
Che cos'è la pulizia dei dati?
Pubblicato: 2021-11-18Le aziende molto tempo fa avevano già riconosciuto l'importanza dei dati quando si tratta di comprendere i propri clienti e prendere decisioni strategiche per aumentare il ROI.
Tuttavia, nella corsa per portare prodotti e soluzioni personalizzati, i fatti cruciali sulla qualità dei dati vengono messi da parte, il che porta a inferenze analitiche errate e decisioni aziendali costose.
Gartner afferma: "L'impatto finanziario medio di una scarsa qualità dei dati sulle organizzazioni è di 9,7 milioni di dollari all'anno". È possibile migliorare la qualità dei dati garantendo punti di immissione dati accurati, un'efficace fusione dei dati, standardizzazione dei dati e metodi di pulizia dei dati.
L'applicazione pratica delle tecniche di pulizia e arricchimento dei dati può aiutare a creare, convalidare, aggiornare, migliorare e migliorare i dati business-critical sviluppando strumenti personalizzati (spider, bot e script) e processi manuali.
Ecco alcune implicazioni di dati errati:
- Ovum Research segnala che la scarsa qualità dei dati costa alle aziende almeno il 30% delle loro entrate.
- Dati di vendita errati spingono i venditori a perdere tempo con lead morti. Dati imprecisi possono indirizzare l'azienda verso strategie distorte.
- MarketingSherpa afferma che ogni anno il 25-30% dei dati viene danneggiato. Dati errati possono fornire informazioni distorte sui dati demografici dei clienti e sui comportamenti di acquisto, il che porterebbe a opportunità perse per gli esperti di marketing.
- La mancata comunicazione è un enorme ostacolo per i clienti. Dati errati possono contribuire a problemi di comunicazione con i clienti, un senso di insoddisfazione tra di loro e persino un marchio negativo sui social media.
Che cos'è la pulizia dei dati?
La pulizia dei dati o la pulizia dei dati è un metodo per individuare e correggere record sviliti o imprecisi da un recordset, una tabella o un database. Si riferisce al rilevamento di parti frammentarie, errate, imprecise o non correlate dei dati e quindi alla sostituzione, alla modifica o alla rimozione dei dati sporchi o approssimativi.
La pulizia dei dati può essere eseguita in modo interattivo con soluzioni di data wrangling o come elaborazione batch tramite script. Dopo la sanificazione, un set di dati dovrebbe essere coerente con altri set di dati simili nel sistema.
Le discrepanze rilevate o rimosse potrebbero essere state inizialmente causate da imprecisioni di immissione dell'utente, da distorsioni nella trasmissione o nella memorizzazione, o da definizioni dissimili del dizionario dei dati delle stesse entità in negozi diversi.
La pulizia dei dati differisce dall'autenticazione dei dati in quanto la convalida significa quasi invariante che i dati sono esclusi dal sistema al momento dell'ammissione e viene ottenuta al momento dell'immissione, piuttosto che su insiemi di dati.
L'effettiva procedura di pulizia dei dati può comprendere la rimozione di errori tipografici o l'autenticazione e la correzione di valori rispetto a un elenco noto di oggetti. La convalida può essere rigorosa (come il rifiuto di qualsiasi indirizzo che non dispone di un codice postale valido) o sfocata (come la rettifica di record che in qualche misura corrispondono a conti noti e esistenti).
Alcuni strumenti di pulizia dei dati puliranno i dati effettuando un controllo incrociato con un set di dati autenticato. Una pratica tipica di pulizia dei dati è il miglioramento dei dati, in cui i dati vengono completati aggiungendo informazioni correlate, ad esempio aggiungendo posizioni con qualsiasi numero di telefono associato a quell'indirizzo.
La pulizia dei dati può anche comprendere la sincronizzazione (o normalizzazione) dei dati, che è il processo di riunire i dati di "formati di file variabili, nomenclatura e colonne" e cambiarli in un set di dati coeso; un semplice esempio è un'espansione degli acronimi.
Come pulire i dati?
I dati puliti sono alla base di ricerche e approfondimenti significativi. Pertanto, i dirigenti della scienza dei dati trascorrono l'80% del loro tempo nella pulizia e normalizzazione dei dati. La pulizia dei dati segue vari approcci.
Controllo dei dati
Controllare i dati utilizzando metodi statistici e di database per rilevare anomalie e contraddizioni: questo eventualmente indica le caratteristiche delle peculiarità e delle loro località.
Diversi strumenti ti permetteranno di postulare controlli di vario tipo (usando una grammatica che imita una codifica standard come JavaScript o Visual Basic) e quindi generare codice che esamini i dati per la violazione di questi vincoli.
