
データクレンジングとは?
公開: 2021-11-18企業はかなり前から、顧客を理解し、ROI を向上させるための戦略的意思決定を行う上で、データの重要性を認識していました。
しかし、カスタマイズされた製品やソリューションを提供しようと争う中で、データ品質に関する重要な事実が脇に追いやられ、誤った分析的推論やコストのかかるビジネス上の意思決定につながります。
Gartner は、「データ品質の低下が組織に及ぼす平均的な経済的影響は、年間 970 万ドルです」と述べています。 正確なデータ エントリ ポイント、効果的なデータ融合、データ標準化、およびデータ クレンジング方法を確保することで、データの品質を向上させることができます。
カスタム ツール (スパイダー、ボット、スクリプト) と手動プロセスを開発することで、データ クレンジングとエンリッチメントの手法を実際に適用することで、ビジネスに不可欠なデータの作成、検証、更新、強化、強化を行うことができます。
不良データの影響を次に示します。
- Ovum Research の報告によると、データ品質が悪いと企業は収益の少なくとも 30% を失うことになります。
- 不正確な販売データにより、営業担当者はデッド リードに時間を浪費することになります。 不正確なデータは、ビジネスを歪んだ戦略に導く可能性があります。
- MarketingSherpa によると、毎年 25 ~ 30% のデータが破損しています。 質の悪いデータは、顧客の人口統計や購買行動に関する歪んだ情報を提供する可能性があり、マーケティング担当者が機会を逃す可能性があります。
- コミュニケーションの欠落は、顧客にとって大規模なターンオフです。 悪いデータは、顧客への誤解、顧客の不満、さらにはソーシャル メディアでのネガティブなブランディングにつながる可能性があります。
データクレンジングとは?
データ クレンジングまたはデータ クリーニングは、レコードセット、テーブル、またはデータベースから劣化または不正確なレコードを見つけて修正する方法です。 これは、データの断片的、不正確、不正確、または無関係な部分を検出し、汚れたデータまたは粗いデータを置換、変更、または削除することを指します。
データ クレンジングは、データ ラングリング ソリューションと対話的に実行することも、スクリプトによるバッチ処理として実行することもできます。 サニタイズ後、データ セットはシステム内の他の同様のデータ セットと一貫性がある必要があります。
検出または削除された不一致は、最初はユーザー入力の不正確さ、転送または保存の歪み、または異なるストア内の同じエンティティの異なるデータ ディクショナリ定義によって引き起こされた可能性があります。
データ クレンジングはデータ認証とは異なります。検証とは、データのセットではなく、データが入場時にシステムから除外され、入場時に達成されることをほぼ一定に意味するという点です。
データクレンジングの実際の手順には、タイプミスの除去、またはオブジェクトの既知のリストと比較した値の認証および修正が含まれる場合があります。 検証は、厳密 (有効な郵便番号を持たない住所を拒否するなど) の場合もあれば、あいまいな場合 (既存の既知のアカウントと何らかの方法で一致するレコードを修正するなど) の場合もあります。
一部のデータ クレンジング ツールは、認証済みデータ セットとのクロスチェックによってデータをクレンジングします。 典型的なデータ クレンジング プラクティスはデータ エンハンスメントです。この場合、関連情報を追加してデータを完成させます。たとえば、住所に関連付けられた電話番号を場所に追加するなどです。
データクレンジングには、データの同期 (または正規化) も含まれる場合があります。これは、「可変ファイル形式、命名法、および列」のデータを集めて、それを 1 つのまとまりのあるデータセットに変更するプロセスです。 簡単な例は、頭字語の拡張です。
データをきれいにする方法は?
