
¿Qué es la limpieza de datos?
Publicado: 2021-11-18Hace mucho tiempo, las empresas ya habían reconocido la importancia de los datos cuando se trata de comprender a sus clientes y tomar decisiones estratégicas para aumentar el ROI.
Sin embargo, en la lucha por traer productos y soluciones personalizados, los hechos cruciales sobre la calidad de los datos se dejan de lado, lo que conduce a inferencias analíticas incorrectas y decisiones comerciales costosas.
Gartner dice: "El impacto financiero promedio de la mala calidad de los datos en las organizaciones es de 9,7 millones de dólares al año". Puede mejorar la calidad de los datos al garantizar puntos de entrada de datos precisos, una fusión de datos efectiva, estandarización de datos y métodos de limpieza de datos.
La aplicación práctica de técnicas de limpieza y enriquecimiento de datos puede ayudar a crear, validar, actualizar y mejorar datos críticos para el negocio mediante el desarrollo de herramientas personalizadas (spiders, bots y scripts) y procesos manuales.
Aquí hay algunas implicaciones de los datos incorrectos:
- Ovum Research informa que la mala calidad de los datos cuesta a las empresas al menos el 30 % de sus ingresos.
- Los datos de ventas incorrectos empujan a los vendedores a perder el tiempo con clientes potenciales muertos. Los datos inexactos pueden conducir al negocio hacia estrategias sesgadas.
- MarketingSherpa afirma que cada año el 25-30% de los datos se corrompe. Los datos erróneos pueden brindar información distorsionada sobre la demografía de los clientes y los comportamientos de compra, lo que generaría oportunidades perdidas para los especialistas en marketing.
- La falta de comunicación es un desvío masivo para los clientes. Los datos incorrectos pueden contribuir a la falta de comunicación con los clientes, una sensación de insatisfacción entre ellos e incluso una marca negativa en las redes sociales.
¿Qué es la limpieza de datos?
La limpieza de datos o la limpieza de datos es un método para detectar y rectificar registros degradados o inexactos de un conjunto de registros, una tabla o una base de datos. Se refiere a detectar partes fragmentarias, incorrectas, imprecisas o no relacionadas de los datos y luego sustituir, modificar o eliminar los datos sucios o aproximados.
La limpieza de datos se puede ejecutar de forma interactiva con soluciones de gestión de datos o como procesamiento por lotes mediante secuencias de comandos. Después de la desinfección, un conjunto de datos debe ser coherente con otros conjuntos de datos similares en el sistema.
Las discrepancias detectadas o eliminadas pueden haber sido causadas inicialmente por imprecisiones en la entrada del usuario, por distorsión en la transmisión o el almacenamiento, o por definiciones de diccionario de datos diferentes de las mismas entidades en diferentes almacenes.
La limpieza de datos se diferencia de la autenticación de datos en que la validación casi invariablemente significa que los datos se excluyen del sistema en el momento de la admisión y se logra en el momento de la entrada, en lugar de conjuntos de datos.
El procedimiento real de limpieza de datos puede comprender la eliminación de errores tipográficos o la autenticación y corrección de valores en comparación con una lista conocida de objetos. La validación puede ser estricta (como rechazar cualquier dirección que no tenga un código postal válido) o difusa (como rectificar registros que en alguna medida coinciden con cuentas conocidas existentes).
Algunas herramientas de limpieza de datos limpiarán los datos cotejándolos con un conjunto de datos autenticados. Una práctica típica de limpieza de datos es la mejora de datos, donde los datos se completan agregando información relacionada, por ejemplo, agregando ubicaciones con cualquier número de teléfono asociado con esa dirección.
La limpieza de datos también puede abarcar la sincronización (o normalización) de datos, que es el proceso de reunir datos de "formatos de archivo, nomenclatura y columnas variables" y convertirlos en un conjunto de datos cohesivo; un ejemplo simple es una expansión de siglas.
¿Cómo limpiar datos?
Los datos limpios son la base de importantes investigaciones y conocimientos. Por lo tanto, los ejecutivos de ciencia de datos dedican el 80 % de su tiempo a la limpieza y normalización de datos. La limpieza de datos sigue varios enfoques.
