
Apa itu Pembersihan Data?
Diterbitkan: 2021-11-18Bisnis sejak lama telah menyadari pentingnya data dalam memahami pelanggan mereka dan membuat keputusan strategis untuk meningkatkan ROI.
Namun, dalam perebutan untuk menghadirkan produk dan solusi yang disesuaikan, fakta penting tentang kualitas data dikesampingkan, yang mengarah pada kesimpulan analitis yang salah dan keputusan bisnis yang mahal.
Gartner mengatakan, “Dampak keuangan rata-rata dari kualitas data yang buruk pada organisasi adalah $9,7 juta per tahun.” Anda dapat meningkatkan kualitas data dengan memastikan titik entri data yang akurat, penggabungan data yang efektif, standarisasi data, dan metode pembersihan data.
Aplikasi praktis dari teknik pembersihan dan pengayaan data dapat membantu dalam membuat, memvalidasi, memperbarui, menyempurnakan, dan menyempurnakan data penting bisnis dengan mengembangkan alat khusus (laba-laba, bot, dan skrip) dan proses manual.
Berikut adalah beberapa implikasi dari data yang buruk:
- Ovum Research melaporkan kualitas data yang buruk merugikan bisnis setidaknya 30% dari pendapatan mereka.
- Data penjualan yang salah mendorong tenaga penjualan membuang-buang waktu untuk lead mati. Data yang tidak akurat dapat mengarahkan bisnis ke arah strategi yang tidak tepat.
- MarketingSherpa menyatakan bahwa setiap tahun 25-30% data rusak. Data yang buruk dapat memberikan informasi yang terdistorsi tentang demografi pelanggan dan perilaku pembelian, yang akan menyebabkan hilangnya peluang bagi pemasar.
- Miss-komunikasi adalah turn-off besar-besaran bagi pelanggan. Data yang buruk dapat menyebabkan miskomunikasi kepada pelanggan, rasa tidak puas di antara mereka, dan bahkan branding negatif di media sosial.
Apa itu pembersihan data?
Pembersihan data atau pembersihan data adalah metode untuk menemukan dan memperbaiki catatan yang tidak tepat atau tidak akurat dari kumpulan catatan, tabel, atau basis data. Ini mengacu pada pendeteksian bagian data yang sedikit demi sedikit, tidak benar, tidak tepat, atau tidak terkait dan kemudian mengganti, memodifikasi, atau menghapus data yang kotor atau kasar.
Pembersihan data dapat dijalankan secara interaktif dengan solusi perselisihan data, atau sebagai pemrosesan batch dengan skrip. Setelah sanitasi, kumpulan data harus koheren dengan kumpulan data serupa lainnya dalam sistem.
Perbedaan yang terdeteksi atau dihapus mungkin awalnya disebabkan oleh ketidakakuratan entri pengguna, distorsi dalam transmisi atau penyimpanan, atau definisi kamus data yang berbeda dari entitas yang sama di penyimpanan yang berbeda.
Pembersihan data berbeda dari otentikasi data dalam validasi yang hampir sama berarti data dikeluarkan dari sistem saat masuk dan dicapai pada saat masuk, bukan pada kumpulan data.
Prosedur sebenarnya dari pembersihan data dapat terdiri dari menghilangkan kesalahan ketik atau mengotentikasi dan mengoreksi nilai dibandingkan dengan daftar objek yang diketahui. Validasi mungkin ketat (seperti menolak alamat apa pun yang tidak memiliki kode pos yang valid) atau kabur (seperti memperbaiki catatan yang dalam beberapa ukuran cocok dengan akun yang ada dan dikenal).
Beberapa alat pembersihan data akan membersihkan data dengan pemeriksaan silang dengan kumpulan data yang diautentikasi. Praktik pembersihan data yang umum adalah peningkatan data, di mana data dibuat lengkap dengan menambahkan informasi terkait—misalnya, menambahkan lokasi dengan nomor telepon apa pun yang terkait dengan alamat tersebut.
Pembersihan data juga dapat mencakup sinkronisasi (atau normalisasi) data, yang merupakan proses mengumpulkan data "format file variabel, nomenklatur, dan kolom", dan mengubahnya menjadi satu kumpulan data yang kohesif; contoh sederhana adalah perluasan akronim.
Bagaimana cara membersihkan data?
Data yang bersih adalah dasar dari penelitian dan wawasan yang signifikan. Oleh karena itu, eksekutif ilmu data menghabiskan 80% waktu mereka dalam pembersihan dan normalisasi data. Pembersihan Data mengikuti berbagai pendekatan.
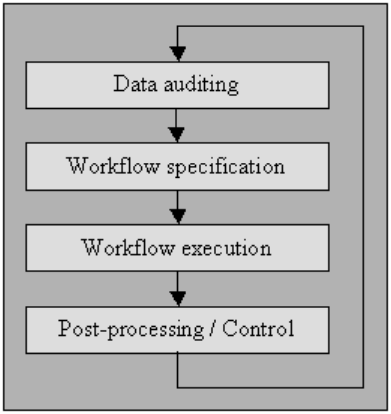
Audit data
Audit data menggunakan metode statistik dan database untuk mendeteksi anomali dan kontradiksi: ini akhirnya menunjukkan karakteristik kekhasan dan lokalitasnya.
