
Google 知識圖譜的實體提取
已發表: 2019-02-15<
谷歌可能會使用實體提取、實體類、實體屬性和頁面的關聯分數來構建知識圖
當谷歌在 2012 年推出知識圖譜時,它告訴我們它將開始關注事物而不是字符串,並索引現實世界的對象。 這個過程正在成熟,我們有機會看到谷歌學習如何開始爬網來挖掘數據並參與實體提取,而不是挖掘網頁和鏈接等網絡信息。 正如我最近在 Twitter 上寫到的:
在網絡爬蟲中,節點是頁面,邊是頁面之間的鏈接; 在數據爬取中,節點是實體,邊是實體之間的關係。 這是對 Web 的一種思考方式的演變。
— 比爾·斯拉夫斯基 (@bill_slawski),2019 年 2 月 10 日
最近授予的一項 Google 專利告訴我們搜索引擎如何從網頁中提取實體並存儲有關它們的信息。 這不僅僅是使用知識庫作為有關實體的信息來源,而且通過查看網頁上的文本段落,可以找到比此類來源中可用的更多內容。 這可能意味著我們將看到比過去更多來源的知識結果,例如維基百科。 該專利在該專利的早期線路中解決的問題:
傳統知識庫,但可能無法提供有關實體的最新或可靠信息以及用戶所需的其他信息。
我們已經看到 Google 從維基百科和 IMDB 等地方的表格和冒號分隔列表中提取實體。 如果他們可以在網頁上找到該信息,並從這些網頁中提取實體,並在他們抓取網頁時收集有關這些實體的屬性和屬性,那會怎麼樣? 可能有一些方法可以衡量有關這些實體的信息的置信度及其正確性。

如專利中的這些圖像所示,谷歌計算實體和連接屬性之間的關聯分數(更多關於關聯分數的信息如下)。
我在帖子中寫過類似的內容:Google 的知識圖譜如何通過回答問題來更新自身。 該帖子的重點是 Google 如何更新現有的知識圖譜,而不是在網頁上查找有關實體的信息,並識別它們,以及它們如何與其他類別的實體連接。 依賴知識庫而不是將 Web 視為大型數據庫似乎是一個部分步驟。 如果有可能以一種智能且有用的方式執行實體提取,那麼依賴於 Web 上的人工審核的百科全書就沒有必要了。 在過去的一些地方,谷歌曾表示他們更喜歡通過網絡可擴展的方法來組織網絡上的信息(比如當他們停止使用來自人們的來源的谷歌目錄時。)
最近的這項專利公開了一種不同的方法,可以幫助谷歌從添加到 Web 的源中提取實體以及有關這些實體的其他信息,而不是添加到 Web 上的知識庫,包括新的網頁和新聞源。
該專利在其描述中有一個摘要部分,它告訴我們它保護的過程。 它用幾句話總結了這些:
所公開的實施例可以提供用於確定新實體的類別和屬性以及反映所確定的關係中的相關度和置信度水平的關聯分數的系統和方法。 所公開的實施例可以基於新實體出現的周圍詞彙上下文和鄰近每個新實體的已知實體來確定這些類別、屬性和相關分數。 所公開的實施例的方面還提供用於實時或接近實時地動態更新和存儲確定的關係的系統和方法。
它通過讓我們逐步了解其稱為“識別實體候選者”的過程,對這些內容進行了更詳細的擴展。
識別實體提取的候選實體
- 實體候選位於可通過網絡訪問的文檔中。
- 檢測到的候選實體是基於存儲在數據庫中的一個或多個實體模型的新實體。
- 一個已知實體緊挨著新實體,並且該已知實體在一個或多個實體模型中。
- 新實體和已知實體旁邊的上下文與已知實體具有詞彙關係。
- 與已知實體相關聯的第二實體類和上下文類也與上下文相關聯。
- 第一實體類基於第二實體類和上下文類與新實體連接。
- 數據庫中的第一條目取決於實體模型中的至少一個,該條目反映第一實體類和新實體之間的關聯。
這些實體候選人所擁有的專利是關於實體提取和存儲有關這些實體的信息的專利:
用於提取和存儲有關實體的信息的計算機化系統和方法
發明人:Christopher Semturs、Lode Vandevenne、Danila Sinopalnikov、Alexander Lyashuk、Sebastian Steiger、Henrik Grimm、Nathanael Martin Scharli 和 David Lecomte
