
Co to jest czyszczenie danych?
Opublikowany: 2021-11-18Firmy już dawno temu dostrzegły znaczenie danych, jeśli chodzi o zrozumienie swoich klientów i podejmowanie strategicznych decyzji w celu zwiększenia zwrotu z inwestycji.
Jednak w wyścigu o spersonalizowane produkty i rozwiązania, kluczowe fakty dotyczące jakości danych są pomijane, co prowadzi do błędnych wniosków analitycznych i kosztownych decyzji biznesowych.
Gartner mówi: „Średni wpływ finansowy niskiej jakości danych na organizacje wynosi 9,7 miliona dolarów rocznie”. Możesz poprawić jakość danych, zapewniając dokładne punkty wprowadzania danych, skuteczne łączenie danych, standaryzację danych i metody czyszczenia danych.
Praktyczne zastosowanie technik czyszczenia i wzbogacania danych może pomóc w tworzeniu, weryfikowaniu, aktualizowaniu, ulepszaniu i ulepszaniu danych o znaczeniu krytycznym dla firmy poprzez opracowywanie niestandardowych narzędzi (pająków, botów i skryptów) oraz procesów ręcznych.
Oto kilka implikacji złych danych:
- Ovum Research informuje, że niska jakość danych kosztuje firmy co najmniej 30% ich przychodów.
- Nieprawidłowe dane sprzedażowe skłaniają sprzedawców do marnowania czasu na martwe leady. Niedokładne dane mogą skierować firmę w stronę wypaczonych strategii.
- MarketingSherpa twierdzi, że co roku 25-30% danych ulega uszkodzeniu. Złe dane mogą dawać zniekształcone informacje o danych demograficznych klientów i zachowaniach zakupowych, co prowadziłoby do straconych okazji dla marketerów.
- Brak komunikacji jest ogromnym zniechęceniem dla klientów. Złe dane mogą przyczyniać się do nieporozumień z klientami, poczucia niezadowolenia wśród nich, a nawet negatywnego brandingu w mediach społecznościowych.
Co to jest czyszczenie danych?
Czyszczenie danych lub czyszczenie danych to metoda wykrywania i korygowania dewaluacji lub niedokładnych rekordów z zestawu rekordów, tabeli lub bazy danych. Odnosi się do wykrywania fragmentarycznych, błędnych, nieprecyzyjnych lub niepowiązanych części danych, a następnie zastępowania, modyfikowania lub usuwania brudnych lub szorstkich danych.
Czyszczenie danych może być wykonywane interaktywnie za pomocą rozwiązań do przetwarzania danych lub jako przetwarzanie wsadowe za pomocą skryptów. Po oczyszczeniu zbiór danych powinien być spójny z innymi podobnymi zbiorami danych w systemie.
Wykryte lub usunięte rozbieżności mogły być początkowo spowodowane niedokładnościami wprowadzanymi przez użytkownika, zniekształceniami transmisji lub przechowywania lub odmiennymi definicjami słownikowymi danych tych samych jednostek w różnych magazynach.
Oczyszczanie danych różni się od uwierzytelniania danych tym, że walidacja prawie niezmiennie oznacza, że dane są wykluczane z systemu przy przyjęciu i są uzyskiwane w momencie wprowadzania, a nie na zestawach danych.
Właściwa procedura czyszczenia danych może obejmować usuwanie błędów typograficznych lub uwierzytelnianie i korygowanie wartości w porównaniu ze znaną listą obiektów. Weryfikacja może być rygorystyczna (np. odrzucenie dowolnego adresu, który nie ma prawidłowego kodu pocztowego) lub rozmyta (np. poprawianie rekordów, które w pewnym stopniu pasują do istniejących, znanych kont).
Niektóre narzędzia do czyszczenia danych czyszczą dane, sprawdzając je z uwierzytelnionym zestawem danych. Typową praktyką czyszczenia danych jest wzbogacanie danych, w którym dane są uzupełniane przez dodanie powiązanych informacji — na przykład dołączenie lokalizacji z dowolnymi numerami telefonów powiązanymi z tym adresem.
Oczyszczanie danych może również obejmować synchronizację (lub normalizację) danych, czyli proces łączenia danych o „zmiennych formatach plików, nazewnictwa i kolumn” i zamiany ich w jeden spójny zestaw danych; prostym przykładem jest rozwinięcie akronimów.
Jak wyczyścić dane?
Czyste dane to podstawa ważnych badań i spostrzeżeń. Dlatego specjaliści ds. nauki danych spędzają 80% czasu na czyszczeniu i normalizacji danych. Czyszczenie danych opiera się na różnych podejściach.
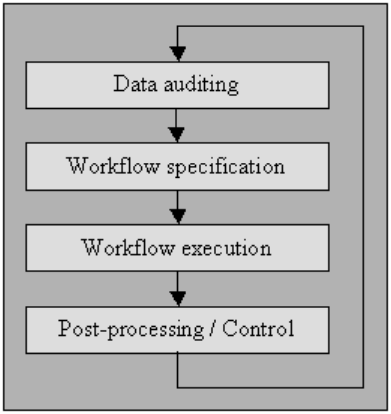
Audyt danych
Kontroluj dane za pomocą metod statystycznych i baz danych w celu wykrycia anomalii i sprzeczności: to ostatecznie wskazuje charakterystykę osobliwości i ich lokalizacji.