クリーンなデータは、重要な研究と洞察の基盤です。 したがって、データ サイエンスの幹部は、時間の 80% をデータのクレンジングと正規化に費やしています。 データクレンジングは、さまざまなアプローチに従います。
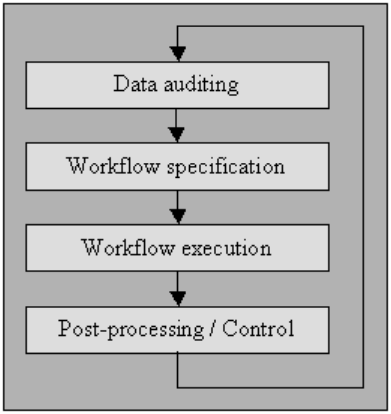
データ監査
異常や矛盾を検出するために、統計およびデータベース手法を使用してデータを監査します。これにより、最終的に特異点の特徴とその場所が示されます。
いくつかのツールを使用すると、(JavaScript や Visual Basic などの標準エンコーディングを模倣する文法を使用して) さまざまな種類のチェックを仮定し、これらの制約に違反していないかどうかデータを調べるコードを生成できます。
以下のプロセスは、「ワークフローの仕様」と「ワークフローの実行」で説明しました。 ハイエンドのクレンジング ツールにアクセスできないユーザーの場合、MS Access や File Maker Pro などのマイクロコンピューター データベース管理システムを使用すると、制限ごとに、インタラクティブに、軽いプログラミングで、またはプログラミングを必要とせずに、このような認証を行うことができます。ケース。
ワークフロー仕様
異常を検出して除去するためのワークフローを用意します。 これは、データの監査手順の後に開始され、高品質のデータの最終製品を達成する上で重要です。 適切なワークフローを作成するには、データの異常やエラーの原因を注意深く監視する必要があります。
ワークフローの実行
この段階では、ワークフローの要件が完了した後にワークフローを実行し、その正確性を確認します。
データクレンジングプロセスの実行には計算コストがかかる可能性があるため、ワークフローの適用は、膨大なデータセットであっても、よく整理されている必要があります。
後処理と制御
クレンジング ワークフローが完了したら、結果を調べて正確性を確認します。 可能であれば、ワークフローの実行後に残った誤ったデータを手動で調整します。
その結果、データを再度監査して、さらに自動処理によってデータをクレンジングするための追加のワークフローの要件を許可する、データ クレンジング手順の新しいシーケンスができます。
より良い品質のソース データは「データ品質文化」と関係があり、すべての組織は事業所のトップでそれを開始する必要があります。
入力画面で安全な検証チェックを実行するだけの問題ではありません。これらのチェックがどれほど注意を払っても、ユーザーがバイパスすることがよくあるからです。
データ品質の向上を希望する施設向けの 9 ステップのガイドがあります。
- データ品質文化に対する高レベルの保証を宣言する
- 政策決定レベルで手順の再設計を推進する
- 生地を使って入力設定を進める
- アプリケーション統合の開発にお金を使う
- プロセスの機能を変えるためにお金を使う
- エンドツーエンドのチームの応答性を支持する
- 部門間のコラボレーションを促進する
- データ品質の優位性を公に明らかにする
- 絶え間ないデータ品質の測定と向上
その他は次のもので構成されます。

解析中
構文エラーの認識用。 パーサーは、許可されたデータ仕様内でデータのストリングが受け入れられるかどうかを選択します。 これは、パーサーが構文と言語を処理する方法に似ています。
データ変換
データ変換により、データを特定の形式から適切なアプリケーションで期待される配置にプロットできます。 最小値と最大値に従うように数値を標準化するだけでなく、値の変換または変換手順が組み込まれています。
重複排除
重複検出には、データに同じエンティティの重複があるかどうかを定義するためのアルゴリズムが必要です。 通常、データは、識別を高速化するために同一のエントリを近づけるキーによって配置されます。
統計的方法
平均値、標準偏差、範囲、またはクラスタリング手順の値を使用してデータを調べることにより、専門家は予期しない、したがって不正確な値を見つけることができます。