受讓人:GOOGLE LLC
美國專利:10,198,491
授予時間:2019 年 2 月 5 日
提交時間:2015 年 7 月 6 日
抽象的
提供了用於從諸如網頁的文檔中提取和存儲關於實體的信息的計算機實現的系統和方法。 在一個實現中,提供了一種系統,其檢測文檔中的實體候選並且確定檢測到的候選是新實體。 該系統還基於一個或多個實體模型檢測與已知實體接近的已知實體。 該系統還檢測與與已知實體具有詞彙關係的新的和已知的實體接近的上下文。 系統還確定與已知實體相關聯的第二實體類和與上下文相關聯的上下文類。 系統還基於第二實體類和上下文類生成第一實體類。 系統還在一個或多個實體模型中生成條目,反映新實體和第一實體之間的關聯。
實體提取——實體、實體類、實體實例和實體屬性
該專利所涉及的過程的第一步是識別實體。 該專利提供了一些關於實體是什麼的信息,並為我們提供了幾個例子:
在某些方面,實體可以反映人(例如喬治華盛頓)、地點(例如舊金山、懷俄明州、特定街道或十字路口等)或事物(例如明星、汽車、政治家、醫生、設備、體育場、人、書)。 再舉個例子,一個實體可以反映一篇文獻、一個組織(例如紐約洋基隊)、一個政治團體或政黨、一個企業、一個主權或政府機構(例如,美國、北約、FDA等)、日期(例如,1776 年 7 月 4 日)、數字(例如,60、3.14159、e)、字母、狀態、質量、想法、概念或其任意組合。
在實體的這些定義之上,我們還被告知實體類和子類,以及實體如何適合不同的類和子類。 這很重要,因為搜索引擎會在了解實體時嘗試將實體放入不同的類中。
那麼什麼是實體類或子類?
該專利深入描述了這些:
在一些方面,實體可以與實體類相關聯。 實體類可以表示實體的組或概念模型的分類、類型或分類。 例如,出於說明的目的,實體類可以包括“人”、“星系”、“棒球運動員”、“樹”、“道路”、“政治家”等。一個實體類可以與一個或多個子類相關聯. 在一些方面,子類可以反映包含在更大類(例如,“超類”)中的實體類。 例如,在上面的示例類列表中,“棒球運動員”和“政治家”類可能是“人”類的子類,因為所有棒球運動員和政治家都是人類。 在其他實施例中,子類可以表示幾乎完全但不完全是更大超類的一部分的實體類。 在包含異常值或虛構實體的情況下可能會出現這種安排。 例如,“政治家”類可能是“人”類的子類,即使某些虛構實體是非人類政治家(例如,“Mas Amedda”)。 公開的實施例提供處理和管理這些種類的關係的方式,如下文進一步描述的。 類和子類都可以表示實體類並且可以構成實體本身。
數據實例是適合類或子類的特定實體的示例。 托馬斯杰斐遜是“美國總統”的一個例子,而“邁克特勞特”是“職業棒球運動員”的一個具體例子。
該專利致力於收集有關實體的信息,並收集有關其稱為“實體屬性”的實體的信息。 正如專利中的這張圖所示:

這些可以包括實體的屬性以及實體類之間的關係。 該專利還深入了解了屬性可能是什麼:
實體可以與一個或多個實體屬性和/或對象屬性相關聯。 實體屬性在某些方面可以反映實體類的屬性、特徵、特徵、質量或元素。 在某些方面,實體類的每個或基本上每個實例都將共享一組公共實體屬性。 例如,實體“人”可以與實體屬性“出生日期”、“出生地”、“父母”、“性別”或一般來說“具有屬性”等相關聯。 在另一個示例中,實體“專業運動隊”可以與諸如“位置”、“年收入”、“名冊”等實體屬性相關聯。 在其他實施例中,實體屬性可以描述一個實體如何與另一個實體相關。 例如,實體屬性可以描述實體類之間的關係,例如“是一個”、“是...的子類”或“是...的超類”或“包含”。 例如,類“star”可能與實體類“天體”的實體屬性“是其子類”相關聯。