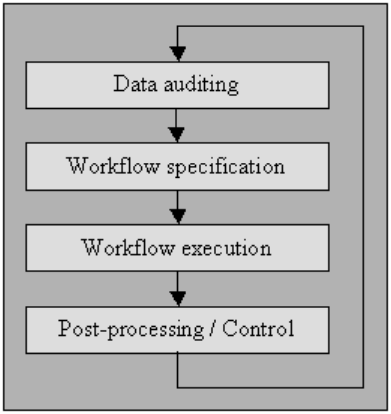
Ho spiegato il processo di seguito in "specifica del flusso di lavoro" e "esecuzione del flusso di lavoro". Per gli utenti che non hanno accesso a strumenti di pulizia di fascia alta, i sistemi di gestione di database di microcomputer come MS Access o File Maker Pro ti consentiranno anche di ottenere tali autorizzazioni limite per limite, in modo interattivo con poca o nessuna programmazione necessaria in molti casi.
Specifica del flusso di lavoro
Disporre di un flusso di lavoro per il rilevamento e la rimozione delle anomalie. Inizia dopo la procedura di verifica dei dati ed è fondamentale per realizzare il prodotto finale di dati di alta qualità. La creazione di un corretto flusso di lavoro richiede un attento monitoraggio delle cause delle anomalie e degli errori nei dati.
Esecuzione del flusso di lavoro
In questa fase, eseguire il flusso di lavoro dopo che i suoi requisiti sono stati completati e la sua accuratezza è stata confermata.
L'applicazione del flusso di lavoro dovrebbe essere ben organizzata, anche su vasti insiemi di dati, il che rappresenta inevitabilmente un compromesso poiché l'esecuzione di un processo di pulizia dei dati può essere computazionalmente costoso.
Post-elaborazione e controllo
Dopo aver completato il flusso di lavoro di pulizia, ispezionare i risultati per verificarne la correttezza. Regola manualmente i dati errati lasciati dopo l'esecuzione del flusso di lavoro, se possibile.
Il risultato è una nuova sequenza nella procedura di pulizia dei dati in cui si controllano nuovamente i dati per consentire la richiesta di un flusso di lavoro aggiuntivo per pulire i dati mediante un'ulteriore elaborazione automatica.
Una migliore qualità dei dati di origine ha a che fare con la "cultura della qualità dei dati" e ogni organizzazione deve avviarla ai vertici della struttura aziendale.
Non si tratta solo di eseguire controlli di convalida sicuri sulle schermate di input, perché quasi non importa quanto siano accurati questi controlli, spesso possono comunque essere aggirati dagli utenti.

Esiste una guida in nove fasi per gli stabilimenti che desiderano migliorare la qualità dei dati:
- Dichiarare una garanzia di alto livello per una cultura della qualità dei dati
- Reingegnerizzazione delle procedure di guida a livello di policymaking
- Spendere l'impasto per far avanzare l'impostazione di immissione dei dati
- Spendi soldi per sviluppare l'integrazione delle applicazioni
- Dedicare denaro per modificare il funzionamento dei processi
- Approva la reattività del team end-to-end
- Incoraggiare la collaborazione interdipartimentale
- Rivelano pubblicamente la superiorità della qualità dei dati
- Misurare e migliorare incessantemente la qualità dei dati
Altri sono costituiti da:
Analisi
per il riconoscimento degli errori di sintassi. Un parser sceglie se una stringa di dati è accettabile all'interno della specifica dei dati consentita. È simile al modo in cui un parser lavora con sintassi e linguaggi.
Trasformazione dei dati
La trasformazione dei dati consente di tracciare i dati dal formato specificato nella disposizione prevista dall'applicazione appropriata. Incorpora conversioni di valore o procedure di traduzione, oltre a standardizzare i valori numerici per seguire i valori minimo e massimo.
Eliminazione duplicati
Il rilevamento dei duplicati richiede un algoritmo per definire se i dati hanno duplicati della stessa entità. Di solito, i dati sono organizzati da una chiave che avvicinerebbe voci identiche per un'identificazione più rapida.
metodi statistici
Esaminando i dati utilizzando i valori di media, deviazione standard, intervallo o procedure di raggruppamento, un esperto può trovare valori imprevisti e quindi errati.
Anche se la correzione di tali dati è ripida poiché non si conosce la denominazione effettiva, tuttavia, è possibile risolverla impostando i valori su una media o su un altro valore statistico.
Un altro uso dei metodi statistici riguarda la gestione dei tagli perduti, che possono essere sostituiti da uno o più valori possibili, che di solito vengono acquisiti da estesi algoritmi di data augmentation.
