
Was ist Datenbereinigung?
Veröffentlicht: 2021-11-18Unternehmen haben bereits vor langer Zeit die Bedeutung von Daten erkannt, wenn es darum geht, ihre Kunden zu verstehen und strategische Entscheidungen zur Steigerung des ROI zu treffen.
Im Kampf um kundenspezifische Produkte und Lösungen werden jedoch entscheidende Fakten zur Datenqualität außer Acht gelassen, was zu falschen analytischen Schlussfolgerungen und kostspieligen Geschäftsentscheidungen führt.
Gartner sagt: „Die durchschnittlichen finanziellen Auswirkungen einer schlechten Datenqualität auf Unternehmen betragen 9,7 Millionen US-Dollar pro Jahr.“ Sie können die Datenqualität verbessern, indem Sie genaue Dateneingabepunkte, eine effektive Datenzusammenführung, Datenstandardisierung und Datenbereinigungsmethoden sicherstellen.
Die praktische Anwendung von Datenbereinigungs- und Anreicherungstechniken kann beim Erstellen, Validieren, Aktualisieren, Verbessern und Erweitern geschäftskritischer Daten helfen, indem benutzerdefinierte Tools (Spider, Bots und Skripte) und manuelle Prozesse entwickelt werden.
Hier sind einige Auswirkungen fehlerhafter Daten:
- Ovum Research berichtet, dass schlechte Datenqualität Unternehmen mindestens 30 % ihres Umsatzes kostet.
- Falsche Verkaufsdaten zwingen Verkäufer dazu, Zeit mit toten Leads zu verschwenden. Ungenaue Daten können das Unternehmen zu verzerrten Strategien lenken.
- MarketingSherpa gibt an, dass jedes Jahr 25-30 % der Daten beschädigt werden. Schlechte Daten können verzerrte Informationen über die demografischen Merkmale und das Kaufverhalten von Kunden liefern, was dazu führen würde, dass Werbetreibende Gelegenheiten verpassen.
- Fehlende Kommunikation ist eine massive Abkehr für Kunden. Schlechte Daten können zu Fehlkommunikation mit Kunden, einem Gefühl der Unzufriedenheit bei ihnen und sogar zu negativem Branding in sozialen Medien beitragen.
Was ist Datenbereinigung?
Datenbereinigung oder Datenbereinigung ist eine Methode zum Erkennen und Korrigieren von entwerteten oder ungenauen Datensätzen aus einem Recordset, einer Tabelle oder einer Datenbank. Es bezieht sich auf das Erkennen stückweiser, falscher, ungenauer oder nicht verwandter Teile der Daten und das anschließende Ersetzen, Modifizieren oder Entfernen der schmutzigen oder groben Daten.
Die Datenbereinigung kann interaktiv mit Data-Wrangling-Lösungen oder als Batch-Verarbeitung durch Skripting ausgeführt werden. Nach der Bereinigung sollte ein Datensatz mit anderen ähnlichen Datensätzen im System kohärent sein.
Die erkannten oder entfernten Diskrepanzen können anfänglich durch Ungenauigkeiten bei Benutzereingaben, durch Verzerrungen bei der Übertragung oder Speicherung oder durch unterschiedliche Datenwörterbuchdefinitionen derselben Entitäten in verschiedenen Speichern verursacht worden sein.
Die Datenbereinigung unterscheidet sich von der Datenauthentifizierung dadurch, dass die Validierung fast immer bedeutet, dass Daten bei der Zulassung aus dem System ausgeschlossen werden und zum Zeitpunkt der Eingabe und nicht anhand von Datensätzen erreicht werden.
Der eigentliche Vorgang der Datenbereinigung kann das Entfernen von Tippfehlern oder das Authentifizieren und Korrigieren von Werten im Vergleich zu einer bekannten Liste von Objekten umfassen. Die Validierung kann streng sein (z. B. das Ablehnen einer Adresse, die keine gültige Postleitzahl hat) oder unscharf (z. B. das Korrigieren von Datensätzen, die in gewissem Maße mit bestehenden, bekannten Konten übereinstimmen).