実際の金種がわからないため、このようなデータの修正は急勾配ですが、値を平均値または他の統計値に設定することで解決できます。
統計的手法のもう 1 つの用途は、失われた金種を処理する必要があります。これは、通常、広範なデータ拡張アルゴリズムによって取得される 1 つまたは複数の可能な値で置き換えることができます。
データ衛生またはデータ品質
データを効果的かつ効率的に処理および解釈できるようにするには、一連の品質基準を満たす必要があります。 これらの品質基準を満たすデータは、高品質であると言われます。 一般に、一連の品質基準に対する集計値がデータ品質です。
で指定されている品質基準から始めて、包括的なデータ クレンジングの影響を受ける一連の基準について説明し、既存のデータ コレクションの各基準のスコアを評価する方法を定義します。
データ コレクションの品質を測定するには、各品質基準の評価を評価します。
品質基準のスコア評価を使用することで、データ収集のためのデータ クレンジングの必要性と、データ コレクションに対して実行されたデータ クレンジング プロセスの成功を定量化することができます。
各要件の優先順位を指定することで、データ クレンジングの最適化内で品質基準を使用できます。これは、特定のルールに影響を与えるデータ クレンジング メソッドの実行に影響を与えます。
有効
定義されたビジネス ルールまたは制約にデータが適合するポイント。
- データ型の制約:特定の列の値は、ブール値、数値、日付など、特定のデータ型である必要があります。
- 範囲の制約:通常、数値または日付は特定の範囲内にある必要があります。
- 必須の制約:特定の列を空白にすることはできません。
- 固有の制約:フィールドまたは領域のブレンドは、データセット全体で固有でなければなりません。
- セット メンバーシップの制約:列の名称は、列挙値などの離散値のセットから発生します。 たとえば、性別は、男性、女性、またはその他の場合があります。
- 外部キー制約:リレーショナル データベース システムと同様に、参照される主キーに外部キー列が存在する必要があります。
- 正規表現パターン:テキスト フィールドは特定の設計に従う必要があります。 たとえば、電話番号は特定のプロファイル (xxx) xxx-xxx に従う必要があります。
- フィールド間の検証:多数のフィールドにまたがる特定の設定を保持する必要があります。たとえば、患者の退院日は入院日より前にすることはできません。
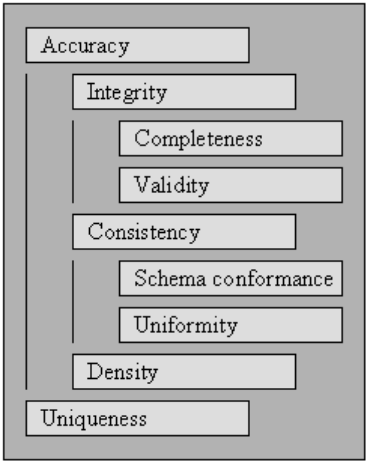
正確さ
データが実際の値にどの程度近いか。 考えられるすべての有効なフィールド値を概説すると、無効な値を簡単に見つけることができますが、それが正確であることを意味するわけではありません。
有効な住所が存在しない可能性があります。 あ 人の目の色、たとえば青は正しいかもしれませんが、そうではありません。 忘れてはならないもう 1 つのことは、正確さと精度の違いです。
あなたが地球に住んでいると言うのは適切です。 しかし、正確ではありません。 地球上のどこ? 特定の番地に住んでいると仮定すると、より正確になります。
完全
必要なすべてのデータが認識され、同化されるポイント。
さまざまな原因でデータが失われます。 ソースに質問することで、この問題を軽減できます。
可能性としては、別の答えが得られるか、もう一度確認するのが困難になる可能性があります。
一貫性
一致するデータ セット内または複数の同様のデータ セットにわたって、データが確実に機能する程度。
不一致は、データ セット内の 2 つの値が互いに矛盾する場合に発生します。
有効な 年齢、たとえば 10 歳、たとえば離婚などの婚姻状況と一致しない可能性があります。 2 つの別々の住所を持つ 2 つの異なるテーブルに顧客を記録することは矛盾です。
どれが本当ですか?
均一
指定されたデータがゲージの同じ単位を使用している度合い。
ポンドまたはキロ単位の重量、USA 形式またはヨーロッパ形式の日付、通貨は USD または YEN の場合もあります。