Kilka narzędzi pozwala postulować różnego rodzaju kontrole (za pomocą gramatyki imitującej standardowe kodowanie, takie jak JavaScript lub Visual Basic), a następnie generować kod, który bada dane pod kątem naruszenia tych ograniczeń.
Wyjaśniłem ten proces poniżej w „specyfikacji przepływu pracy”, a także „wykonywaniu przepływu pracy”. W przypadku użytkowników, którzy nie mają dostępu do zaawansowanych narzędzi czyszczących, mikrokomputerowe systemy zarządzania bazami danych, takie jak MS Access lub File Maker Pro, pozwolą również uzyskać takie uprawnienia na zasadzie limit-by-limit, interaktywnie z lekkim lub bez konieczności programowania w wielu sprawy.
Specyfikacja przepływu pracy
Przygotuj przepływ pracy do wykrywania i usuwania anomalii. Rozpoczyna się po procedurze audytu danych i ma kluczowe znaczenie dla uzyskania końcowego produktu wysokiej jakości danych. Stworzenie prawidłowego przepływu pracy wymaga ścisłego monitorowania przyczyn anomalii i błędów w danych.
Wykonanie przepływu pracy
Na tym etapie wykonaj przepływ pracy po zakończeniu jego wymagania i potwierdzeniu jego poprawności.
Stosowanie przepływu pracy powinno być dobrze zorganizowane, nawet w przypadku ogromnych zestawów danych, co nieuchronnie stanowi kompromis, ponieważ przeprowadzenie procesu czyszczenia danych może być kosztowne obliczeniowo.
Przetwarzanie końcowe i controlling
Po zakończeniu przepływu pracy czyszczenia sprawdź wyniki, aby zweryfikować poprawność. Dostosuj ręcznie nieprawidłowe dane pozostawione po wykonaniu przepływu pracy, jeśli jest to możliwe.
Wynikiem jest nowa sekwencja w procedurze czyszczenia danych, w której ponownie przeprowadzasz audyt danych, aby umożliwić wymaganie dodatkowego przepływu pracy w celu oczyszczenia danych przez dalsze automatyczne przetwarzanie.
Lepsza jakość danych źródłowych ma związek z „kulturą jakości danych”, a każda organizacja musi ją zainicjować na szczycie przedsiębiorstwa.
Nie chodzi tylko o wykonanie bezpiecznych kontroli walidacji na ekranach wejściowych, ponieważ prawie bez względu na to, jak bardzo są one ostrożne, użytkownicy często mogą je ominąć.

Istnieje dziewięcioetapowy przewodnik dla zakładów, które chcą poprawić jakość danych:
- Zadeklaruj gwarancję wysokiego poziomu w kulturze jakości danych
- Prowadź przeprojektowanie procedur na poziomie tworzenia polityki
- Wydaj ciasto, aby przyspieszyć ustawienie wprowadzania danych
- Wydawaj pieniądze na rozwój integracji aplikacji
- Poświęć pieniądze na zmianę sposobu funkcjonowania procesów
- Popieraj reakcję zespołu end-to-end
- Zachęcaj do współpracy międzywydziałowej
- Ujawnij publicznie wyższość jakości danych
- Nieustannie mierz i poprawiaj jakość danych
Inne składają się z:
Rozbiór gramatyczny zdania
do rozpoznawania błędów składniowych. Parser wybiera, czy ciąg danych jest akceptowalny w ramach dozwolonej specyfikacji danych. Jest to podobne do sposobu, w jaki parser trudzi się ze składniami i językami.
Transformacja danych
Transformacja danych pozwala na wykreślenie danych z danego formatu w układzie oczekiwanym przez odpowiednią aplikację. Zawiera konwersje wartości lub procedury translacji, a także standaryzację wartości liczbowych, aby podążać za wartościami minimalnymi i maksymalnymi.
Zduplikowana eliminacja
Wykrywanie duplikatów wymaga algorytmu określającego, czy dane zawierają duplikaty tej samej jednostki. Zazwyczaj dane są uporządkowane według klucza, który przybliża identyczne wpisy w celu szybszej identyfikacji.
metody statystyczne
Badając dane przy użyciu wartości średniej, odchylenia standardowego, zakresu lub procedur grupowania, ekspert może znaleźć wartości, które są nieoczekiwane, a tym samym nieprawidłowe.
Nawet jeśli korekta takich danych jest stroma, ponieważ rzeczywisty nominał nie jest znany, można go rozwiązać, ustawiając wartości na średnią lub inną wartość statystyczną.
Inne zastosowanie metod statystycznych musi obsługiwać utracone nominały, które można zastąpić jedną lub kilkoma możliwymi wartościami, które są zwykle uzyskiwane przez rozbudowane algorytmy wzbogacania danych.