當談到實體提取時,我們最終會看到鍵值對用於告訴我們更多關於特定實體的信息:
在某些方面,對象屬性可以反映實體類實例與特定屬性值之間的關係。 例如,實體“George Washington”可能與值為“Feb”的對象屬性“hasbirthdate”相關聯。 22 日,1732 年。” 在一些實施例中,對象屬性的值本身可以反映實體。 例如,在上面的示例中,日期“Feb. 22, 1732” 可能反映一個實體。
這種收集實體信息的方法包括在子類中可能常見的屬性,這些屬性存在於:
在一些實施例中,實體和子類從它們派生自的超類繼承屬性。 例如,“美國總統”類可以從“人”超類繼承屬性“生日”。 此外,在某些實施例中,超類可能不一定繼承其子類的屬性。 舉例來說,“人”類不一定繼承子類“職業棒球運動員”的屬性“被盜基地”,或子類“美國總統”的屬性“就任日期”。
上下文數據庫和實體提取
我從我過去看到的一些模式中認出了“上下文”。 有一個是待定的 Schema 詞彙表,使用術語“了解”,您可以用它來描述在特定職業中行事的人具有某種類型的經驗。 這些上下文術語是相似的,因為它們有助於提供有關實體的更多信息,這些實體為您提供有關它們的信息。 專利中關於上下文數據庫的段落確實很好地描述了它們:
在一些實施例中,上下文數據庫可以存儲、關聯、管理和/或提供與一個或多個上下文相關聯的信息。 上下文可以反映一個或多個詞(例如,詞、短語、從句、句子、段落等)的詞彙構造或表示,賦予其鄰近的一個或多個詞(例如,實體)含義。 在某些實施例中,上下文在 n-gram 中。 一個 n-gram 可以反映一個由 n 個單詞組成的序列,其中 n 是一個正整數。 例如,上下文可以包括 1-gram,例如“is”、“was”或“concurreBesidestion,示例性上下文可以包括 3-gram,例如“出生於”、“結婚於”、“偷了二壘”或“寫了異議”。 上下文(和 n-gram)還可以包括任何長度的間隙,例如 2-gram “from . . . 直到 。 . . 。” 如這裡所描述的,一個n-gram可以表示任何這樣的序列,並且兩個n-gram不需要表示單詞的名稱數量。 例如,“scored a goal”和“in the last minute”可能都構成 n-gram,儘管包含不同數量的單詞。
學習實體和上下文是學習有意義的詞彙的問題,因為這樣做有助於了解該專利背後的過程如何運作,以及谷歌如何參與數據挖掘以提取有關實體、它們的屬性的信息,和屬性,以及我們看到它們的上下文。上下文比幫助為實體提供上下文的短 n-gram 更複雜。 該專利的下一部分告訴我們上下文類和上下文實體:
在某些實施例中,上下文可以指示一個或多個實體的潛在存在。 由上下文指定的一個或多個潛在實體在本文中可稱為“上下文類”或“上下文實體”。 然而,這些名稱僅用於說明目的,因為它們不旨在進行限制。 上下文類可以反映通常與上下文相關聯(例如,具有詞彙關係)產生的一組類。 在某些方面,“上下文類”可以反映特定的實體類。 例如,上下文“結婚”可能與實體“人”的上下文類別相關聯,因為上下文“結婚”通常與人類具有詞彙關係(例如,與實例具有詞彙關係)的“人”類)。 例如,在此示例中,句子“Jack 與 Jill 結婚”表示“Jack”和“Jill”都屬於“person”類,至少部分是由於上下文的上下文類“結婚了。” 在另一個示例中,上下文“有一隻寵物”可以與諸如“動物”、“貓”、“狗”、“家養動物”等的上下文類別相關聯。 此外,在這個替代示例中,上下文“has a pet”可能表示存在不共同擴展的實體類,因為同一類的兩個實例通常不共享詞法關係(例如,寵物-主人屬性關係) . 下面更詳細地解釋上下文類的解釋和生成。
涉及實體提取的關聯分數
該專利更詳細地介紹了上下文類和上下文實體,這些內容值得更詳細地研究。 但是該專利中值得學習的部分涉及到實體提取期間關聯分數的計算:
在一些方面,實體數據庫和/或上下文數據庫還可以存儲與一個或多個關聯分數有關的信息。 關聯分數可反映屬性、屬性值、關係、類層次、指定的上下文類或其他此類關聯有效、正確和/或合法的可能性或置信度。 例如,在一些實施例中,關聯分數可以反映兩個實體或上下文與實體之間的相關程度。 關聯分數可以通過與所公開的實施例一致的任何過程來確定。 例如,如下文更詳細解釋的,計算系統(例如,服務器)可以使用因素和權重來確定關聯分數,例如生成關聯分數的來源的可靠性、之間的共同出現的頻率或數量。內容中的兩個實體(例如,作為總出現次數的函數,包含一個或兩個實體的文檔總數等),實體本身的屬性(例如,一個實體是否是另一個實體的子類),新近度已發現的關係的數量(例如,通過對較新或更舊的關聯給予更多權重),屬性是否具有已知的波動傾向(例如,週期性或零星的),實體類之間的相對實例數,實體的受歡迎程度作為被分析文檔中的兩個實體之間的一對、平均值、中值、統計和/或加權接近度,和/或本文公開的任何其他過程。 在一些方面,系統本身可以生成一個或多個關聯分數。 在某些方面,系統可以基於預先生成的數據結構(例如,存儲在數據庫140和/或150中)預先加載一個或多個關聯分數。
有趣的是,諸如來源可靠性之類的因素可能會在分配給實體或上下文與實體之間的關係的關聯分數中發揮作用。 下一節著眼於他們所謂的“上下文和實體之間的共現比率”:
例如,在一個實施例中,計算系統(例如,服務器)可以通過確定上下文和實體(例如,特定實體、實體類等)到網絡文檔中所有出現的上下文和/或實體。 例如,一個說明性的表達式可以採用 A=P(E, C)/P(C) 的形式,其中 A 是實體和上下文之間的示例關聯值,P(C) 是找到上下文的概率在一段文本(例如,一個文檔、一個或多個網頁、一個語料庫等)中,P(E, C) 是找到這兩個上下文實體在該段中共同出現的概率。 在這個例子中,關聯分數可以反映當上下文C出現時找到實體E的條件概率。 關聯分數的另一個說明性表達式可以採用 A=N(E, C)/(N(E)+N(C)-N(E, C)) 的形式,其中 N(E) 是實例數實體出現在某個部分(例如,語料庫)中,N(C) 是上下文出現在該部分的實例數,N(E, C) 是實體 E 和上下文 C 一起出現的實例數在該部分。 類似的表達式可用於生成兩個實體之間的關聯分數。
這個特定實體類和上下文的例子清楚地說明了關聯分數如何幫助理解這些分數如何有用:
舉例來說,服務器可以確定上下文“接收傳球”與實體類“籃球運動員”和“人”的實例在 35% 和 97% 的時間出現在所有分析的文檔中,分別。 系統可以通過至少部分地使用實體和上下文模型來確定實體之間的關係(例如,確定“勒布朗詹姆斯”是“籃球運動員”類的實例)來確定這些共現頻率。 在該示例中,服務器可以確定將上下文“接收傳球”與“籃球運動員”和“人”相關聯的關聯分數分別為0.35和0.97。
請注意,這些共現來自於一個文檔語料庫,而不是一個。
我們還有其他一些可能影響關聯分數計算的其他因素的示例:
關聯分數可以通過為實體或上下文的每次出現合併一個或多個權重來考慮其他考慮因素。 在一些方面,計算系統可以應用權重來說明諸如時間權重(例如,更重地權衡最近的文檔或事件)、可靠性權重(例如,更重地權衡更可靠的來源)、流行權重(例如,更重要的權重)、鄰近權重(例如,更重地權衡彼此更接近地發生的實體/上下文)和與所公開的實施例一致的任何其他類型的權重。 在某些方面,權重可以反映特定文檔或個別事件與其他事件相比的相對重要性(例如,所有事件的權重總和為 1.0)、文檔或事件在絕對尺度上的重要性(例如,每個權重反映了一個獨立的評級),或任何其他表明兩個實體或上下文之間的相關性(例如,上下文和實體之間的接近度)的度量。

低關聯分數意味著什麼?
