
Cum poate determina Google entități locale similare
Publicat: 2018-01-30
Căutarea locală este plină de entități locale cu semnificație locală
Căutarea locală Google se bazează mai mult pe semantică decât căutarea organică; unde companiile sunt adesea denumite „entități locale”, ca într-un brevet care a fost acordat Google la 2 ianuarie 2018. Este mai degrabă o luare în considerare a diferitelor lucruri (ca în „Lucruri și nu șiruri”), mai degrabă decât a potrivirii cuvinte cheie pe pagini. În parte, acesta este motivul pentru care vedem panouri de cunoștințe pentru companii în aceste zile la Google, după ce acestea și-au prezentat Knowledge Graph, care arată entitățile. Definiția lor a unei entități locale, sub acel brevet, este interesantă:
Unele sisteme de căutare pot obține sau deduce o locație a unui dispozitiv utilizator de la care a fost primită o interogare de căutare și includ rezultate de căutare locale care răspund la interogarea de căutare. Un rezultat de căutare locală este un rezultat de căutare care face referire la un document care descrie o entitate locală. O entitate locală, la rândul său, este o entitate care a fost clasificată ca având semnificație locală pentru o anumită locație. Entitățile locale sunt de obicei entități fizice asociate cu o adresă sau o regiune, cum ar fi un restaurant, un spital, un punct de reper și altele asemenea. Un rezultat al căutării care face referire la un document care descrie o entitate locală primește un scor de căutare „boost” pentru o interogare dacă locația asociată cu entitatea locală este aproape de locația dispozitivului utilizatorului. De exemplu, ca răspuns la o interogare de căutare pentru „cafenea”, sistemul de căutare poate oferi rezultate de căutare locale care fac referire la pagini web pentru cafenele din apropierea locației dispozitivului utilizatorului. Mulți utilizatori din diferite regiuni geografice vor fi probabil mulțumiți să primească rezultate locale pentru cafenele ca răspuns la interogarea de căutare „cafenea”, deoarece este probabil ca un utilizator care trimite interogarea „cafenea” să fie interesat de rezultatele căutării pentru cafenele care sunt locale pentru locația utilizatorului.
Afișarea entităților locale similare este un obiectiv
Acest nou brevet nu se referă doar la clasarea entităților locale ca răspuns la o interogare care este relevantă pentru acele entități. De asemenea, ne spune că unele căutări vor oferi rezultate de căutare care se bazează pe afișarea unor rezultate similare, ceea ce este, de asemenea, interesant:
În contextul entităților locale, de exemplu, motoarele de căutare pot furniza rezultate de căutare pentru entitățile locale care sunt legate între ele într-un mod predeterminat. De exemplu, în contextul restaurantelor, sugestiile pentru alte restaurante care oferă articole similare din meniu la prețuri similare pot fi făcute ca răspuns la o selecție de rezultat al căutării care face referire la primul restaurant sau ca răspuns la o căutare a altor restaurante legate de un primul restaurant.
Dacă sunteți în căutarea unui loc unde să vă opriți și să luați o cafea, fiind capabil să vedeți mai multe cafenele în apropiere, chiar și unele care ar putea fi mai departe vă pot face posibil să decideți pe ce doriți să vizitați chiar dacă una este mai aproape, iar altele sunt ceva mai îndepărtat. Întrebarea pe care am avut-o când am început să citesc aceasta este ce ar putea folosi Google pentru a decide dacă diferite entități sunt similare? Cum au determinat asta? Cum decid dacă o entitate locală are semnificație locală pentru o locație geografică?
Brevetul ne spune că mai multe lucruri fac ca procesul din acest brevet să aibă aspecte inovatoare. Acestea includ:
1) Accesarea datelor care specifică, pentru fiecare entitate locală dintr-un set de entități locale, în care fiecare entitate locală este o entitate fizică rezolvată într-o locație geografică și având o semnificație locală pentru locația geografică pe baza termenilor de interogare care se rezolvă în selecțiile de entități locale din o locatie.
2) Determinarea unei măsuri de similaritate care este o măsură a similitudinii unei entități locale identificate și a unor entități locale similare; asemănările lor pot fi suficiente pentru a le considera ca fiind înrudite.
