
Что такое очистка данных?
Опубликовано: 2021-11-18Компании уже давно осознали важность данных, когда речь идет о понимании их клиентов и принятии стратегических решений для повышения рентабельности инвестиций.
Однако в стремлении создать индивидуальные продукты и решения важные факты о качестве данных остаются в стороне, что приводит к неверным аналитическим выводам и дорогостоящим бизнес-решениям.
По данным Gartner, «среднее финансовое воздействие низкого качества данных на организации составляет 9,7 млн долларов в год». Вы можете улучшить качество данных, обеспечив точные точки ввода данных, эффективное объединение данных, стандартизацию данных и методы очистки данных.
Практическое применение методов очистки и обогащения данных может помочь в создании, проверке, обновлении, улучшении и улучшении критически важных для бизнеса данных путем разработки пользовательских инструментов (пауков, ботов и сценариев) и ручных процессов.
Вот некоторые последствия неверных данных:
- Ovum Research сообщает, что низкое качество данных обходится предприятиям как минимум в 30% их доходов.
- Неверные данные о продажах заставляют продавцов тратить время на мертвых лидов. Неточные данные могут подтолкнуть бизнес к искаженным стратегиям.
- MarketingSherpa утверждает, что каждый год 25-30% данных портятся. Неверные данные могут дать искаженную информацию о демографических характеристиках клиентов и покупательском поведении, что приведет к упущенным возможностям для маркетологов.
- Мисс-коммуникация является массовым отторжением клиентов. Неверные данные могут способствовать недопониманию клиентов, возникновению у них чувства неудовлетворенности и даже негативному брендингу в социальных сетях.
Что такое очистка данных?
Очистка данных или очистка данных — это метод обнаружения и исправления испорченных или неточных записей в наборе записей, таблице или базе данных. Это относится к обнаружению фрагментарных, неверных, неточных или несвязанных частей данных с последующей заменой, изменением или удалением грязных или неточных данных.
Очистка данных может выполняться в интерактивном режиме с помощью решений для обработки данных или в виде пакетной обработки с помощью сценариев. После очистки набор данных должен быть согласован с другими аналогичными наборами данных в системе.
Обнаруженные или устраненные несоответствия могут быть первоначально вызваны неточностями ввода данных пользователем, искажениями при передаче или хранении или неодинаковыми определениями словарей данных одних и тех же объектов в разных хранилищах.
Очистка данных отличается от аутентификации данных тем, что проверка почти всегда означает, что данные исключаются из системы при поступлении и достигаются во время ввода, а не для наборов данных.
Фактическая процедура очистки данных может включать удаление типографских ошибок или аутентификацию и исправление значений по сравнению с известным списком объектов. Проверка может быть строгой (например, отклонение любого адреса, не имеющего действительного почтового индекса) или нечеткой (например, исправление записей, которые в некоторой степени соответствуют существующим известным учетным записям).
Некоторые инструменты очистки данных будут очищать данные путем перекрестной проверки с аутентифицированным набором данных. Типичной практикой очистки данных является улучшение данных, при котором данные дополняются путем добавления связанной информации, например добавления местоположений с любыми телефонными номерами, связанными с этим адресом.
Очистка данных может также включать синхронизацию (или нормализацию) данных, которая представляет собой процесс объединения данных «переменных форматов файлов, номенклатуры и столбцов» и преобразования их в один связный набор данных; простой пример - расширение акронимов.
Как очистить данные?
Чистые данные — это основа важных исследований и выводов. Поэтому специалисты по обработке и анализу данных тратят 80% своего времени на очистку и нормализацию данных. Очистка данных использует различные подходы.
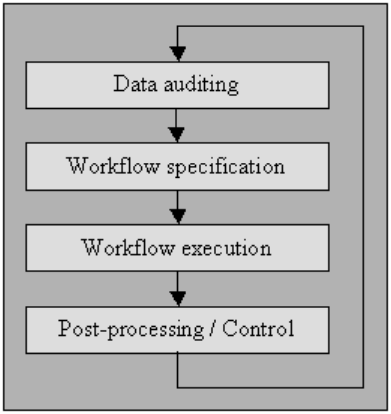
Аудит данных
Аудит данных с использованием статистических методов и методов базы данных для выявления аномалий и противоречий: это в конечном итоге указывает на характеристики особенностей и их местонахождение.
