
什麼是數據清洗?
已發表: 2021-11-18很久以前,企業已經認識到數據在了解客戶和製定戰略決策以提高投資回報率方面的重要性。
然而,在爭相推出定制產品和解決方案的過程中,有關數據質量的關鍵事實被擱置一旁,從而導致不正確的分析推斷和代價高昂的業務決策。
Gartner 表示:“數據質量差對組織的平均財務影響為每年 970 萬美元。” 您可以通過確保准確的數據入口點、有效的數據合併、數據標準化和數據清理方法來提高數據質量。
數據清理和豐富技術的實際應用可以通過開發自定義工具(蜘蛛、機器人和腳本)和手動流程來幫助創建、驗證、更新、增強和增強業務關鍵數據。
以下是不良數據的一些影響:
- Ovum Research 報告稱,糟糕的數據質量使企業損失了至少 30% 的收入。
- 不正確的銷售數據會促使銷售人員將時間浪費在無效的潛在客戶上。 不准確的數據可能會導致業務轉向偏斜的策略。
- MarketingSherpa 指出,每年有 25-30% 的數據損壞。 不良數據可能會提供有關客戶人口統計和購買行為的扭曲信息,這將導致營銷人員錯失機會。
- 溝通不暢對客戶來說是一個巨大的障礙。 不良數據可能會導致與客戶的溝通不暢、客戶不滿意,甚至會在社交媒體上造成負面品牌影響。
什麼是數據清洗?
數據清理或數據清理是一種從記錄集、表或數據庫中發現和糾正低劣或不准確記錄的方法。 它是指檢測數據中零碎的、不正確的、不精確的或不相關的部分,然後替換、修改或刪除臟數據或粗糙數據。
數據清理可以與數據整理解決方案交互執行,也可以通過腳本進行批處理。 清理後,數據集應與系統中的其他類似數據集保持一致。
檢測或消除的差異最初可能是由用戶輸入不准確、傳輸或存儲失真或不同商店中相同實體的不同數據字典定義引起的。
數據清理與數據驗證的不同之處在於,驗證幾乎不變地意味著數據在准入時被排除在系統之外,並且是在輸入時完成的,而不是在數據集上完成的。
與已知對象列表相比,數據清理的實際過程可能包括消除印刷錯誤或驗證和更正值。 驗證可能很嚴格(例如拒絕任何沒有有效郵政編碼的地址)或模糊(例如更正在某些方面與現有已知帳戶匹配的記錄)。
一些數據清理工具將通過與經過身份驗證的數據集進行交叉檢查來清理數據。 典型的數據清理實踐是數據增強,通過添加相關信息使數據變得完整——例如,將位置附加到與該地址關聯的任何電話號碼。
數據清理還可能包括數據的同步(或規範化),這是將“可變文件格式、命名法和列”的數據收集在一起並將其更改為一個有凝聚力的數據集的過程; 一個簡單的例子是首字母縮略詞的擴展。
如何清理數據?
乾淨的數據是重要研究和見解的基礎。 因此,數據科學高管將 80% 的時間用於數據清理和規範化。 數據清理遵循各種方法。
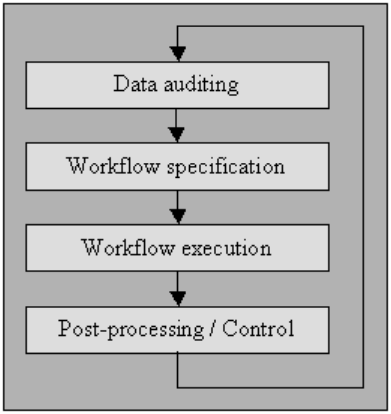
數據審計
使用統計和數據庫方法對數據進行審計,以檢測異常和矛盾:這最終表明了特殊性及其位置的特徵。
有幾個工具可以讓您假設各種檢查(使用模仿 JavaScript 或 Visual Basic 等標準編碼的語法),然後生成檢查數據是否違反這些約束的代碼。
我已經在“工作流程規範”以及“工作流程執行”中解釋了以下過程。 對於無法使用高端清理工具的用戶,微機數據庫管理系統(如 MS Access 或 File Maker Pro)也可以讓您在多個限制的基礎上實現此類授權,在許多情況下只需輕量級或無需編程即可交互案例。
工作流程規範
有一個檢測和消除異常的工作流程。 它在審計數據過程之後開始,對於完成高質量數據的最終產品至關重要。 創建適當的工作流程需要密切監視數據中異常和錯誤的原因。
工作流程執行
在這個階段,在其需求完成並確認其準確性後執行工作流。
工作流的應用應該組織良好,即使在大量數據上也是如此,由於執行數據清理過程的計算成本很高,這不可避免地會造成權衡。
後處理和控制
完成清理工作流程後,檢查結果以驗證正確性。 如果可以的話,手動調整工作流執行後留下的不正確數據。
