) ความใหม่ ของความสัมพันธ์ที่ค้นพบ (เช่น โดยให้น้ำหนักมากขึ้นกับสมาคมที่ใหม่กว่าหรือเก่ากว่า) ไม่ว่าแอตทริบิวต์นั้นมีแนวโน้มที่จะผันผวนหรือไม่ก็ตาม (เช่น เป็นระยะหรือเป็นระยะ) จำนวนสัมพัทธ์ระหว่างคลาสเอนทิตี ความนิยมของเอนทิตีเป็น คู่ ค่าเฉลี่ย ค่ามัธยฐาน สถิติ และ/หรือระยะใกล้เคียงกันระหว่างสองเอนทิตีในเอกสารที่วิเคราะห์ และ/หรือกระบวนการอื่นใดที่เปิดเผยในที่นี้ ในบางลักษณะ ระบบอาจสร้างคะแนนความสัมพันธ์ตั้งแต่หนึ่งคะแนนขึ้นไป ในบางลักษณะ ระบบอาจโหลดคะแนนการเชื่อมโยงล่วงหน้าอย่างน้อยหนึ่งคะแนนตามโครงสร้างข้อมูลที่สร้างไว้ล่วงหน้า (เช่น เก็บไว้ในฐานข้อมูล 140 และ/หรือ 150)

ที่น่าสนใจ สิ่งต่างๆ เช่น ความน่าเชื่อถือของแหล่งที่มาอาจมีบทบาทในคะแนนความสัมพันธ์ที่กำหนดให้กับความสัมพันธ์ระหว่างเอนทิตีหรือบริบทและเอนทิตี ส่วนถัดไปจะกล่าวถึงสิ่งที่พวกเขาเรียกว่า "อัตราส่วนของการเกิดขึ้นร่วมระหว่างบริบทและเอนทิตี":
ในรูปลักษณ์หนึ่ง ตัวอย่างเช่น ระบบการคำนวณ (เช่น เซิร์ฟเวอร์) อาจสร้างคะแนนการเชื่อมโยงระหว่างบริบทและเอนทิตีโดยกำหนดอัตราส่วนของการเกิดขึ้นร่วมระหว่างบริบทและเอนทิตี (เช่น เอนทิตีเฉพาะ ตัวอย่างของ คลาสเอนทิตี ฯลฯ) กับบริบทและ/หรือเอนทิตีที่เกิดขึ้นทั้งหมดในเอกสารเครือข่าย ตัวอย่างเช่น นิพจน์ที่แสดงตัวอย่างหนึ่งอาจอยู่ในรูปแบบ A=P(E, C)/P(C) โดยที่ A คือตัวอย่างค่าการเชื่อมโยงระหว่างเอนทิตีและบริบท P(C) คือความน่าจะเป็นที่จะพบบริบท ในส่วนของข้อความ (เช่น เอกสาร หน้าเว็บอย่างน้อยหนึ่งหน้า คลังข้อมูล เป็นต้น) และ P(E, C) คือความน่าจะเป็นที่จะพบทั้งเอนทิตีบริบทที่เกิดขึ้นร่วมกันในส่วน ในตัวอย่างนี้ คะแนนการเชื่อมโยงอาจสะท้อนถึงความน่าจะเป็นแบบมีเงื่อนไขของการค้นหาเอนทิตี E เมื่อบริบท C ปรากฏขึ้น อีกตัวอย่างหนึ่งสำหรับคะแนนการเชื่อมโยงอาจอยู่ในรูปแบบ A=N(E, C)/(N(E)+N(C)-N(E, C)) โดยที่ N(E) คือจำนวนอินสแตนซ์ เอนทิตีปรากฏในส่วน (เช่น คลังข้อมูล) N(C) คือจำนวนอินสแตนซ์ที่บริบทปรากฏในส่วน และ N(E, C) คือจำนวนอินสแตนซ์ของทั้งเอนทิตี E และบริบท C ปรากฏพร้อมกัน ในส่วน นิพจน์ที่คล้ายกันอาจใช้เพื่อสร้างคะแนนความสัมพันธ์ระหว่างสองเอนทิตี
ตัวอย่างของคลาสและบริบทเฉพาะของเอนทิตีทำให้ชัดเจนว่าคะแนนการเชื่อมโยงอาจช่วยให้เข้าใจว่าคะแนนดังกล่าวมีประโยชน์อย่างไร:
ตัวอย่างเช่น เซิร์ฟเวอร์อาจกำหนดว่าบริบท "รับผ่าน" เกิดขึ้นร่วมกับอินสแตนซ์ของคลาสเอนทิตี "ผู้เล่นบาสเกตบอล" และ "บุคคล" 35 และ 97 เปอร์เซ็นต์ของเวลาที่บริบทปรากฏในเอกสารที่วิเคราะห์ทั้งหมด ตามลำดับ ระบบอาจกำหนดความถี่ของการเกิดขึ้นร่วมกันโดยใช้ อย่างน้อยก็ในบางส่วน โมเดลเอนทิตีและบริบทเพื่อกำหนดความสัมพันธ์ระหว่างเอนทิตี (เช่น เพื่อพิจารณาว่า “เลอบรอน เจมส์” เป็นตัวอย่างของคลาส “นักบาสเกตบอล”) ในตัวอย่างนี้ เซิร์ฟเวอร์อาจกำหนดว่าคะแนนความสัมพันธ์ที่เกี่ยวข้องกับบริบท "รับบอลจาก" ถึง "ผู้เล่นบาสเกตบอล" และ "บุคคล" เป็น 0.35 และ 0.97 ตามลำดับ
โปรดทราบว่าเหตุการณ์ร่วมเหล่านี้มาจากคลังเอกสารมากกว่าหนึ่งรายการ
เรามีตัวอย่างอื่นๆ ของปัจจัยอื่นๆ ที่อาจส่งผลต่อการคำนวณคะแนนความสัมพันธ์:
คะแนนความเชื่อมโยงอาจพิจารณาถึงข้อควรพิจารณาอื่นๆ โดยการรวมน้ำหนักตั้งแต่หนึ่งรายการขึ้นไปสำหรับการเกิดขึ้นของเอนทิตีหรือบริบทในแต่ละครั้ง ในบางลักษณะ ระบบการคำนวณอาจใช้การถ่วงน้ำหนักเพื่อพิจารณาปัจจัยต่างๆ เช่น น้ำหนักชั่วคราว (เช่น เพื่อชั่งน้ำหนักเอกสารล่าสุดหรือเหตุการณ์ที่เกิดขึ้นให้หนักขึ้น) ตุ้มน้ำหนักที่น่าเชื่อถือ (เช่น การชั่งน้ำหนักแหล่งที่มาที่เชื่อถือได้มากขึ้น) ตุ้มน้ำหนักยอดนิยม (เช่น เพื่อชั่งน้ำหนักแหล่งที่มาที่เป็นที่นิยมมากขึ้นอย่างหนาแน่นมากขึ้น) น้ำหนักที่ใกล้เคียงกัน (เช่น เพื่อชั่งน้ำหนักเอนทิตี/บริบทที่เกิดขึ้นใกล้กันมากขึ้นอย่างเข้มงวดมากขึ้น) และน้ำหนักประเภทอื่นๆ ที่สอดคล้องกับรูปลักษณ์ที่เปิดเผย ในบางลักษณะ น้ำหนักอาจสะท้อนถึงความสำคัญเชิงสัมพันธ์ของเอกสารเฉพาะหรือเหตุการณ์ที่เกิดขึ้นกับบุคคลอื่น (เช่น น้ำหนักสำหรับเหตุการณ์ทั้งหมดรวมเป็น 1.0) ความสำคัญของเอกสารหรือการเกิดขึ้นในระดับสัมบูรณ์ (เช่น น้ำหนักแต่ละรายการ สะท้อนถึงการให้คะแนนโดยอิสระ) หรือการวัดอื่นใดที่บ่งชี้ถึงความเกี่ยวข้องระหว่างสองหน่วยงานหรือบริบท (เช่น ความใกล้ชิดระหว่างบริบทกับเอนทิตี)
คะแนนความสัมพันธ์ต่ำอาจหมายถึงอะไร
ดังนั้น ในบางรูปลักษณ์ คะแนนการเชื่อมโยงต่ำอาจบ่งชี้ว่าแหล่งข้อมูลซึ่งมีความสัมพันธ์เป็นพื้นฐานโดยทั่วไปไม่น่าไว้วางใจหรือไม่น่าเชื่อถือ ในรูปลักษณ์อื่น คะแนนการเชื่อมโยงต่ำอาจบ่งชี้ว่าการเกิดขึ้นร่วมของคู่เรื่องไม่เกิดขึ้นในเอกสารล่าสุด ในรูปลักษณ์อื่น ๆ ที่ยังคงมีคะแนนการเชื่อมโยงที่ต่ำอาจบ่งชี้ว่าการเกิดขึ้นร่วมระหว่างทั้งคู่นั้นเกิดขึ้นได้ยาก (เช่น “นักการเมือง” ไม่กี่คนที่เป็น “ผู้เล่นบาสเก็ตบอลมืออาชีพ”) ในรูปลักษณ์อื่นนอกไปจากนี้ คะแนนการเชื่อมโยงอาจสะท้อนถึงการรวมกันของปัจจัยดังกล่าวจำนวนมาก ในบางแง่มุม ระบบ (เช่น เซิร์ฟเวอร์หรือระบบคอมพิวเตอร์ที่เกี่ยวข้องกับฐานข้อมูล) อาจอัปเดตและแก้ไขคะแนนการเชื่อมโยงเมื่อเวลาผ่านไป (เช่น ขึ้นอยู่กับเอกสาร บริบท และคุณลักษณะใหม่)
คะแนนสมาคมทำให้เราทราบถึงความเป็นไปได้:
คะแนนการเชื่อมโยงอาจอยู่ในรูปของตัวเลข (เช่น 0.0 ถึง 1.0, 0 ถึง 100 เป็นต้น) มาตราส่วนเชิงคุณภาพ (เช่น ไม่น่าเป็นไปได้ มีแนวโน้มมาก) มาตราส่วนที่มีรหัสสี และ/หรือใดๆ การวัดผลหรือรูปแบบการให้คะแนนอื่นที่สามารถระบุระดับปริญญาได้ ตัวอย่างเช่น ในรูปลักษณ์หนึ่ง ฐานข้อมูลของเอนทิตีอาจเก็บคะแนนการเชื่อมโยงที่ 0.84 ซึ่งสะท้อนว่าโอกาสที่เอนทิตี "Bryce Harper" จะเชื่อมโยงกับแอตทริบิวต์ "วันเกิด" ที่มีค่า "ต.ค. 16 พ.ศ. 2535” ตัวอย่างนี้อาจบ่งบอกว่าระบบถือว่าวันเกิดของ Bryce Harper คือวันที่ 16 ต.ค. 1992 ด้วยความแม่นยำ 84% นอกจากนี้ “Bryce Harper” อาจเชื่อมโยงกับคลาสเอนทิตี “บุคคล” ผ่านคุณลักษณะหรือความสัมพันธ์ “เป็น” ด้วยคะแนนการเชื่อมโยง 1.0 ซึ่งบ่งชี้ถึงความแน่นอนว่า Bryce Harper เป็นบุคคล ในอีกตัวอย่างหนึ่ง บริบท "ทำประตู" อาจเชื่อมโยงกับคลาสบริบท "นักฟุตบอล" "ผู้เล่นฮ็อกกี้" และ "บุคคล" ด้วยคะแนนการเชื่อมโยง 0.64, 0.49 และ 0.98 ตามลำดับ ค่านิยมที่เป็นแบบอย่างเหล่านี้อาจบ่งบอก เช่น มีแนวโน้มว่าบริบทจะเกี่ยวข้องกับผู้เล่นฟุตบอลมากกว่าผู้เล่นฮอกกี้ และมีแนวโน้มว่าประโยคนั้นยังเกี่ยวข้องกับบุคคลหนึ่งคนขึ้นไปโดยทั่วไปโดยเฉพาะเหนือผู้เล่นฟุตบอลโดยเฉพาะ ตามที่ระบุไว้ข้างต้น ฐานข้อมูลเอนทิตีตั้งแต่หนึ่งฐานข้อมูลขึ้นไป (เช่น ฐานข้อมูลเอนทิตี) และฐานข้อมูลบริบท (เช่น ฐานข้อมูลบริบท) เซิร์ฟเวอร์และ/หรืออุปกรณ์ไคลเอนต์อาจจัดเก็บ สร้าง กำหนด จัดเก็บ และสร้างดัชนีเอนทิตี คุณลักษณะ บริบท คลาสบริบท คะแนนความสัมพันธ์ และข้อมูลอื่นใดในรูปแบบใดๆ ที่สอดคล้องกับรูปลักษณ์ที่เปิดเผย
กราฟความรู้พร้อมคะแนนความสัมพันธ์ระหว่างการแยกเอนทิตี
สิทธิบัตรอธิบายตัวอย่าง กราฟความรู้ ที่มีคะแนนการเชื่อมโยงที่รวมอยู่ในแต่ละขอบที่เชื่อมโยงเอนทิตีกับคุณลักษณะหรือค่า:
ในบางลักษณะ กราฟความรู้อาจประกอบรวมด้วยโหนดจำนวนมาก โดยแต่ละโหนดสะท้อนถึงเอนทิตี กราฟความรู้อาจรวมหนึ่งขอบหรือมากกว่าซึ่งสะท้อนถึงคุณลักษณะที่อธิบายความสัมพันธ์ระหว่างเอนทิตีและค่าของคุณลักษณะเฉพาะ ในบางรูปลักษณ์ กราฟความรู้ยังอาจรวมคะแนนการเชื่อมโยงสำหรับแต่ละขอบ (เช่น แต่ละคุณลักษณะหรือค่าที่เกี่ยวข้อง) ที่อยู่ในนั้น ถึงแม้ว่าคะแนนการเชื่อมโยงดังกล่าวจะไม่จำเป็น ในกราฟความรู้ที่แสดงภาพประกอบที่แสดงไว้ในรูปที่ ตัวอย่างเช่น 2A โหนดเอนทิตี "Bryce Harper" ซึ่งสะท้อนถึงเอนทิตีเฉพาะ เชื่อมต่อกับเอนทิตีอื่น "Washington Nationals" ผ่านแอตทริบิวต์ของวัตถุ "เล่นเพื่อ" ด้วยคะแนนการเชื่อมโยง 0.96 ค่านิยมและความสัมพันธ์เหล่านี้อาจบ่งบอก ตัวอย่างเช่น ไบรซ์ ฮาร์เปอร์เป็นผู้เล่นของวอชิงตัน เนชั่นแนล และระบบเชื่อมโยงแอตทริบิวต์นี้ด้วยระดับความเชื่อมั่นที่ 0.96 เอนทิตี “Washington Nationals” อาจเชื่อมโยงกับเอนทิตีอื่นๆ ที่ไม่ได้แสดง โดยระบุด้วยเส้นที่แฮชที่เล็ดลอดออกมาจากโหนด เอนทิตีอื่นๆ ถูกแสดงไว้ในรูปที่ 2A-2C และ 3 สามารถเชื่อมโยงในทำนองเดียวกันกับโหนดและคุณลักษณะอื่นๆ ที่ไม่ได้แสดงไว้ และการพรรณนาถึงความสัมพันธ์และค่าบางอย่างในนั้นเป็นเพียงตัวอย่างเท่านั้น
คะแนนการเชื่อมโยงสามารถให้ความรู้สึกมั่นใจในความถูกต้องของข้อเท็จจริงที่เกี่ยวข้องกับเอนทิตี ตัวอย่างอื่นๆ ที่เกี่ยวข้องกับ Bryce Harper:
รูปที่. 2A ยังแสดงให้เห็นการเชื่อมโยงโหนด “Bryce Harper” กับโหนดวันที่ “ต.ค. 16, 1992” และโหนดมูลค่าเอนทิตี “60 Home Runs” ผ่านแอตทริบิวต์ “มีวันเกิด” และ “มียอดรวม HR ในอาชีพ” ตามลำดับ คุณลักษณะเหล่านี้มีคะแนนความสัมพันธ์ตามลำดับที่ 0.84 และ 0.37 ซึ่งบ่งชี้ว่าระบบมีความมั่นใจในค่าที่เกี่ยวข้องกับความสัมพันธ์ของแอตทริบิวต์ "มีวันเกิด" มากกว่าค่าที่เกี่ยวข้องกับ "มี HR รวมในอาชีพ" ความแตกต่างในคะแนนความสัมพันธ์เหล่านี้อาจเกิดขึ้น เช่น เนื่องจากความน่าเชื่อถือของแหล่งที่มาที่ใช้ในการสร้างความสัมพันธ์ดังกล่าว ความถี่ของการเกิดขึ้นร่วมกันระหว่างหน่วยงาน ความจริงที่ว่าหนึ่งในค่าของคุณลักษณะ (โหนด 204) คือ การเปลี่ยนแปลงเมื่อเวลาผ่านไป และ/หรือปัจจัยอื่นๆ ที่สอดคล้องกับรูปลักษณ์ที่เปิดเผย
รูปภาพกราฟความรู้ขนาดใหญ่ที่ครอบคลุมหลายประเภท โดยแต่ละประเภทมีคุณสมบัติหรือแอตทริบิวต์ที่เกี่ยวข้องมากมาย และคะแนนการเชื่อมโยงที่ให้ระดับความมั่นใจระหว่างเอนทิตีและคลาสและคลาสย่อย สิทธิบัตรแสดงให้เราเห็นว่าสิ่งนี้น่าจะ:
โหนดเอนทิตีอาจเชื่อมโยงกับคลาสเอนทิตีและคลาสย่อย ซึ่งเชื่อมต่อผ่านแอตทริบิวต์ที่อธิบายลักษณะของความสัมพันธ์ระหว่างเอนทิตีและคลาสเอนทิตี ตัวอย่างเช่นมะเดื่อ 2A แสดงถึงการเชื่อมต่อระหว่างโหนด "Bryce Harper" และคลาสเอนทิตี "บุคคล" และ "ผู้เล่นเบสบอลมืออาชีพ" ผ่านขอบตามลำดับ "เป็น" และ "มีอาชีพ" คุณลักษณะเหล่านี้มีคะแนนความสัมพันธ์ 1.0 และ 0.99 ตามลำดับ คุณลักษณะที่แสดงตัวอย่างและคะแนนความสัมพันธ์ระบุว่าระบบถือว่า Bryce Harper เป็นบุคคลที่ประกอบอาชีพเป็นนักเบสบอลมืออาชีพด้วยความแน่นอนหรือใกล้เคียง
นอกจากนี้เรายังได้เรียนรู้จากคะแนนความสัมพันธ์ที่ต่ำเกี่ยวกับคลาสเอนทิตีและคลาสเอนทิตีอื่นๆ:
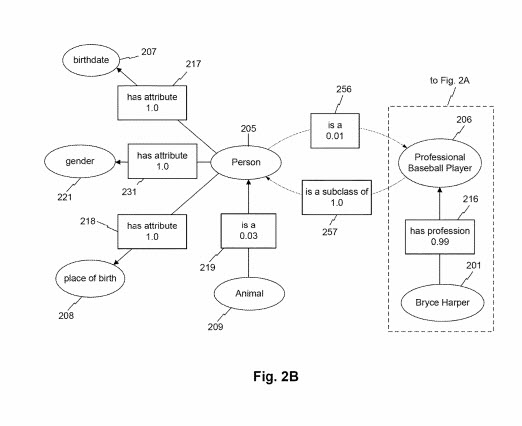
ตามที่แสดงไว้ในรูปที่ 2B คลาสเอนทิตีอาจเชื่อมโยงกับคลาสเอนทิตีอื่นผ่านแอตทริบิวต์เอนทิตี ตัวอย่างเช่น คลาส "animal" อาจเชื่อมโยงกับคลาส "person" โดยใช้แอตทริบิวต์ "is a" ในตัวอย่างนี้ คะแนนการเชื่อมโยงที่สอดคล้องกับแอตทริบิวต์คือ 0.03 สิ่งนี้อาจบ่งชี้ ตัวอย่างเช่น อินสแตนซ์ของคลาส "สัตว์" 209 เป็นตัวอย่างที่หายากของประเภท "บุคคล" (เช่น เนื่องจากความชุกของสัตว์ที่ไม่ใช่มนุษย์ เช่น สัตว์เลี้ยงลูกด้วยนม แมลง นก ปลา เป็นต้น) ในขณะที่ไม่ได้ปรากฎในรูปที่ 2B คลาส "บุคคล" อาจเกี่ยวข้องกับแอตทริบิวต์ซึ่งกันและกัน "คือ" หรือ "เป็นคลาสย่อยของ" ฯลฯ ที่เกี่ยวข้องกับโหนด "สัตว์" คุณลักษณะดังกล่าวอาจเชื่อมโยงกับคะแนนความสัมพันธ์ที่สูงขึ้น (เช่น 0.94) ซึ่งบ่งชี้ว่าคลาส "บุคคล" เป็นคลาสย่อยของ "สัตว์" ตัวอย่างเช่นมะเดื่อ 2B แสดงถึงคลาส "นักเบสบอลมืออาชีพ" ที่เชื่อมโยงกับคลาส "บุคคล" ที่มีแอตทริบิวต์เอนทิตี "เป็นคลาสย่อยของ" ด้วยคะแนนความสัมพันธ์ 1.0 ในทางตรงกันข้าม โหนดคลาส "บุคคล" อาจเชื่อมโยงกับโหนด "ผู้เล่นเบสบอลมืออาชีพ" ผ่านแอตทริบิวต์ "คือ a" ด้วยคะแนนความสัมพันธ์ 0.01 คะแนนความสัมพันธ์ที่ต่ำกว่านี้อาจสะท้อนถึงความชุกของตัวตนของ "บุคคล" ระดับกลุ่มซึ่งไม่ใช่ "นักเบสบอลมืออาชีพ" ในชั้นเรียน (เช่น คนส่วนใหญ่ไม่ใช่ผู้เล่นเบสบอลมืออาชีพ) รูปที่. 2B อธิบายเพิ่มเติมว่าโหนดคลาสนักเบสบอลมืออาชีพอาจเชื่อมโยงกับโหนดเอนทิตี "Bryce Harper" ผ่านแอตทริบิวต์ "มีอาชีพ" ตามที่กล่าวถึงในความสัมพันธ์กับมะเดื่อ 2A.