Einige Datenbereinigungstools bereinigen Daten, indem sie sie mit einem authentifizierten Datensatz abgleichen. Eine typische Datenbereinigungspraxis ist die Datenanreicherung, bei der Daten durch Hinzufügen zugehöriger Informationen vervollständigt werden, z. B. durch Anhängen von Standorten an Telefonnummern, die dieser Adresse zugeordnet sind.
Die Datenbereinigung kann auch die Synchronisierung (oder Normalisierung) von Daten umfassen, d. h. den Prozess des Zusammenführens von Daten „variabler Dateiformate, Nomenklaturen und Spalten“ und deren Umwandlung in einen zusammenhängenden Datensatz; ein einfaches Beispiel ist eine Erweiterung von Akronymen.
Wie werden Daten bereinigt?
Saubere Daten sind die Grundlage für bedeutende Forschung und Erkenntnisse. Daher verbringen Data-Science-Manager 80 % ihrer Zeit mit der Datenbereinigung und -normalisierung. Data Cleansing verfolgt verschiedene Ansätze.
Datenprüfung
Prüfen Sie die Daten mit statistischen und Datenbankmethoden, um Anomalien und Widersprüche zu erkennen: Dies zeigt schließlich die Merkmale der Besonderheiten und ihrer Lokalitäten.
Mit mehreren Tools können Sie Überprüfungen verschiedener Art postulieren (unter Verwendung einer Grammatik, die eine Standardcodierung wie JavaScript oder Visual Basic imitiert) und dann Code generieren, der die Daten auf Verstöße gegen diese Einschränkungen untersucht.
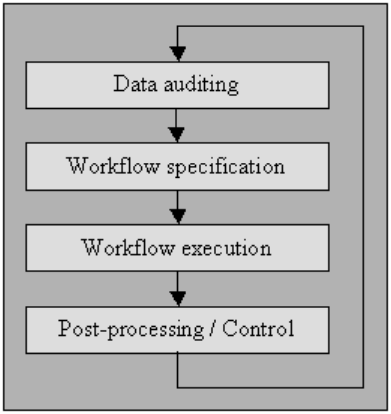
Ich habe den Prozess unten in „Workflow-Spezifikation“ sowie „Workflow-Ausführung“ erklärt. Für Benutzer, die keinen Zugang zu High-End-Bereinigungstools haben, können Sie mit Microcomputer-Datenbankverwaltungssystemen wie MS Access oder File Maker Pro solche Autorisierungen auch auf einer Limit-by-Limit-Basis erreichen, interaktiv mit leichter oder keiner Programmierung, die in vielen Fällen erforderlich ist Fälle.
Workflow-Spezifikation
Haben Sie einen Workflow für die Erkennung und Beseitigung von Anomalien. Es beginnt nach dem Verfahren der Datenprüfung und ist entscheidend für das Erreichen des Endprodukts qualitativ hochwertiger Daten. Die Erstellung eines ordnungsgemäßen Workflows erfordert eine genaue Überwachung der Ursachen der Anomalien und Fehler in den Daten.
Workflow-Ausführung
Führen Sie in dieser Phase den Workflow aus, nachdem seine Anforderung erfüllt und seine Genauigkeit bestätigt wurde.
Die Anwendung des Workflows sollte gut organisiert sein, selbst bei großen Datensätzen, was unvermeidlich einen Kompromiss darstellt, da die Durchführung eines Datenbereinigungsprozesses rechenintensiv sein kann.
Nachbearbeitung und Controlling
Überprüfen Sie nach Abschluss des Bereinigungs-Workflows die Ergebnisse auf Korrektheit. Korrigieren Sie die fehlerhaften Daten, die nach der Ausführung des Workflows hinterlassen wurden, falls möglich, manuell.
Das Ergebnis ist eine neue Sequenz im Datenbereinigungsverfahren, bei der Sie die Daten erneut prüfen, um die Anforderung eines zusätzlichen Workflows zuzulassen, um die Daten durch automatische Weiterverarbeitung zu bereinigen.
Quelldaten von besserer Qualität haben mit „Datenqualitätskultur“ zu tun, und jede Organisation muss sie an der Spitze des Unternehmens initiieren.