因此,在一些實施例中,低關聯分數可以指示關係所基於的數據源通常不可信或不可靠。 在其他實施例中,低關聯分數可以指示主題對的共現未出現在最近的文檔中。 在其他實施例中,低關聯分數可以指示這對之間的共同出現是罕見的(例如,很少有“政治家”是“職業籃球運動員”)。 在其他實施例中,關聯分數可以反映許多這樣的因素的組合。 在一些方面,系統(例如,與數據庫相關的服務器或計算系統)可以隨時間更新和修改關聯分數(例如,基於新的文檔、上下文和屬性)。
關聯分數讓我們了解可能性:
關聯分數可以採用數字形式(例如,0.0 到 1.0、0 到 100 等)、定性尺度(例如,不太可能、很可能、非常可能)、顏色編碼尺度和/或任何能夠指定程度級別的其他度量或評級方案。 例如,在一個實施例中,實體數據庫可以存儲 0.84 的關聯分數,反映實體“Bryce Harper”與具有值“Oct. 1992 年 16 月。” 例如,這可能表明系統認為布萊斯哈珀的生日是 1992 年 10 月 16 日,準確率為 84%。 此外,“Bryce Harper”可能通過屬性或關係“is a”與實體類“person”相關聯,關聯分數為 1.0,表明 Bryce Harper 是一個人的確定性。 在另一示例中,上下文“得分目標”可以分別與關聯分數為0.64、0.49和0.98的上下文類別“足球運動員”、“曲棍球運動員”和“人”相關聯。 例如,這些示例性值可以指示上下文更有可能涉及足球運動員而不是曲棍球運動員,並且更可能的是該句子通常涉及一個或多個人而不是特別是足球運動員。 如上所述,一個或多個實體數據庫(例如,實體數據庫)和上下文數據庫(例如,上下文數據庫)、服務器和/或客戶端設備可以存儲、生成、確定、存檔和索引實體、屬性、上下文、上下文類別、關聯分數以及與所公開的實施例一致的任何形式的任何其他信息。
實體提取過程中具有關聯分數的知識圖譜
該專利描述了一個示例知識圖,每個邊都包含關聯分數,將實體連接到屬性或值:
在一些方面,知識圖可以包括多個節點,每個節點反映一個實體。 知識圖還可以包括一個或多個反映描述實體和特定屬性值之間關係的屬性的邊。 在某些實施例中,知識圖還可以包括其中包含的每個邊(例如,每個屬性或關聯值)的關聯分數,儘管這樣的關聯分數不是必需的。 在圖 1 中描繪的說明性知識圖中。 例如,在圖 2A 中,反映特定實體的實體節點“Bryce Harper”通過關聯分數為 0.96 的對象屬性“plays for”連接到另一個實體“Washington Nationals”。 例如,這些值和關係可能表明布萊斯·哈珀是華盛頓國民隊的球員,並且系統將此屬性與 0.96 的置信度相關聯。 實體“華盛頓國民”本身可能與其他未顯示的實體相關聯,由從節點發出的散列線表示。 其他實體在圖 3 和圖 5 中描繪。 圖2A-2C和3可以類似地與未示出的其他節點和屬性相關聯,並且其中某些關係和值的描述僅是說明性的。
關聯分數可以提供對與實體相關的事實的正確性的信心感。 另一組與布萊斯·哈珀相關的例子:
如圖。 圖 2A 還描繪了將節點“Bryce Harper”與日期實體節點“Oct. 16, 1992”和價值實體節點“60 Home Runs”分別通過屬性“has abirth”和“has職業人力資源總數”。 這些屬性的關聯分數分別為 0.84 和 0.37,表明系統對與屬性關係“hasbirthdate”相關聯的值比與“has business HR total”相關聯的值更有信心。 例如,由於用於生成此類關係的源的可靠性、實體之間共現的頻率、屬性值之一(節點 204)是與所公開的實施例一致,隨時間和/或其他因素而變化。
對涵蓋許多不同類型的巨大知識圖進行圖像化,每個知識圖都有許多與之相關的屬性或屬性,以及提供實體與類和子類之間置信度的關聯分數。 該專利向我們表明,這很可能:
實體節點還可以與實體類和子類相關聯,通過描述實體和實體類之間關係性質的屬性連接。 例如,圖。 圖 2A 描繪了節點“布萊斯哈珀”與實體類“人”和“職業棒球運動員”之間通過各自的邊“是一個”和“有一個職業”的連接。 這些屬性的關聯分數分別為 1.0 和 0.99。 說明性的屬性和關聯分數表明系統將布萊斯·哈珀確定為職業棒球運動員。
我們還從實體類和其他實體類的低關聯分數中學習:
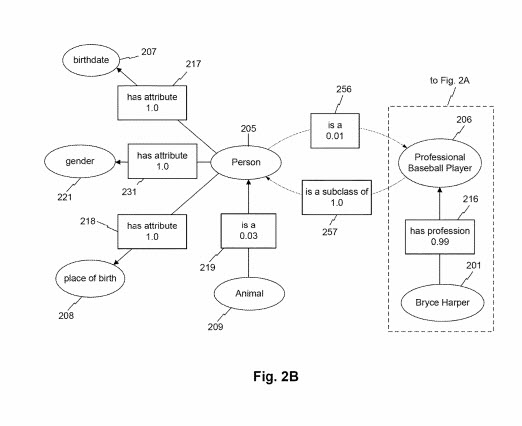
如圖所示。 如圖2B所示,一個實體類也可以通過實體屬性與其他實體類相關聯。 例如,“animal”類可以通過屬性“is a”與“person”類相關聯。 本例中,該屬性對應的關聯分數為0.03。 例如,這可能表明“動物”類 209 的實例是“人”類的罕見實例(例如,由於其他哺乳動物、昆蟲、鳥類、魚類等非人類動物的普遍存在)。 雖然沒有在圖 1 中描繪。 參照圖2B,與“動物”節點相關聯,“人”類可以與相互屬性“是一個”或“是...的子類”等相關聯。 這樣的屬性可以與更高的關聯分數(例如,0.94)相關聯,表明類“人”是“動物”的子類。 例如,圖。 圖2B描繪了類“職業棒球運動員”與具有實體屬性“是……的子類”的類“人”相關聯,關聯分數為1.0。 相比之下,類節點“person”可以通過屬性“is a”與節點“職業棒球運動員”相關聯,關聯分數為0.01。 例如,該較低的關聯分數可以反映不屬於“職業棒球運動員”類的“人”類實體的強烈流行(例如,大多數人不是職業棒球運動員)。 如圖。 圖2B進一步描繪了職業棒球運動員等級節點如何經由屬性“具有職業”與實體節點“布萊斯哈珀”相關聯,如結合圖2所討論的。 2A。
