
Googleが同様のローカルエンティティを決定する方法
公開: 2018-01-30
ローカル検索は、ローカルに重要なローカルエンティティでいっぱいです
Googleのローカル検索は、オーガニック検索よりもセマンティックベースです。 2018年1月2日にGoogleに付与された特許のように、企業は「ローカルエンティティ」と呼ばれることがよくあります。これは、マッチングではなく、さまざまなこと(「文字列ではなく物」など)を考慮することです。ページ上のキーワード。 一部には、エンティティを示すナレッジグラフを導入した後、最近Googleで企業向けのナレッジパネルが表示されるのはそのためです。 その特許の下でのローカルエンティティの彼らの定義は興味深いです:
一部の検索システムは、検索クエリを受信したユーザーデバイスの場所を取得または推測し、検索クエリに応答するローカル検索結果を含めることができます。 ローカル検索結果は、ローカルエンティティを説明するドキュメントを参照する検索結果です。 次に、ローカルエンティティは、特定の場所に対してローカルの重要性を持つものとして分類されたエンティティです。 ローカルエンティティは通常、レストラン、病院、ランドマークなど、住所または地域に関連付けられた物理エンティティです。 ローカルエンティティを説明するドキュメントを参照する検索結果は、ローカルエンティティに関連付けられた場所がユーザーデバイスの場所の近くにある場合、クエリの検索スコア「ブースト」を受け取ります。 例えば、「コーヒーショップ」の検索クエリに応答して、検索システムは、ユーザデバイスの場所の近くのコーヒーショップのウェブページを参照するローカル検索結果を提供することができる。 さまざまな地域の多くのユーザーは、「コーヒーショップ」という検索クエリを送信したユーザーが、「コーヒーショップ」という検索結果に関心を持っている可能性が高いため、「コーヒーショップ」という検索クエリに対してローカルの結果を受け取ることに満足する可能性があります。ユーザーの場所に対してローカルです。
類似のローカルエンティティを表示することが目標です
この新しい特許は、ローカルエンティティに関連するクエリに応答してローカルエンティティをランク付けすることだけではありません。 また、一部の検索では、同様の結果の表示に基づく検索結果が提供されることもわかります。これも興味深いことです。
たとえば、ローカルエンティティのコンテキストでは、検索エンジンは、何らかの所定の方法で相互に関連するローカルエンティティの検索結果を提供する場合があります。 たとえば、レストランのコンテキストでは、最初のレストランを参照する検索結果の選択に応じて、またはに関連する他のレストランの検索に応じて、同様のメニュー項目を同様の価格で提供する他のレストランの提案を行うことができます。最初のレストラン。
立ち寄ってコーヒーを飲む場所を探しているなら、近くにいくつかの喫茶店を見ることができます。遠くにあるものでも、近くにあるものと近くにあるものがある場合でも、どちらに行きたいかを決めることができる場合があります。もう少し遠い。 私がこれを読み始めたときに私が持っていた質問は、異なるエンティティが類似しているかどうかを判断するためにGoogleが何を使用する可能性があるかということです。 彼らはどうやってそれを決定したのですか? ローカルエンティティが地理的な場所に対してローカルな重要性を持っているかどうかをどのように判断しますか?
この特許は、いくつかのことがこの特許のプロセスに革新的な側面を持たせることを示しています。 これらには以下が含まれます:
1)一連のローカルエンティティ内の各ローカルエンティティについて、地理的位置に解決された物理エンティティであり、ローカルエンティティの選択で解決されるクエリ用語に基づいて地理的位置に対してローカルな重要性を持つことを指定するデータにアクセスする場所。
2)識別されたローカルエンティティと類似のローカルエンティティの類似性の尺度である類似性尺度を決定する。 それらの類似性は、それらが関連していると見なすのに十分かもしれません。
特許は次のとおりです。
関連するローカルエンティティの検出
発明者:Kumar MayurThakurおよびMukundJha
譲受人:Google Inc.
米国特許9,858,291
付与:2018年1月2日
提出日:2014年10月30日
概要
ローカルエンティティを処理するための、コンピュータ記憶媒体にエンコードされたコンピュータプログラムを含む方法、システム、および装置。 一態様では、方法は、一連のローカルエンティティ内の各ローカルエンティティおよび各クエリ用語について、クエリログで発生するクエリ用語を含むクエリの多くのインスタンスに基づく用語値、および選択値を指定するデータにアクセスすることを含む。クエリ用語を含み、クエリ用語に起因するクエリに応答して、それぞれがローカルエンティティを参照する検索結果のいくつかの選択に基づく。 ローカルエンティティのセットから最初のローカルエンティティを選択します。 ローカルエンティティのセットから2番目のローカルエンティティのサブセットを選択します。 そして、サブセット内の第2のローカルエンティティごとに、第2のローカルエンティティと第1のローカルエンティティとの類似性の尺度を決定する。
ローカルエンティティの類似性はどのように決定されますか?