Brevetul este:
Detectarea entităților locale aferente
Inventatori: Kumar Mayur Thakur și Mukund Jha
Cesionar: Google Inc.
Brevetul SUA 9.858.291
Acordat: 2 ianuarie 2018
Depus: 30 octombrie 2014
Abstract
Metode, sisteme și aparate, inclusiv programe de calculator codificate pe un mediu de stocare computerizat, pentru procesarea entităților locale. Într-un aspect, o metodă include accesarea datelor care specifică termeni de interogare pentru fiecare entitate locală dintr-un set de entități locale și pentru fiecare termen de interogare o valoare a termenului bazată pe multe instanțe de interogări care includ termenul de interogare care apare într-un jurnal de interogare și o valoare de selecție pe baza mai multor selecții de rezultate de căutare care fac referire fiecare la entitatea locală ca răspuns la o interogare care include termenul de interogare și atribuit termenului de interogare; selectarea unei prime entități locale din setul de entități locale; selectarea unui subset de a doua entități locale din setul de entități locale; şi pentru fiecare a doua entitate locală din subset, determinarea unei măsuri de similitudine a celei de-a doua entităţi locale cu prima entitate locală.
Cum sunt determinate asemănările pentru entitățile locale?
Rezultatele locale din Hărți Google sunt clasate pe baza unor elemente precum distanța față de istoricul locațiilor mobile, relevanța titlului unei companii pentru o interogare care o caută și un scor de proeminență a locației, pe baza citărilor (și linkurile și recenziile pot conta ca citate.) și un scor de autoritate pentru un site web pentru afaceri.
Acest nou brevet ne spune că Google poate afișa site-uri similare pentru a însoți un anumit rezultat local, pentru a oferi unui căutător opțiuni și opțiuni de locuri de vizitat. Acesta explică modul în care este determinată asemănarea, în ceea ce privește privirea la cuvintele care apar în interogări și descrieri:
Măsura similarității se bazează, parțial, pe datele termenilor de interogare pentru fiecare entitate locală. Un termen de interogare, așa cum este utilizat în această descriere scrisă, poate fi un n-gramă care constituie parte a unei interogări, dar nu trebuie să fie o interogare întreagă. De exemplu, pentru interogarea „Restaurant Review Gino’s”, termenii de interogare pot fi unigramele „Restaurant”, „Review” și „Gino’s”. Alte n-grame, cum ar fi bi-grame, tri-grame etc., pot fi, de asemenea, utilizate ca termeni de interogare.
Pe lângă căutarea asemănărilor lingvistice, Google poate căuta și entități locale similare pe o rază de un anumit număr de mile. Acest lucru mă face să mă gândesc la câte companii similare ar putea fi în apropierea unei companii pe care aș dori să apară în rezultatele căutării locale și cât de asemănătoare ar putea părea.
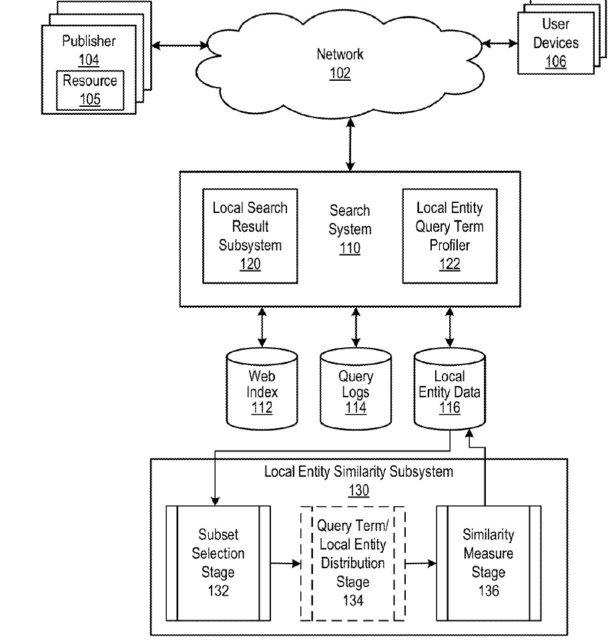
Căutarea locală are un subsistem similar de entitate locală care învață din jurnalele de interogări
Când ne gândim la căutare pe Google, de obicei ne gândim la căutare organică care utilizează scorurile de regăsire a informațiilor pentru a determina relevanța rezultatelor căutării pentru o interogare pe care o efectuează un utilizator și scoruri de autoritate pentru acele rezultate. Acest brevet vorbește despre un subsistem similar de entitate locală pentru atunci când rezultatele locale sunt procesate:
La procesarea rezultatelor locale, asemănarea entităților locale cu alte entități locale poate fi utilizată atunci când se determină scorurile de căutare ale documentelor care fac referire la entitățile locale. De asemenea, dacă sistemul de căutare este utilizat pentru a căuta entități locale independente de documente (de exemplu, de exemplu, o căutare de restaurante), asemănarea entităților locale cu alte entități locale poate fi, de asemenea, utilizată atunci când se determină ce entități locale să enumere ca răspuns la un interogare de entitate locală. în consecinţă, sistemul de căutare poate include, sau poate fi în comunicare de date cu, un subsistem de similitudine de entitate locală. Subsistemul similaritate entități locale determină, pentru fiecare entitate locală, o listă corespunzătoare de entități locale similare care include o listă de entități locale clasificate în funcție de asemănarea lor cu entitatea locală căreia îi corespunde lista.