上下文圖中的實體類型和上下文類之間的關聯可以告訴我們有關這些實體類型和上下文的特定信息:
在一些實施例中,上下文圖中包括的實體類可以表示與特定上下文(例如,上下文)相關聯的上下文類。 在這樣的實施例中,將上下文鏈接到它們的上下文類(和任何包括的子類等)的關聯分數可以反映上下文類和上下文(例如,邊緣)之間的有效性或相關性的程度和/或相關性的程度實體類本身之間(例如,邊緣)。 在一些方面,關聯分數因此可以反映上下文表示相關上下文類或該上下文類的實例的存在的可能性。 例如,如圖所示。 在圖2D中,上下文節點“接收傳自”可以與五個上下文類相關聯。 在此示例中,上下文“接收傳球”與上下文類別“人”、“棒球運動員”、“籃球運動員”、“曲棍球運動員”和“足球運動員”相關聯。這些關聯中的每一個都可以包括相應的關聯分數,例如分數。 這些關聯分數用伴隨的短語“takes class”來說明,以指示上下文指示特定類或類實例存在的可能性或概率。
例如,因為“棒球運動員”類的成員很少會“從(上下文)接收到”另一名球員的傳球,因此與此上下文類相關聯的關聯分數為 0.02,如行項所示. 如上所述,該值可以從上下文和“棒球運動員”類的實例在網絡源上的共現頻率、這些源的可靠性等中生成。相比之下,上下文和其餘實體類相對較高。 For example, the association scores for the context classes “hockey player,” “soccer player,” and “person” are 0.47, 0.62, and 0.97, respectively. These values may indicate that, in a vacuum, the context is more likely to refer to a soccer player than a hockey player, but it most likely to refer to an entity of the class “person” (eg, as opposed to a court, agency, or organization, etc.).
As the search engine visits pages on the Web, and Performs entity extractions, and learns about entities, entity classes, and specific instances of those classes, and the contexts in which they appear, and calculates association scores, it may continue to crawl pages and add to the entity information it knows about as it engages in entity extraction and storing information about entities.
The patent tells us about entity extractions being an ongoing process:
Systems and methods consistent with some embodiments may identify entities from documents, assign entity classes to them, and associate them with properties. The assigned classes and attributes may be based, at least in part, on the context in which the new entity appears, the entity classes of entities proximate to the new entity, relationships between entity classes, association scores, and other factors. Once assigned, these classes and attributes may be updated in real-time as the system traverses additional documents and materials. The disclosed embodiments may then permit access to these entity and context models via search engines, improving the accuracy, efficiency, and relevance of search engines and/or searching routines.
Parsing Documents for Entity Extractions and Storing Information About Entities