Beberapa alat akan memungkinkan Anda mendalilkan pemeriksaan dari berbagai jenis (menggunakan tata bahasa yang meniru pengkodean standar seperti JavaScript atau Visual Basic) dan kemudian menghasilkan kode yang memeriksa data untuk pelanggaran batasan ini.
Saya telah menjelaskan proses di bawah ini dalam "spesifikasi alur kerja," serta "eksekusi alur kerja." Untuk pengguna yang tidak memiliki akses ke alat pembersihan kelas atas, sistem manajemen basis data komputer mikro seperti MS Access atau File Maker Pro lainnya juga akan memungkinkan Anda mencapai otorisasi semacam itu berdasarkan batas demi batas, secara interaktif dengan sedikit atau tanpa pemrograman yang diperlukan di banyak kasus.
Spesifikasi alur kerja
Memiliki alur kerja untuk mendeteksi dan menghilangkan anomali. Ini dimulai setelah prosedur audit data dan sangat penting dalam mencapai produk akhir dari data berkualitas tinggi. Membuat alur kerja yang tepat membutuhkan pemantauan ketat terhadap penyebab anomali dan kesalahan dalam data.
Eksekusi alur kerja
Pada tahap ini, jalankan alur kerja setelah persyaratannya selesai, dan akurasinya dikonfirmasi.
Penerapan alur kerja harus diatur dengan baik, bahkan pada kumpulan data yang sangat besar, yang tidak dapat dihindari menimbulkan trade-off karena pelaksanaan proses pembersihan data dapat memakan biaya komputasi yang mahal.
Pasca-pemrosesan dan pengendalian
Setelah menyelesaikan alur kerja pembersihan, periksa hasilnya untuk memverifikasi kebenarannya. Sesuaikan data yang salah yang tersisa pasca-eksekusi alur kerja secara manual, jika memungkinkan.
Hasilnya adalah urutan baru dalam prosedur pembersihan data di mana Anda mengaudit data lagi untuk mengizinkan persyaratan alur kerja tambahan untuk membersihkan data dengan pemrosesan otomatis lebih lanjut.
Sumber data dengan kualitas yang lebih baik berkaitan dengan “Budaya Kualitas Data”, dan setiap organisasi harus memulainya di puncak pendirian bisnis.
Ini bukan hanya soal menjalankan pemeriksaan validasi aman pada layar input, karena hampir tidak peduli seberapa hati-hati pemeriksaan ini, sering kali masih dapat dilewati oleh pengguna.

Ada panduan sembilan langkah untuk perusahaan yang ingin meningkatkan kualitas data:
- Deklarasikan jaminan tingkat tinggi untuk budaya kualitas data
- Mendorong rekayasa ulang prosedur di tingkat pembuatan kebijakan
- Habiskan adonan untuk memajukan pengaturan entri data
- Habiskan uang untuk mengembangkan integrasi aplikasi
- Mengabdikan uang untuk mengubah cara proses berfungsi
- Mendukung respons tim end-to-end
- Mendorong kerjasama antardepartemen
- Mengungkapkan keunggulan kualitas data secara publik
- Tak henti-hentinya mengukur dan meningkatkan kualitas data
Lainnya terdiri dari:
Penguraian
untuk pengenalan kesalahan sintaks. Parser memilih apakah string data dapat diterima dalam spesifikasi data yang diizinkan. Ini mirip dengan cara kerja parser dengan sintaks dan bahasa.
Transformasi data
Transformasi data memungkinkan ploting data dari format yang diberikan ke dalam pengaturan yang diharapkan oleh aplikasi yang sesuai. Ini menggabungkan konversi nilai atau prosedur terjemahan, serta standarisasi nilai numerik untuk mengikuti nilai minimum dan maksimum.
Penghapusan duplikat
Deteksi duplikat membutuhkan algoritma untuk menentukan apakah data memiliki duplikat dari entitas yang sama. Biasanya, data diatur oleh kunci yang akan membawa entri identik lebih dekat untuk identifikasi lebih cepat.
Metode statistik
Dengan memeriksa data menggunakan nilai mean, standar deviasi, rentang, atau prosedur pengelompokan, seorang ahli dapat menemukan nilai yang tidak terduga dan dengan demikian salah.
Meskipun koreksi data tersebut curam karena denominasi sebenarnya tidak diketahui, namun Anda dapat mengatasinya dengan menetapkan nilai rata-rata atau nilai statistik lainnya.
Salah satu penggunaan lain dari metode statistik harus menangani denominasi yang hilang, yang dapat diganti dengan satu atau lebih nilai yang mungkin, yang biasanya diperoleh dengan algoritme augmentasi data ekstensif.