Dabei geht es nicht nur darum, sichere Validierungsprüfungen auf Eingabemasken durchzuführen, denn fast so sorgfältig diese Prüfungen sind, können sie von den Benutzern oft noch umgangen werden.
Es gibt einen neunstufigen Leitfaden für Einrichtungen, die die Datenqualität verbessern möchten:

- Erklären Sie eine Datenqualitätskultur auf hohem Niveau
- Die Umgestaltung von Verfahren auf der Ebene der Politikgestaltung vorantreiben
- Geben Sie Teig aus, um die Dateneingabeeinstellung voranzutreiben
- Geben Sie Geld aus, um die Anwendungsintegration zu entwickeln
- Geben Sie Geld aus, um die Funktionsweise von Prozessen zu ändern
- Unterstützen Sie die End-to-End-Reaktionsfähigkeit des Teams
- Förderung der abteilungsübergreifenden Zusammenarbeit
- Zeigen Sie öffentlich die Überlegenheit der Datenqualität
- Messen und verbessern Sie die Datenqualität unaufhörlich
Andere bestehen aus:
Parsing
zur Erkennung von Syntaxfehlern. Ein Parser entscheidet, ob eine Datenkette innerhalb der zulässigen Datenspezifikation akzeptabel ist. Es ist vergleichbar mit der Arbeit eines Parsers mit Syntaxen und Sprachen.
Datentransformation
Die Datentransformation ermöglicht das Plotten der Daten aus ihrem gegebenen Format in die Anordnung, die von der entsprechenden Anwendung erwartet wird. Es umfasst Wertkonvertierungen oder Übersetzungsverfahren sowie die Standardisierung numerischer Werte, um den Mindest- und Höchstwerten zu folgen.
Doppelte Eliminierung
Die Duplikaterkennung benötigt einen Algorithmus zum Definieren, ob die Daten Duplikate derselben Entität enthalten. Normalerweise werden Daten nach einem Schlüssel angeordnet, der identische Einträge zur schnelleren Identifizierung näher bringt.
statistische Methoden
Durch Untersuchung der Daten anhand von Mittelwert-, Standardabweichungs-, Bereichs- oder Clustering-Verfahren kann ein Experte unerwartete und damit falsche Werte finden.
Auch wenn die Korrektur solcher Daten steil ist, da der tatsächliche Nennwert nicht bekannt ist, können Sie sie lösen, indem Sie die Werte auf einen Durchschnittswert oder einen anderen statistischen Wert setzen.
Eine andere Verwendung statistischer Verfahren muss mit verlorenen Nennwerten umgehen, die durch einen oder mehrere mögliche Werte ersetzt werden können, die normalerweise durch umfangreiche Datenvermehrungsalgorithmen erfasst werden.
Datenhygiene oder Datenqualität
Damit Daten effektiv und effizient verarbeitet und interpretiert werden können, müssen sie eine Reihe von Qualitätskriterien erfüllen. Daten, die diese Qualitätskriterien erfüllen, gelten als von hoher Qualität. Im Allgemeinen ist die Datenqualität ein aggregierter Wert über eine Reihe von Qualitätskriterien.
Beginnend mit den in angegebenen Qualitätskriterien beschreiben wir die Standards, die von einer umfassenden Datenbereinigung betroffen sind, und definieren, wie die Punktzahl für jeden einzelnen von ihnen für eine bestehende Datensammlung zu bewerten ist.
Um die Qualität einer Datensammlung zu messen, werten Sie die Bewertungen für jedes der Qualitätskriterien aus.
Die Bewertung von Scores für Qualitätskriterien kann eine Möglichkeit sein, die Notwendigkeit einer Datenbereinigung für die Datenerhebung sowie den Erfolg eines durchgeführten Datenbereinigungsprozesses bei einer Datenerhebung zu quantifizieren.
Sie können Qualitätskriterien innerhalb der Optimierung der Datenbereinigung verwenden, indem Sie Prioritäten für jede der Anforderungen festlegen, was wiederum die Ausführung von Datenbereinigungsmethoden beeinflusst, die sich auf die spezifischen Regeln auswirken.