Igiene dei dati o qualità dei dati
I dati per essere elaborabili ed interpretabili in modo efficace ed efficiente devono soddisfare una serie di criteri di qualità. Si dice che i dati che soddisfano tali criteri di qualità siano di alta qualità. In generale, un valore aggregato su un insieme di criteri di qualità è la qualità dei dati.
Partendo dai criteri di qualità specificati in, descriviamo l'insieme di standard che sono interessati da una pulizia completa dei dati e definiamo come valutare i punteggi per ciascuno di essi per una raccolta di dati esistente.
Per misurare la qualità di una raccolta di dati, valutare le valutazioni per ciascuno dei criteri di qualità.
L'uso della valutazione dei punteggi per i criteri di qualità può essere un modo per quantificare la necessità della pulizia dei dati per la raccolta dei dati, nonché il successo di un processo di pulizia dei dati eseguito su una raccolta di dati.
È possibile utilizzare criteri di qualità nell'ambito dell'ottimizzazione della pulizia dei dati specificando le priorità per ciascuno dei requisiti, che a sua volta influenza l'esecuzione dei metodi di pulizia dei dati che interessano le regole specifiche.
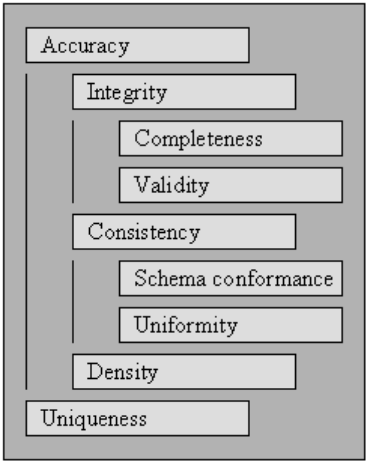
Validità
Il punto in cui i dati si adattano a regole o vincoli aziendali definiti.
- Vincoli del tipo di dati: i valori in una particolare colonna devono essere di un tipo di dati specifico, ad esempio booleano, numerico, data, ecc.
- Vincoli di intervallo: in genere, i numeri o le date devono rientrare in un intervallo specifico.
- Vincoli obbligatori : colonne specifiche non possono essere vuote.
- Vincoli univoci: un campo, o una combinazione di aree, deve essere distintivo in un set di dati.
- Vincoli Set-Membership : le denominazioni di una colonna derivano da un insieme di valori discreti, ad esempio valori enum. Ad esempio, il genere può essere maschile, femminile o altro.
- Vincoli di chiave esterna : come nei sistemi di database relazionali, dovrebbe esistere una colonna di chiave esterna nella chiave primaria di riferimento.
- Modelli di espressioni regolari: i campi di testo devono seguire un design specifico. Ad esempio, i numeri di telefono devono obbedire a un particolare profilo (xxx) xxx-xxx.
- Convalida cross-field: le impostazioni specifiche che si estendono su numerosi campi devono essere valide, ad esempio, la data di dimissione di un paziente dall'ospedale non può essere anteriore all'orario di ricovero.
Precisione
Il grado in cui i dati sono vicini ai valori effettivi. Sebbene la definizione di tutti i possibili valori di campo validi consenta di individuare facilmente i valori non validi, ciò non significa che siano accurati.
Un indirizzo valido potrebbe non esistere. UN il colore degli occhi di una persona, diciamo blu, potrebbe essere corretto, ma non corretto. Un'altra cosa da non dimenticare è la differenza tra correttezza e precisione.
Dire che vivi sul pianeta terra è corretto. Ma non preciso. Dove diavolo? Supponendo che tu viva in un particolare indirizzo stradale è più accurato.
Completezza
Il punto in cui tutti i dati richiesti sono conosciuti e assimilati.
I dati mancheranno per varie cause. Si può mitigare questo problema mettendo in discussione la fonte.
È possibile che otterrai una risposta diversa o sarà difficile da accertare di nuovo.
Consistenza
Il grado in cui i dati sono infallibili, all'interno del set di dati corrispondente o in diversi set di dati simili.
L'incoerenza si verifica quando due valori nel set di dati si contraddicono a vicenda.
Un valido l'età, diciamo 10 anni, potrebbe non corrispondere allo stato civile, diciamo divorziato. La registrazione di un cliente in due tabelle diverse con due indirizzi separati è un'incoerenza.
Quale è vero?
Uniformità
Il grado in cui i dati specificati utilizzano la stessa unità dell'indicatore.
Il peso in libbre o chili, una data nel formato USA o in formato europeo e la valuta a volte in USD o YEN.