Несколько инструментов позволят вам постулировать проверки различных видов (используя грамматику, имитирующую стандартную кодировку, такую как JavaScript или Visual Basic), а затем сгенерировать код, который проверяет данные на предмет нарушения этих ограничений.
Я объяснил процесс ниже в разделах «спецификация рабочего процесса», а также «выполнение рабочего процесса». Для пользователей, у которых нет доступа к высококачественным инструментам очистки, системы управления базами данных микрокомпьютеров, такие как MS Access или File Maker Pro, также позволят вам получить такие разрешения на основе ограничения за пределом, в интерактивном режиме с легким программированием или без необходимости программирования во многих случаях. случаи.
Спецификация рабочего процесса
Иметь рабочий процесс для обнаружения и устранения аномалий. Он начинается после процедуры аудита данных и имеет решающее значение для получения конечного продукта высококачественных данных. Для создания надлежащего рабочего процесса требуется тщательный мониторинг причин аномалий и ошибок в данных.
Выполнение рабочего процесса
На этом этапе выполните рабочий процесс после выполнения его требований и подтверждения его точности.
Применение рабочего процесса должно быть хорошо организовано даже на обширных наборах данных, что неизбежно создает компромисс, поскольку выполнение процесса очистки данных может быть дорогостоящим в вычислительном отношении.
Постобработка и контроль
После завершения рабочего процесса очистки проверьте результаты, чтобы убедиться в их правильности. Исправьте неправильные данные, оставшиеся после выполнения рабочего процесса, вручную, если это возможно.
Результатом является новая последовательность в процедуре очистки данных, в которой вы снова проверяете данные, чтобы удовлетворить потребность в дополнительном рабочем процессе для очистки данных путем дальнейшей автоматической обработки.
Исходные данные более высокого качества связаны с «Культурой качества данных», и каждая организация должна инициировать ее на вершине бизнес-истеблишмента.
Это не просто вопрос выполнения безопасных проверок на экранах ввода, потому что почти независимо от того, насколько тщательны эти проверки, пользователи часто могут их обойти.

Существует руководство из девяти шагов для учреждений, желающих улучшить качество данных:
- Объявить высокий уровень гарантии культуры качества данных
- Стимулировать реинжиниринг процедур на уровне принятия решений
- Потратьте тесто, чтобы продвинуть настройку ввода данных
- Потратьте деньги на разработку интеграции приложений
- Выделите деньги, чтобы изменить функционирование процессов
- Обеспечьте сквозную оперативность команды
- Поощряйте межведомственное сотрудничество
- Публично заявить о превосходстве в качестве данных
- Постоянно измеряйте и улучшайте качество данных
Другие состоят из:
Разбор
для распознавания синтаксических ошибок. Синтаксический анализатор выбирает, является ли строка данных приемлемой в рамках допустимой спецификации данных. Это похоже на то, как синтаксический анализатор возится с синтаксисом и языком.
Преобразование данных
Преобразование данных позволяет отображать данные из заданного формата в порядке, ожидаемом соответствующим приложением. Он включает процедуры преобразования или преобразования значений, а также стандартизацию числовых значений для соответствия минимальным и максимальным значениям.
Удаление дубликатов
Для обнаружения дубликатов требуется алгоритм для определения того, есть ли в данных дубликаты одного и того же объекта. Обычно данные упорядочиваются по ключу, который сближает идентичные записи для более быстрой идентификации.
Статистические методы
Изучая данные с использованием значений среднего значения, стандартного отклонения, диапазона или процедур кластеризации, эксперт может найти непредвиденные и, следовательно, неверные значения.
Несмотря на то, что исправление таких данных является крутым, поскольку фактический номинал неизвестен, вы можете решить эту проблему, установив значения на среднее или другое статистическое значение.
Еще одно использование статистических методов связано с обработкой потерянных номиналов, которые могут быть заменены одним или несколькими возможными значениями, которые обычно получаются с помощью обширных алгоритмов увеличения данных.