Asemănările dintre entitățile locale pot fi determinate parțial prin analizarea apariției jurnalului de interogări cu privire la cât de des poate apărea o afacere în rezultatele jurnalului de interogări pentru anumiți termeni care pot fi similari:
Procesul accesează date specificând, pentru fiecare entitate locală dintr-un set de entități locale, valori ale termenilor și valori de selecție pentru termenii de interogare (202). Valoarea termenului este proporțională cu mai multe instanțe de interogări care includ termenul de interogare care apare într-un jurnal de interogări. De exemplu, să presupunem că interogările „Restaurants NYC Italian” și „Italian Restaurants Manhattan” apar fiecare de N ori într-un jurnal de interogări. Pe baza acestor două interogări și a cazurilor respective, valoarea termenului pentru „Restaurante” este proporțională cu 2N, în timp ce valorile termenilor pentru „NYC”, „italian” și „Manhattan” sunt proporționale cu N.
Selectările anumitor pagini care menționează entități ca răspuns la interogări similare ar putea ajuta la determinarea care companii ar putea fi similare într-o căutare locală? Acest lucru poate depinde de cât de importantă poate fi acea entitate pentru pagina respectivă. Brevetul pare să descrie acest lucru:
Valoarea selecției este proporțională cu multe selecții de rezultate ale căutării, fiecare specifică o entitate locală ca răspuns la o interogare care include termenul de interogare și atribuită termenului de interogare. De exemplu, să presupunem că rezultatele căutării, fiecare care face referire la un document, sunt furnizate ca răspuns la o interogare de căutare. Pentru fiecare selecție a unui rezultat de căutare care face referire la un document care, la rândul său, face referire la o entitate locală, valoarea de selecție pentru termenii de interogare ai interogării este mărită pentru acea entitate locală. Cât de mult este mărită valoarea selecției poate depinde, în unele implementări, de scorul care descrie cât de importantă este entitatea pentru subiectul documentului. De exemplu, pentru primul document care enumeră sute de restaurante, descrise mai sus și care are un scor relativ scăzut pentru fiecare entitate de restaurant, o valoare de selecție a termenului de interogare pentru un anumit termen de interogare și o entitate locală ar crește foarte puțin ca răspuns la o selecție a unui rezultat de căutare care face referire la document. În schimb, pentru al doilea document care are un punctaj ridicat pentru entitatea locală, o valoare de selecție a termenului de interogare pentru termenul de interogare particular și entitatea locală ar fi crescută mult mai mult decât pentru selecția primului document local.
Distanțele entităților locale similare pot varia în importanță în funcție de tipul de afacere
Entitățile locale similare pot fi afișate în funcție de tipul de afaceri implicate. Cât de departe ai merge până la o pizzerie? Pentru o benzinărie?