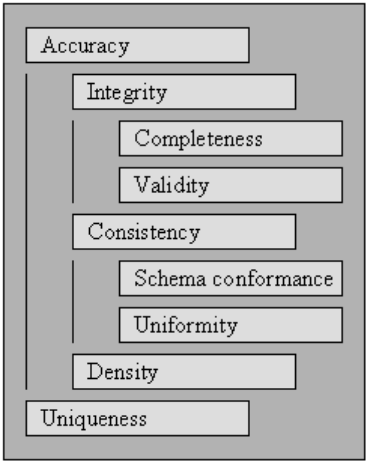
Gültigkeit
Der Punkt, bis zu dem die Daten in definierte Geschäftsregeln oder Einschränkungen passen.
- Datentypbeschränkungen: Werte in einer bestimmten Spalte müssen von einem bestimmten Datentyp sein, z. B. boolesch, numerisch, Datum usw.
- Bereichseinschränkungen : Normalerweise sollten Zahlen oder Datumsangaben innerhalb eines bestimmten Bereichs liegen.
- Obligatorische Einschränkungen : Bestimmte Spalten dürfen nicht leer sein.
- Eindeutige Einschränkungen: Ein Feld oder eine Mischung von Bereichen muss in einem Datensatz eindeutig sein.
- Set-Membership Constraints : Bezeichnungen einer Spalte stammen aus einem Satz von diskreten Werten, z. B. Aufzählungswerten. Beispielsweise kann das Geschlecht männlich, weiblich oder andere sein.
- Fremdschlüsselbeschränkungen : Wie in relationalen Datenbanksystemen sollte eine Fremdschlüsselspalte im referenzierten Primärschlüssel vorhanden sein.
- Reguläre Ausdrucksmuster: Textfelder sollten einem bestimmten Design folgen. Beispielsweise müssen Telefonnummern einem bestimmten Profil (xxx) xxx-xxx entsprechen.
- Feldübergreifende Validierung: Spezifische Einstellungen, die sich über mehrere Felder erstrecken, müssen enthalten sein, z. B. darf das Entlassungsdatum eines Patienten aus dem Krankenhaus nicht vor dem Aufnahmezeitpunkt liegen.
Genauigkeit
Der Grad, in dem die Daten den tatsächlichen Werten nahe kommen. Während die Umrisse aller möglichen gültigen Feldwerte es ermöglichen, ungültige Werte leicht zu erkennen, bedeutet dies nicht, dass sie korrekt sind.
Möglicherweise ist keine gültige Adresse vorhanden. EIN Die Augenfarbe einer Person, sagen wir blau, könnte richtig sein, aber nicht richtig. Eine andere Sache, die man nicht vergessen sollte, ist der Unterschied zwischen Korrektheit und Präzision.
Zu sagen, dass du auf dem Planeten Erde lebst, ist richtig. Aber nicht präzise. Wo auf dem Planeten? Die Annahme, dass Sie an einer bestimmten Straßenadresse wohnen, ist genauer.
Vollständigkeit
Der Punkt, an dem alle erforderlichen Daten bekannt und assimiliert sind.
Daten werden aus verschiedenen Gründen fehlen. Man kann dieses Problem entschärfen, indem man die Quelle hinterfragt.
Es besteht die Möglichkeit, dass Sie entweder eine andere Antwort erhalten oder es schwierig wird, sie erneut zu ermitteln.
Konsistenz
Der Grad, in dem die Daten innerhalb des übereinstimmenden Datensatzes oder über mehrere ähnliche Datensätze hinweg unfehlbar sind.
Inkonsistenz tritt auf, wenn zwei Werte im Datensatz einander widersprechen.
Ein gültiger Alter, sagen wir 10, stimmt vielleicht nicht mit dem Familienstand überein, sagen wir geschieden. Die Aufzeichnung eines Kunden in zwei verschiedenen Tabellen mit zwei separaten Adressen ist eine Inkonsistenz.
Welches ist wahr?
Gleichmäßigkeit
Der Grad, in dem die angegebenen Daten dieselbe Einheit des Messgeräts verwenden.
Das Gewicht in Pfund oder Kilo, ein Datum im US-Format oder europäischen Format und die Währung manchmal in USD oder YEN.