Googleマップのローカル検索結果は、モバイルロケーション履歴からの距離、ビジネスのタイトルとそれを検索するクエリとの関連性、引用に基づくロケーションプロミネンススコアなどに基づいてランク付けされます(リンクとレビューは次のようにカウントできます)。引用。)およびビジネス用Webサイトの権限スコア。
この新しい特許は、Googleが特定のローカル検索結果に付随する同様のサイトを紹介し、検索者に訪問する場所のオプションと選択肢を提供する可能性があることを示しています。 クエリや説明に表示される単語を見て、類似性がどのように決定されるかを説明します。
類似性の尺度は、一部、各ローカルエンティティのクエリ用語データに基づいています。 この記述で使用されているクエリ用語は、クエリの一部を構成するn-gramにすることができますが、クエリ全体である必要はありません。 たとえば、クエリ「Restaurant Review Gino's」の場合、クエリ用語はユニグラム「Restaurant」、「Review」、および「Gino's」の場合があります。 バイグラム、トリグラムなどの他のnグラムも、クエリ用語として使用できます。
Googleは、言語の類似性を探すだけでなく、特定のマイル数の半径内にある類似のローカルエンティティも探す場合があります。 これにより、ローカル検索結果に表示したいと思う可能性のあるビジネスの近くに類似するビジネスがいくつあるのか、そしてそれらがどれほど類似しているように見えるのかを考えることができます。
ローカル検索には、クエリログから学習する同様のローカルエンティティサブシステムがあります
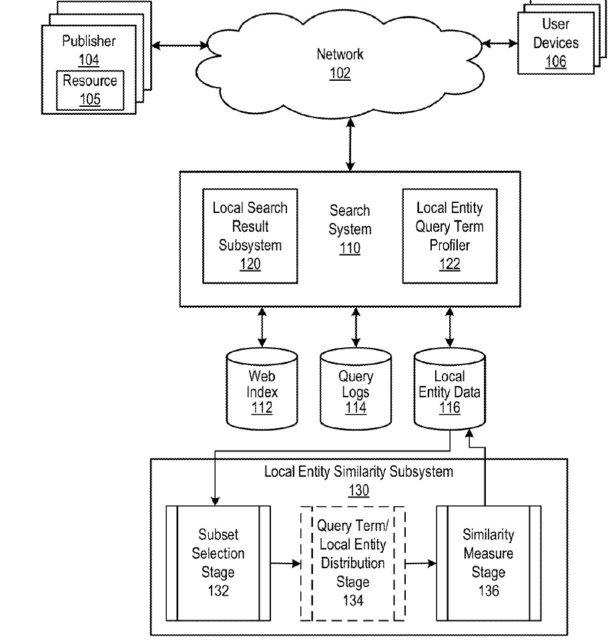
Googleでの検索について考えるとき、私たちは通常、情報検索スコアを使用して、検索者が実行するクエリに対する検索結果の関連性と、それらの結果の権限スコアを決定する有機検索を考えます。 この特許は、ローカル結果が処理されるときの同様のローカルエンティティサブシステムについて説明しています。

ローカル結果を処理する場合、ローカルエンティティを参照するドキュメントの検索スコアを決定するときに、ローカルエンティティと他のローカルエンティティの類似性を使用できます。 同様に、検索システムを使用してドキュメントとは無関係にローカルエンティティを検索する場合(たとえば、レストランの検索など)、ローカルエンティティと他のローカルエンティティの類似性を使用して、ローカルエンティティクエリ。 したがって、検索システムは、ローカルエンティティ類似性サブシステムを含むか、またはそれとデータ通信することができる。 ローカルエンティティ類似性サブシステムは、各ローカルエンティティについて、リストが対応するローカルエンティティとの類似性に従ってランク付けされたローカルエンティティのリストを含む、類似するローカルエンティティの対応するリストを決定します。
ローカルエンティティ間の類似性は、類似している可能性のある特定の用語のクエリログ結果にビジネスが表示される頻度のクエリログの外観を調べることによって部分的に判断できます。
プロセスは、ローカルエンティティのセット内のローカルエンティティごとに、用語値、およびクエリ用語の選択値を指定するデータにアクセスします(202)。 用語の値は、クエリログで発生するクエリ用語を含むクエリのいくつかのインスタンスに比例します。 たとえば、クエリ「RestaurantsNYCItalian」と「ItalianRestaurantsManhattan」がそれぞれクエリログにN回表示されるとします。 これらの2つのクエリとそれぞれのインスタンスに基づいて、「レストラン」の用語値は2Nに比例し、「NYC」、「イタリア語」、「マンハッタン」の用語値はNに比例します。
類似のクエリに応答してエンティティに言及している特定のページを選択すると、ローカル検索で類似している可能性のあるビジネスを特定するのに役立ちますか? それは、そのエンティティがそのページにとってどれほど重要であるかによって異なります。 特許はその出来事を説明しているようです:
選択値は、検索結果の多くの選択に比例し、それぞれがクエリ用語を含み、クエリ用語に起因するクエリに応答してローカルエンティティをそれぞれ指定します。 たとえば、それぞれがドキュメントを参照する検索結果が、検索クエリに応答して提供されると仮定します。 ローカルエンティティを参照するドキュメントを参照する検索結果を選択するたびに、そのローカルエンティティのクエリのクエリ用語の選択値が増加します。 選択値がどれだけ増加するかは、一部の実装では、エンティティがドキュメントの主題にとってどれほど重要であるかを表すスコアに依存する場合があります。 たとえば、上記の数百のレストランをリストし、各レストランエンティティのスコアが比較的低い最初のドキュメントの場合、特定のクエリ用語とローカルエンティティのクエリ用語選択値は、選択に応じてほとんど増加しません。ドキュメントを参照する検索結果の。 逆に、ローカルエンティティのスコアが高い2番目のドキュメントの場合、特定のクエリ用語とローカルエンティティのクエリ用語選択値は、最初のローカルドキュメントの選択よりもはるかに大きくなります。
類似のローカルエンティティの距離は、業種に応じて重要性が異なる場合があります
関係する事業の種類に基づいて、同様のローカルエンティティが表示される場合があります。 ピザ屋まで車でどこまで行きますか? ガソリンスタンドの場合は?