Brevetul pune și aceste întrebări:
Selectarea unui subset adecvat de a doua entități locale din setul de entități locale poate implica, de exemplu, selectarea entităților locale care au o locație geografică într-o distanță de prag față de locația geografică a primei entități locale. Distanța prag poate fi o distanță fixă sau poate varia în funcție de tipul de entitate locală. De exemplu, pentru prima entitate de tip restaurant, distanța poate fi de 10 mile; pentru prima entitate de tip benzinărie, distanța poate fi de trei mile; etc.
De asemenea, oferă câteva răspunsuri cu privire la acele distanțe:
Distanța se poate baza și pe un timp estimat de călătorie. De exemplu, atunci când este selectată o primă entitate locală, pot fi selectate toate celelalte entități locale într-un interval estimat de 20 de minute cu mașina. Astfel, în funcție de limitele geografice (de exemplu, poduri, râuri etc.), zona din care sunt selectate alte entități locale poate fi asimetrică, și nu pur și simplu circulară sau dreptunghiulară. Distanța bazată pe timp poate fi determinată, de exemplu, din modelele de trafic obținute din sisteme externe fazei de selecție a subsetului și algoritmi de găsire a căii.
Termenii de interogare utilizați pentru a determina similitudinea pot fi de înaltă calitate și de calitate scăzută și uitați-vă la Numerele de selecție a clicurilor
Când se compară termenii de interogare pentru care pot fi găsite diferite locuri, unii dintre acești termeni sunt considerați termeni de înaltă calitate, cum ar fi termenii care indică categorii, cum ar fi „mâncare”. Unii termeni de interogare pot fi considerați de calitate inferioară, cum ar fi termenii de locație sau termenii de navigare.
Un termen de locație folosit într-o interogare, cum ar fi „NYC” poate apărea în interogări precum „pizza NYC” sau „Chinese Food NYC”, dar asta nu indică asemănări cu modul în care un termen precum „pizza” indică un restaurant care servește în mod special pizza. Un termen de interogare care ar putea fi folosit ca termeni de navigare, cum ar fi numele unui cartier sau numele unui centru comercial, cum ar fi „Lombardi’s”. Este posibil ca entitățile locale din același centru comercial sau cartier să nu fie foarte asemănătoare. Prezența acelor termeni de interogare într-un jurnal de interogări pentru comparație poate fi mai utilă pentru termenii de calitate superioară decât cei de calitate inferioară. Două locuri care sunt identificate ca fiind găsite pentru „fructe de mare” sunt probabil mai asemănătoare decât două locuri care sunt găsite pentru „NYC”.
Brevetul aprofundează mult mai mult în ceea ce privește calitatea termenilor de interogare și termenii de categorie comparativ cu termenii care indică o locație sau o tendință de navigare. Ei par să favorizeze categoriile ca tipul de termen de interogare care indică asemănarea entităților locale.
Dar pot acorda atenție atât termenilor de interogare de înaltă calitate, cât și de calitate scăzută, mai ales atunci când selecțiile pentru acești termeni sunt similare:
O „asemănare” a valorilor de selecție relative înseamnă că distribuția selecțiilor pentru un termen de interogare este similară. De exemplu, să presupunem că o primă entitate este un restaurant și o a doua este un cazinou. Ambele entități pot avea 5.000 de clicuri din interogările cu termenul „restaurant”, dar entitatea restaurant are 7.000 de clicuri totale din toate interogările care i-au fost atribuite, în timp ce cazinoul are 1.000.000 de clicuri totale din toate interogările care i-au fost atribuite. Deoarece distribuțiile relative sunt foarte diferite, există foarte puțină similitudine atribuită termenului „restaurant” pentru aceste două entități. În schimb, o altă entitate cu 4.000 de clicuri din interogări cu termenul „restaurant”, 6.000 de clicuri totale ar fi considerate a fi similare cu entitatea restaurant pentru termenul „restaurant”. De asemenea, o altă entitate cu 6.000 de clicuri din interogări cu termenul „restaurant” și 975.000 de clicuri totale ar fi considerată a fi similară cu entitatea cazinou pentru termenul „restaurant”.
Această utilizare a selecțiilor din toate tipurile de interogări poate indica dacă două locuri diferite pot fi similare sau foarte diferite unele de altele. Aceasta nu este utilizarea informațiilor de clic pentru a determina cum să clasifice entitățile, ci mai degrabă pentru a decide dacă să arate că două entități locale sunt similare sau nu.