Higiena danych lub Jakość danych
Aby dane mogły być przetwarzane i interpretowane efektywnie i wydajnie, muszą spełniać zestaw kryteriów jakości. Uważa się, że dane spełniające te kryteria jakości są wysokiej jakości. Ogólnie rzecz biorąc, zagregowaną wartością w zestawie kryteriów jakości jest jakość danych.
Zaczynając od kryteriów jakości określonych w, opisujemy zestaw standardów, na które ma wpływ kompleksowe czyszczenie danych i określamy, jak oceniać wyniki dla każdego z nich dla istniejącego zbioru danych.
Aby zmierzyć jakość zbioru danych, oceń oceny dla każdego z kryteriów jakości.
Korzystanie z oceny punktacji dla kryteriów jakości może być sposobem ilościowego określenia konieczności czyszczenia danych w celu zebrania danych, a także powodzenia przeprowadzonego procesu czyszczenia danych w celu zebrania danych.
Możesz użyć kryteriów jakości w optymalizacji czyszczenia danych, określając priorytety dla każdego z wymagań, co z kolei wpływa na wykonanie metod czyszczenia danych mających wpływ na określone reguły.
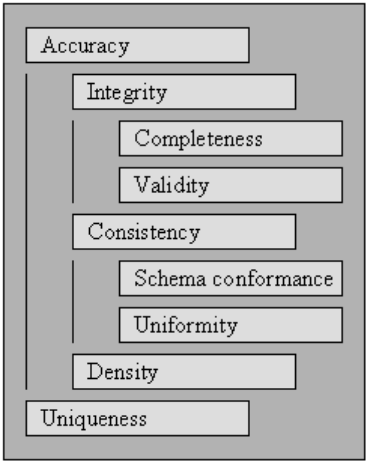
Ważność
Punkt, w którym dane pasują do zdefiniowanych reguł biznesowych lub ograniczeń.
- Ograniczenia typu danych: wartości w określonej kolumnie muszą być określonego typu danych, np. logiczne, numeryczne, daty itp.
- Ograniczenia zakresu: zazwyczaj liczby lub daty powinny mieścić się w określonym zakresie.
- Ograniczenia obowiązkowe : określone kolumny nie mogą być puste.
- Unikalne ograniczenia: pole lub połączenie obszarów musi być charakterystyczne w całym zestawie danych.
- Ograniczenia zestawu-członkostwa : nominały kolumny emanują ze zbioru wartości dyskretnych, np. wartości wyliczenia. Na przykład płeć może być męska, żeńska lub inna.
- Ograniczenia klucza obcego : tak jak w relacyjnych systemach baz danych, kolumna klucza obcego powinna istnieć w kluczu podstawowym, do którego się odwołuje.
- Wzorce wyrażeń regularnych: pola tekstowe powinny mieć określony projekt. Na przykład numery telefonów muszą być zgodne z określonym profilem (xxx) xxx-xxx.
- Walidacja międzypolowa: muszą obowiązywać określone ustawienia, które obejmują wiele pól, np. data zwolnienia pacjenta ze szpitala nie może przypadać przed czasem przyjęcia.
Precyzja
Stopień, w jakim dane są zbliżone do wartości rzeczywistych. Chociaż przedstawienie wszystkich możliwych prawidłowych wartości pól umożliwia łatwe wykrycie nieprawidłowych wartości, nie oznacza to jednak, że są one dokładne.
Prawidłowy adres pocztowy może nie istnieć. A kolor oczu danej osoby, powiedzmy niebieski, może być prawidłowy, ale niewłaściwy. Jeszcze jedna rzecz, o której nie należy zapominać, to różnica między poprawnością a precyzją.
Słuszne jest powiedzenie, że żyjesz na planecie Ziemia. Ale nie dokładnie. Gdzie na planecie? Założenie, że mieszkasz pod konkretnym adresem, jest dokładniejsze.
Kompletność
Punkt, do którego wszystkie wymagane dane są znane i przyswojone.
Brakuje danych z różnych przyczyn. Można złagodzić ten problem, kwestionując źródło.
Możliwości są takie, że albo otrzymasz inną odpowiedź, albo będziesz miał trudności z ponownym ustaleniem.
Spójność
Stopień, w jakim dane są niezawodne, w pasującym zestawie danych lub w kilku podobnych zestawach danych.
Niespójność ma miejsce, gdy dwie wartości w zestawie danych są ze sobą sprzeczne.
Prawidłowy wiek, powiedzmy, 10 lat, może nie pasować do stanu cywilnego, powiedzmy rozwiedziony. Zapisywanie klienta w dwóch różnych tabelach z dwoma oddzielnymi adresami to niespójność.
Który z nich jest prawdziwy?
Jednolitość
Stopień, w jakim określone dane wykorzystują tę samą jednostkę miernika.
Waga w funtach lub kilogramach, data w formacie amerykańskim lub europejskim, a waluta czasami w USD lub YEN.