特許はそれらの質問もします:
ローカルエンティティのセットから第2のローカルエンティティの適切なサブセットを選択することは、例えば、第1のローカルエンティティの地理的位置の閾値距離内に地理的位置を有するローカルエンティティを選択することを含み得る。 しきい値距離は、固定距離にすることも、ローカルエンティティタイプに基づいて変更することもできます。 たとえば、レストランタイプの最初のエンティティの場合、距離は10マイルになります。 ガソリンスタンドタイプの最初のエンティティの場合、距離は3マイルになる可能性があります。 等
また、それらの距離に関するいくつかの回答も提供します。
距離は、推定移動時間に基づくこともできます。 たとえば、最初のローカルエンティティが選択されると、推定20分以内の他のすべてのローカルエンティティが選択される場合があります。 したがって、地理的な境界(たとえば、橋、川など)に応じて、他のローカルエンティティが選択される領域は非対称であり、単純な円形や長方形ではありません。 時間ベースの距離は、たとえば、サブセット選択ステージの外部のシステムおよびパスファインディングアルゴリズムから取得されたトラフィックパターンから決定できます。
類似性を判断するために使用されるクエリ用語は、高品質と低品質の可能性があり、クリック選択番号を確認します
さまざまな場所が見つかる可能性のあるクエリ用語を比較すると、「食品」などのカテゴリを示す用語など、それらの用語の一部は高品質の用語と見なされます。 場所の用語やナビゲーションの用語など、一部のクエリ用語は品質が低いと見なされる場合があります。
「NYC」などのクエリで使用される場所の用語は、「pizzaNYC」や「ChineseFoodNYC」などのクエリに表示される場合がありますが、「pizza」などの用語がレストランを示すように類似性を示すものではありません。特にピザを提供しています。 近所の名前やショッピングセンターの名前など、ナビゲーション用語として使用される可能性のあるクエリ用語は、「Lombardi's」などの可能性があります。 同じショッピングセンターまたは近隣のローカルエンティティは、あまり類似していない場合があります。 比較のためにクエリログにこれらのクエリ用語が含まれていると、品質の低い用語よりも品質の高い用語の方が役立つ場合があります。 「シーフード」で見つかった2つの場所は、「NYC」で見つかった2つの場所よりも類似している可能性があります。
この特許は、クエリ用語の品質、およびカテゴリ用語と場所またはナビゲーションの偏りを示す用語との比較について、さらに深く掘り下げています。 それらは、ローカルエンティティの類似性を示すクエリ用語のタイプとしてカテゴリを好むようです。
ただし、特にこれらの用語の選択が類似している場合は、高品質と低品質の両方のクエリ用語に注意を払う可能性があります。
相対選択値の「類似性」は、クエリ用語の選択の分布が類似していることを意味します。 たとえば、最初のエンティティがレストランで、2番目のエンティティがカジノであるとします。 どちらのエンティティも「レストラン」という用語のクエリから5,000回のクリックがありますが、レストランのエンティティはそれに起因するすべてのクエリから合計7,000回のクリックがあり、カジノはそれに起因するすべてのクエリから合計1,000,000回のクリックがあります。 相対的な分布が非常に異なるため、これら2つのエンティティの「レストラン」という用語に起因する類似性はほとんどありません。 逆に、「レストラン」という用語のクエリから4,000回クリックされた別のエンティティでは、合計6,000回のクリックが、「レストラン」という用語のレストランエンティティと同様であると見なされます。 同様に、「レストラン」という用語のクエリからのクリック数が6,000で、合計クリック数が975,000のさらに別のエンティティは、「レストラン」という用語のカジノエンティティと同様であると見なされます。
すべてのクエリタイプからの選択をこのように使用すると、2つの異なる場所が互いに類似しているか非常に異なっているかを指摘できます。 これは、クリックスルー情報を使用してエンティティのランク付け方法を決定するのではなく、2つのローカルエンティティが類似しているかどうかを示すかどうかを決定します。