The process behind the search engines going through pages and finding entities and learning more about them:
When the process finishes searching for new entity candidates, the system may determine whether any new entity candidates have been identified (step 410). If not, the process may end or otherwise continue to conduct processes consistent with the disclosed embodiments (step 412). If the system has found one or more new entity candidates, the process may determine whether the new entity candidate is a new entity using processes consistent with those disclosed herein. If so, the process may include determining one or more entity classes and/or attributes of the new entity (step 414). This procedure may take the form of any process consistent with the disclosed embodiments (see, eg, the embodiment described in connection with FIG. 6). This step may also include generating or determining one or more association scores corresponding to the identified classes and attributes in some embodiments. For example, the system may determine that a new entity “John Doe” is likely an instance of a class “professor,” (which may be in turn a subclass of the classes “teacher” or “person,” etc.,) and has a birthdate “Sep. 28, 1972.” Further, the process may include generating association scores representing the degree of certainty the system associates with these relationships.
As the search engine collects this information about entities it finds, it may store that information as data in a knowledge graph “with nodes and edges reflecting the new entity, its classes, attributes, and corresponding association scores, etc.”
The Entity Extractions and Entity Information Storage Process
The patent does describe how it might take prose text on pages. It does this to look for entities, context, classes, properties, and attributes and calculate association scores. It stores these in a knowledge graph where the entities and facts about them are the edges. The contexts between those are the edges.
This is what a knowledge graph is.
The patent stressed that it would try to update the knowledge graph dynamically, and in real or near real-time. That would be the ideal benefit of the entity extractions process described in this patent. This would be entity-first indexing of the Web.
Last Updated September 21, 2019