Гигиена данных или качество данных
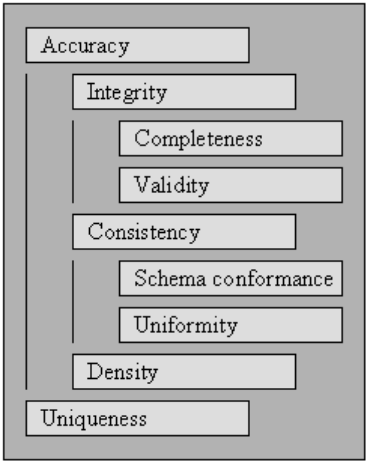
Чтобы данные можно было эффективно и результативно обрабатывать и интерпретировать, они должны удовлетворять ряду критериев качества. Данные, отвечающие этим критериям качества, считаются высококачественными. Как правило, агрегированное значение по набору критериев качества является качеством данных.
Начиная с критериев качества, указанных в , мы описываем набор стандартов, на которые влияет комплексная очистка данных, и определяем, как оценивать баллы по каждому из них для существующей коллекции данных.
Для измерения качества сбора данных оцените рейтинги по каждому из критериев качества.
Использование оценки баллов по критериям качества может быть способом количественной оценки необходимости очистки данных для сбора данных, а также успеха выполненного процесса очистки данных при сборе данных.
Вы можете использовать критерии качества в рамках оптимизации очистки данных, указав приоритеты для каждого из требований, что, в свою очередь, влияет на выполнение методов очистки данных, влияющих на конкретные правила.
Срок действия
Точка, в которой данные соответствуют определенным бизнес-правилам или ограничениям.
- Ограничения типа данных: значения в конкретном столбце должны относиться к определенному типу данных, например, логическому, числовому, дате и т. д.
- Ограничения диапазона: как правило, числа или даты должны находиться в определенном диапазоне.
- Обязательные ограничения : определенные столбцы не могут быть пустыми.
- Уникальные ограничения: поле или смесь областей должны различаться в наборе данных.
- Ограничения набора-членства : наименования столбца исходят из набора дискретных значений, например, значений перечисления. Например, пол может быть мужским, женским или другим.
- Ограничения внешнего ключа : как и в системах реляционных баз данных, столбец внешнего ключа должен существовать в указанном первичном ключе.
- Шаблоны регулярных выражений. Текстовые поля должны соответствовать определенному дизайну. Например, телефонные номера должны подчиняться определенному профилю (xxx) xxx-xxx.
- Межполевая проверка: должны соблюдаться определенные настройки, охватывающие множество областей, например, дата выписки пациента из больницы не может быть раньше времени госпитализации.
Точность
Степень, в которой данные близки к фактическим значениям. Хотя выделение всех возможных допустимых значений поля позволяет легко обнаружить недопустимые значения, это не означает, что они точны.
Действительный почтовый адрес может не существовать. А цвет глаз человека, скажем, голубой, может быть правильным, но не правильным. Еще одна вещь, о которой нельзя забывать, это разница между правильностью и точностью.
Правильно говорить, что вы живете на планете Земля. Но не точно. Где на планете? Предположение, что вы живете по определенному адресу улицы, является более точным.
Полнота
Точка, до которой известны и усвоены все необходимые данные.
Данные будут отсутствовать по разным причинам. Можно смягчить эту проблему, задав вопрос источнику.
Скорее всего, вы либо получите другой ответ, либо вам будет сложно узнать его снова.
Последовательность
Степень безошибочности данных в совпадающем наборе данных или в нескольких похожих наборах данных.
Несогласованность возникает, когда два значения в наборе данных противоречат друг другу.
Действительный возраст, скажем, 10, может не совпадать с семейным положением, скажем, в разводе. Запись клиента в две разные таблицы с двумя отдельными адресами является несоответствием.
Какой из них верный?
Единообразие
Степень, в которой указанные данные используют одну и ту же единицу измерения.
Вес в фунтах или килограммах, дата в формате США или в европейском формате и валюта иногда в долларах США или йенах.