การเชื่อมโยงระหว่างประเภทเอนทิตีและคลาสบริบทในกราฟบริบทอาจบอกข้อมูลเฉพาะเกี่ยวกับประเภทและบริบทของเอนทิตีเหล่านั้นให้เราทราบ:
ในบางรูปลักษณ์ คลาสเอนทิตีที่รวมอยู่ในกราฟบริบทอาจแสดงคลาสบริบทที่เกี่ยวข้องกับบริบทเฉพาะ (เช่น บริบท) ในรูปลักษณ์ดังกล่าว คะแนนการเชื่อมโยงที่เชื่อมโยงบริบทกับคลาสบริบท (และคลาสย่อยที่รวมอยู่ใดๆ เป็นต้น) อาจสะท้อนถึงระดับของความถูกต้องหรือความเกี่ยวข้องระหว่างคลาสบริบทและบริบท (เช่น ขอบ) และ/หรือระดับของความเกี่ยวข้อง ระหว่างคลาสของเอนทิตีเอง (เช่น edge) ในบางลักษณะ ดังนั้น คะแนนการเชื่อมโยงอาจสะท้อนถึงความเป็นไปได้ที่บริบทส่งสัญญาณการมีอยู่ของคลาสบริบทที่เกี่ยวข้องหรืออินสแตนซ์ของคลาสบริบทนั้น ตัวอย่างเช่น ดังแสดงในรูปที่ 2D โหนดบริบท "รับการส่งผ่านจาก" อาจเชื่อมโยงกับห้าคลาสบริบท ในตัวอย่างนี้ บริบท “รับบอลจาก” สัมพันธ์กับคลาสบริบท “บุคคล” “ผู้เล่นเบสบอล” “ผู้เล่นบาสเกตบอล” “ผู้เล่นฮอกกี้” และ “ผู้เล่นฟุตบอล” แต่ละสมาคมเหล่านี้อาจรวมถึง คะแนนความสัมพันธ์ที่เกี่ยวข้อง เช่น คะแนน คะแนนความเชื่อมโยงเหล่านี้แสดงด้วยวลีประกอบ "เข้าชั้นเรียน" เพื่อระบุโอกาสหรือความน่าจะเป็นที่บริบทบ่งชี้ว่ามีชั้นเรียนหรืออินสแตนซ์ของชั้นเรียนเฉพาะ
ตัวอย่างเช่น เนื่องจากอาจเป็นเรื่องยากสำหรับสมาชิกของคลาส "นักเบสบอล" ที่จะ "รับบอลจาก" (บริบท) ผู้เล่นอื่น คะแนนการเชื่อมโยงที่เกี่ยวข้องกับคลาสบริบทนี้คือ 0.02 ดังที่แสดงในรายการโฆษณา . ตามที่อธิบายไว้ข้างต้น ค่านี้อาจสร้างขึ้นจากความถี่ของการเกิดขึ้นร่วมระหว่างบริบทและอินสแตนซ์ของคลาส "นักเบสบอล" เหนือแหล่งที่มาของเครือข่าย ความน่าเชื่อถือของแหล่งที่มาเหล่านั้น ฯลฯ ในทางตรงกันข้าม คะแนนความสัมพันธ์ระหว่างบริบทและ คลาสเอนทิตีที่เหลือค่อนข้างสูง For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019