結果是數據清理過程中的一個新序列,您可以在其中再次審核數據,以允許需要額外的工作流通過進一步的自動處理來清理數據。
更好質量的源數據與“數據質量文化”有關,每個組織都必須在業務機構的頂層啟動它。
這不僅僅是在輸入屏幕上執行安全驗證檢查的問題,因為幾乎無論這些檢查多麼小心,它們通常仍然可以被用戶繞過。
對於希望提高數據質量的機構,有一個九步指南:
- 聲明對數據質量文化的高水平保證
- 在決策層推動流程再造
- 花面子推進數據錄入設置
- 花錢開發應用集成
- 投入資金來改變流程的運作方式
- 支持端到端的團隊響應能力
- 鼓勵跨部門合作
- 公開揭示數據質量優勢
- 不斷衡量和提高數據質量
其他包括:

解析
用於識別語法錯誤。 解析器選擇在允許的數據規範內是否可以接受數據字符串。 它類似於解析器處理語法和語言的方式。
數據轉換
數據轉換允許將數據從其給定格式繪製成適當應用程序所期望的排列。 它包含值轉換或轉換過程,以及標準化數值以遵循最小值和最大值。
重複消除
重複檢測需要一種算法來定義數據是否具有相同實體的重複項。 通常,數據由一個鍵排列,這將使相同的條目更接近以便更快地識別。
統計方法
通過使用平均值、標準差、範圍或聚類程序的值檢查數據,專家可以發現未預料到的值,因此是不正確的。
儘管由於實際面額未知,因此此類數據的校正非常陡峭,但是,您可以通過將值設置為平均值或其他統計值來解決它。
統計方法的另一種用途必須處理丟失的面額,可以用一個或多個可能的值代替,這些值通常通過廣泛的數據增強算法獲得。
數據衛生或數據質量
數據要能夠有效和高效地處理和解釋,它必須滿足一組質量標準。 符合這些質量標準的數據被認為是高質量的。 通常,一組質量標準的聚合值就是數據質量。
從中指定的質量標准開始,我們描述了受全面數據清理影響的一組標準,並定義瞭如何評估現有數據收集中每個標準的分數。
要衡量數據收集的質量,請評估每個質量標準的評級。
使用質量標準的分數評估可以量化數據收集的數據清理的必要性以及對數據收集執行的數據清理過程的成功。
您可以通過為每個需求指定優先級來在數據清理優化中使用質量標準,這反過來會影響影響特定規則的數據清理方法的執行。
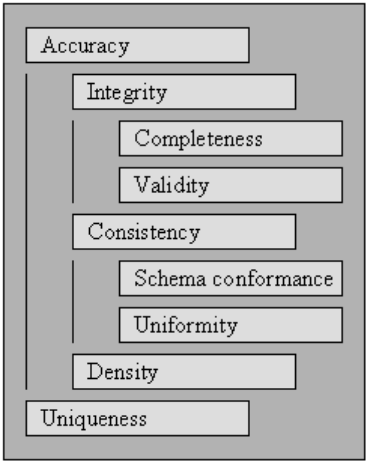
有效性
數據適合定義的業務規則或約束的點。
- 數據類型約束:特定列中的值必須是特定數據類型,例如布爾、數字、日期等。
- 範圍約束:通常,數字或日期應在特定範圍內。
- 強制約束:特定列不能為空。
- 獨特的約束:一個字段或多個區域的混合,在數據集中必須是獨特的。
- 集合成員約束:列的名稱源自一組離散值,例如枚舉值。 例如,性別可以是男性、女性或其他。
- 外鍵約束:與關係數據庫系統一樣,外鍵列應該存在於引用的主鍵中。
- 正則表達式模式:文本字段應遵循特定設計。 例如,電話號碼需要服從特定的配置文件 (xxx) xxx-xxx。
- 跨領域驗證:跨越多個領域的特定設置必須保持,例如,患者的出院日期不能早於入院時間。
準確性
數據接近實際值的程度。 雖然概述所有可能的有效字段值可以很容易地發現無效值,但這並不意味著它們是準確的。
可能不存在有效的街道地址。 一個 人的眼睛顏色,比如藍色,可能是正確的,但不是正確的。 另一件不要忘記的事情是正確性和精確性之間的區別。
說你住在地球上是正確的。 但是,不精確。 地球上的什麼地方? 假設您住在特定的街道地址更準確。
完整性
所有需要的數據都被知道和吸收到的點。
由於各種原因,數據將丟失。 可以通過質疑來源來緩解這個問題。
可能性是,您要么會得到不同的答案,要么將難以再次確定。
一致性
數據在匹配數據集中或跨多個相似數據集的可靠程度。
當數據集中的兩個值相互矛盾時,就會發生不一致。
一個有效的 年齡,比如 10 歲,可能與婚姻狀況不匹配,比如離婚。 在具有兩個不同地址的兩個不同表中記錄客戶是不一致的。
哪一個是真的?
均勻度
指定的數據在何種程度上使用了相同的儀表單位。
以磅或公斤為單位的重量,以美國格式或歐洲格式表示的日期,以及有時以美元或日元表示的貨幣。