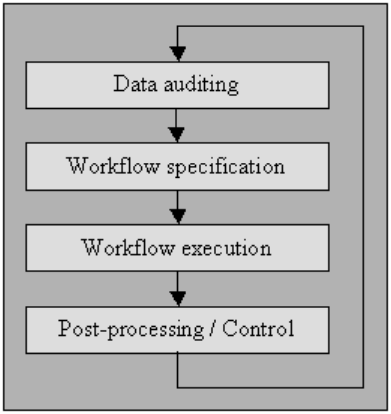
Auditoría de datos
Auditar los datos utilizando métodos estadísticos y de bases de datos para detectar anomalías y contradicciones: esto eventualmente indica las características de las peculiaridades y sus localidades.
Varias herramientas le permitirán postular verificaciones de varios tipos (usando una gramática que imita una codificación estándar como JavaScript o Visual Basic) y luego generar código que examina los datos para detectar el incumplimiento de estas restricciones.
He explicado el proceso a continuación en "especificación de flujo de trabajo", así como en "ejecución de flujo de trabajo". Para los usuarios que no tienen acceso a herramientas de limpieza de alto nivel, los sistemas de administración de bases de datos de microcomputadoras como MS Access o File Maker Pro también les permitirán obtener dichas autorizaciones límite por límite, de forma interactiva con poca o ninguna programación necesaria en muchos casos.
Especificación de flujo de trabajo
Disponer de un flujo de trabajo para la detección y eliminación de anomalías. Comienza después del procedimiento de auditoría de datos y es crucial para lograr el producto final de datos de alta calidad. La creación de un flujo de trabajo adecuado requiere una estrecha supervisión de las causas de las anomalías y errores en los datos.
Ejecución de flujo de trabajo
En esta etapa, ejecute el flujo de trabajo después de que se complete su requisito y se confirme su precisión.
La aplicación del flujo de trabajo debe estar bien organizada, incluso en grandes conjuntos de datos, lo que inevitablemente representa una compensación, ya que llevar a cabo un proceso de limpieza de datos puede ser costoso desde el punto de vista computacional.
Posprocesamiento y control
Después de completar el flujo de trabajo de limpieza, inspeccione los resultados para verificar que sean correctos. Ajuste los datos incorrectos que quedan después de la ejecución del flujo de trabajo manualmente, si es posible.
El resultado es una nueva secuencia en el procedimiento de limpieza de datos en el que vuelve a auditar los datos para permitir el requisito de un flujo de trabajo adicional para limpiar los datos mediante un procesamiento automático adicional.
Una fuente de datos de mejor calidad tiene que ver con la "cultura de calidad de datos", y cada organización debe iniciarla en la parte superior del establecimiento comercial.
No se trata solo de ejecutar verificaciones de validación seguras en las pantallas de entrada, porque casi sin importar qué tan cuidadosas sean estas verificaciones, a menudo los usuarios aún pueden pasarlas por alto.

Hay una guía de nueve pasos para los establecimientos que deseen mejorar la calidad de los datos:
- Declarar una garantía de alto nivel a una cultura de calidad de datos
- Impulsar la reingeniería de procedimientos a nivel de formulación de políticas
- Gastar dinero para avanzar en la configuración de entrada de datos
- Gastar dinero para desarrollar la integración de aplicaciones
- Dedicar dinero para modificar el funcionamiento de los procesos
- Respaldar la capacidad de respuesta del equipo de extremo a extremo
- Fomentar la colaboración interdepartamental
- Revelar públicamente la superioridad de la calidad de los datos
- Medir y mejorar incesantemente la calidad de los datos
Otros consisten en:
análisis
para el reconocimiento de errores de sintaxis. Un analizador elige si una cadena de datos es aceptable dentro de la especificación de datos permitida. Es similar a la forma en que un analizador trabaja con sintaxis y lenguajes.
Transformación de datos
La transformación de datos permite trazar los datos de su formato dado en el arreglo esperado por la aplicación adecuada. Incorpora conversiones de valores o procedimientos de traducción, así como la estandarización de valores numéricos para seguir los valores mínimos y máximos.
Eliminación de duplicados
La detección de duplicados necesita un algoritmo para definir si los datos tienen duplicados de la misma entidad. Por lo general, los datos se organizan mediante una clave que acercaría las entradas idénticas para una identificación más rápida.
métodos de estadística
Al examinar los datos utilizando los valores de la media, la desviación estándar, el rango o los procedimientos de agrupación, un experto puede encontrar valores imprevistos y, por lo tanto, incorrectos.
Aunque la corrección de dichos datos es pronunciada ya que no se conoce la denominación real, puede resolverla configurando los valores en un promedio u otro valor estadístico.
Otro uso de los métodos estadísticos tiene que ver con el manejo de las denominaciones perdidas, que pueden sustituirse por uno o más valores posibles, que generalmente se adquieren mediante extensos algoritmos de aumento de datos.