Kebersihan data atau Kualitas data
Agar data dapat diproses dan ditafsirkan secara efektif dan efisien, data harus memenuhi serangkaian kriteria kualitas. Data yang memenuhi kriteria kualitas tersebut dikatakan berkualitas tinggi. Secara umum, nilai agregat atas serangkaian kriteria kualitas adalah kualitas data.
Dimulai dengan kriteria kualitas yang ditentukan dalam, kami menjelaskan serangkaian standar yang dipengaruhi oleh pembersihan data komprehensif dan menentukan cara menilai skor untuk masing-masing standar untuk pengumpulan data yang ada.
Untuk mengukur kualitas kumpulan data, evaluasi peringkat untuk setiap kriteria kualitas.
Menggunakan penilaian skor untuk kriteria kualitas dapat menjadi cara untuk mengukur perlunya pembersihan data untuk pengumpulan data serta keberhasilan proses pembersihan data yang dilakukan pada pengumpulan data.
Anda dapat menggunakan kriteria kualitas dalam optimasi pembersihan data dengan menentukan prioritas untuk setiap persyaratan, yang pada gilirannya mempengaruhi pelaksanaan metode pembersihan data yang mempengaruhi aturan tertentu.
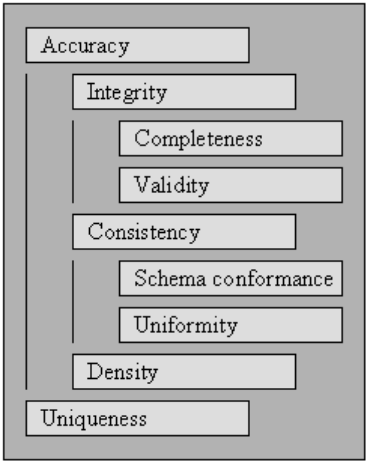
Keabsahan
Titik di mana data cocok dengan aturan atau batasan bisnis yang ditentukan.
- Batasan Tipe Data: nilai dalam kolom tertentu harus dari tipe data tertentu, misalnya, boolean, numerik, tanggal, dan sebagainya.
- Batasan Rentang: biasanya, angka atau tanggal harus berada dalam rentang tertentu.
- Batasan Wajib : kolom tertentu tidak boleh kosong.
- Batasan Unik: bidang, atau campuran area, harus berbeda di seluruh kumpulan data.
- Kendala Set-Membership : denominasi kolom berasal dari satu set nilai diskrit, misalnya nilai enum. Misalnya, jenis kelamin bisa laki-laki, perempuan, atau lainnya.
- Batasan kunci asing : seperti dalam sistem basis data relasional, kolom kunci asing harus ada di kunci utama yang direferensikan.
- Pola ekspresi reguler: Bidang teks harus mengikuti desain tertentu. Misalnya, nomor telepon harus mematuhi profil tertentu (xxx) xxx-xxx.
- Validasi lintas bidang: pengaturan khusus yang mencakup berbagai bidang harus dipertahankan, misalnya, tanggal keluar pasien dari rumah sakit tidak boleh sebelum waktu masuk.
Ketepatan
Sejauh mana data mendekati nilai sebenarnya. Meskipun menguraikan semua kemungkinan nilai bidang yang valid memungkinkan nilai yang tidak valid mudah terlihat, itu tidak berarti bahwa nilai tersebut akurat.
Alamat jalan yang valid mungkin tidak ada. SEBUAH warna mata seseorang, katakanlah biru, mungkin benar, tetapi tidak tepat. Satu hal lain yang tidak boleh dilupakan adalah perbedaan antara ketepatan dan ketepatan.
Mengatakan bahwa Anda tinggal di planet bumi adalah tepat. Tapi, tidak tepat. Di mana di planet ini? Dengan asumsi bahwa Anda tinggal di alamat jalan tertentu lebih akurat.
Kelengkapan
Titik dimana semua data yang dibutuhkan diketahui dan diasimilasi.
Data akan hilang karena berbagai penyebab. Seseorang dapat mengurangi masalah ini dengan mempertanyakan sumbernya.
Kemungkinannya adalah, Anda akan mendapatkan jawaban yang berbeda atau akan sulit untuk memastikannya lagi.
Konsistensi
Sejauh mana data tidak gagal, dalam kumpulan data yang cocok atau di beberapa kumpulan data serupa.
Inkonsistensi terjadi ketika dua nilai dalam kumpulan data saling bertentangan.
yang valid usia, katakanlah 10, mungkin tidak cocok dengan status perkawinan, katakanlah bercerai. Mencatat pelanggan di dua tabel berbeda dengan dua alamat terpisah merupakan inkonsistensi.
Mana yang benar?
Keseragaman
Sejauh mana data yang ditentukan menggunakan unit pengukur yang sama.
Berat dalam pound atau kilo, tanggal dalam format AS atau format Eropa, dan mata uang terkadang dalam USD atau YEN.