Higiene de datos o Calidad de datos
Para que los datos sean procesables e interpretables de manera efectiva y eficiente, deben satisfacer un conjunto de criterios de calidad. Se dice que los datos que cumplen esos criterios de calidad son de alta calidad. En general, un valor agregado sobre un conjunto de criterios de calidad es la calidad de los datos.
Comenzando con los criterios de calidad especificados en, describimos el conjunto de estándares que se ven afectados por la limpieza integral de datos y definimos cómo evaluar las puntuaciones de cada uno de ellos para una recopilación de datos existente.
Para medir la calidad de una recopilación de datos, evalúe las calificaciones de cada uno de los criterios de calidad.
El uso de la evaluación de puntajes para los criterios de calidad puede ser una forma de cuantificar la necesidad de la limpieza de datos para la recopilación de datos, así como el éxito de un proceso de limpieza de datos realizado en una recopilación de datos.
Puede utilizar criterios de calidad dentro de la optimización de la limpieza de datos especificando prioridades para cada uno de los requisitos, lo que a su vez influye en la ejecución de los métodos de limpieza de datos que afectan las reglas específicas.
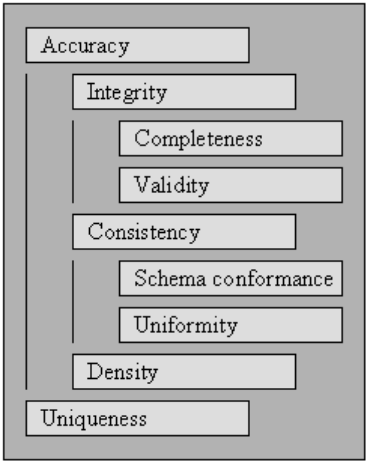
Validez
El punto en el que los datos se ajustan a las reglas o restricciones comerciales definidas.
- Restricciones de tipo de datos: los valores en una columna en particular deben ser de un tipo de datos específico, por ejemplo, booleano, numérico, fecha, etcétera.
- Restricciones de rango: por lo general, los números o las fechas deben estar dentro de un rango específico.
- Restricciones obligatorias : las columnas específicas no pueden estar en blanco.
- Restricciones únicas: un campo, o una combinación de áreas, debe ser distintivo en un conjunto de datos.
- Restricciones de pertenencia a conjuntos : las denominaciones de una columna emanan de un conjunto de valores discretos, por ejemplo, valores de enumeración. Por ejemplo, el género puede ser masculino, femenino u otros.
- Restricciones de clave externa : como en los sistemas de bases de datos relacionales, debe existir una columna de clave externa en la clave principal referenciada.
- Patrones de expresiones regulares: los campos de texto deben seguir un diseño específico. Por ejemplo, los números de teléfono deben obedecer a un perfil particular (xxx) xxx-xxx.
- Validación de campos cruzados: se deben mantener configuraciones específicas que abarcan numerosos campos, por ejemplo, la fecha de alta del paciente del hospital no puede ser anterior a la hora de ingreso.
Precisión
El grado en que los datos se acercan a los valores reales. Si bien esbozar todos los valores de campo válidos posibles permite detectar fácilmente los valores no válidos, no significa que sean precisos.
Es posible que no exista una dirección postal válida . A el color de ojos de la persona, digamos azul, puede ser correcto, pero no correcto. Otra cosa que no hay que olvidar es la diferencia entre corrección y precisión.
Decir que vives en el planeta tierra es correcto. Pero, no preciso. ¿Dónde en el planeta? Asumir que vives en una calle en particular es más exacto.
Lo completo
El punto hasta el cual todos los datos requeridos son conocidos y asimilados.
Faltarán datos por varias causas. Uno puede mitigar este problema cuestionando la fuente.
Lo más probable es que obtenga una respuesta diferente o que sea difícil volver a determinarla.
Consistencia
El grado en que los datos no fallan, dentro del conjunto de datos coincidentes o entre varios conjuntos de datos similares.
La inconsistencia ocurre cuando dos valores en el conjunto de datos se contradicen entre sí.
Un válido la edad, digamos 10, podría no coincidir con el estado civil, digamos divorciado. Registrar un cliente en dos tablas diferentes con dos direcciones separadas es una inconsistencia.
¿Cual es verdadero?
Uniformidad
El grado en que los datos especificados están utilizando la misma unidad del indicador.
El peso en libras o kilos, una fecha en formato USA o formato europeo, y la moneda a veces en USD o YEN.