
Google 如何确定类似的本地实体
已发表: 2018-01-30
本地搜索充满了具有本地意义的本地实体
与自然搜索相比,Google 的本地搜索更基于语义; 企业通常被称为“本地实体”,例如在 2018 年 1 月 2 日授予谷歌的专利。它更多的是考虑不同的事物(如“事物而不是字符串”),而不是匹配页面上的关键字。 在某种程度上,这就是为什么我们在 Google 推出了展示实体的知识图谱后,如今在 Google 上看到了企业知识面板的原因。 根据该专利,他们对本地实体的定义很有趣:
一些搜索系统可以获得或推断从其接收搜索查询的用户设备的位置并且包括响应于搜索查询的本地搜索结果。 本地搜索结果是引用描述本地实体的文档的搜索结果。 反过来,本地实体是已被归类为对特定位置具有本地重要性的实体。 本地实体通常是与地址或区域相关联的物理实体,例如餐厅、医院、地标等。 如果与本地实体相关联的位置靠近用户设备的位置,则引用描述本地实体的文档的搜索结果接收查询的搜索分数“提升”。 例如,响应于对“咖啡店”的搜索查询,搜索系统可以提供本地搜索结果,其引用用户设备位置附近的咖啡店的网页。 不同地理区域的许多用户可能会对响应搜索查询“coffee shop”而收到有关咖啡店的本地结果感到满意,因为提交查询“coffee shop”的用户很可能对咖啡店的搜索结果感兴趣是用户所在位置的本地。
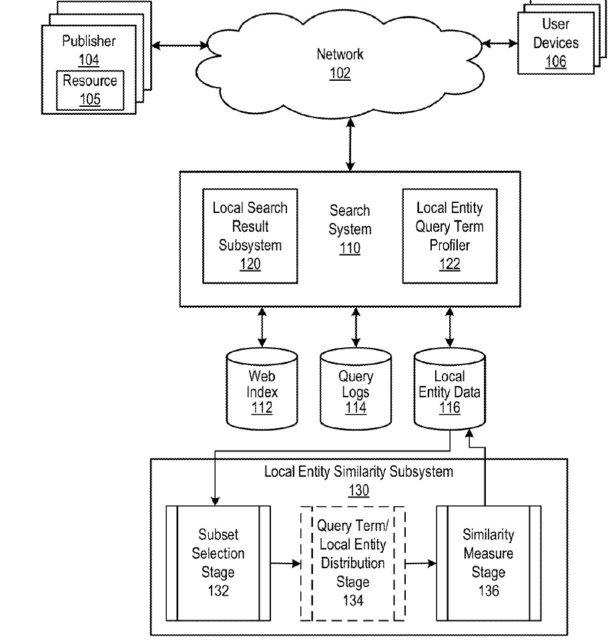
显示相似的本地实体是一个目标
这项新专利不仅仅是根据与这些实体相关的查询对本地实体进行排名。 它还告诉我们,某些搜索将提供基于显示相似结果的搜索结果,这也很有趣:
例如,在本地实体的上下文中,搜索引擎可以为以某种预定方式彼此相关的本地实体提供搜索结果。 例如,在餐馆的上下文中,可以响应于对引用第一家餐馆的搜索结果的选择,或者响应于对与某个餐馆相关的其他餐馆的搜索,对以相似价格提供相似菜单项的其他餐馆提出建议。第一家餐厅。
如果您正在寻找一个可以停下来喝杯咖啡的地方,能够看到附近的几家咖啡馆,即使有些可能更远,也可以让您决定要去哪个,即使一个更近一些稍微远一点。 当我开始阅读本文时,我的问题是 Google 可能会使用什么来确定不同的实体是否相似? 他们是如何确定的? 他们如何确定当地实体对某个地理位置是否具有当地意义?
该专利告诉我们,有几件事使该专利中的工艺具有创新性。 这些包括:
1) 访问为一组本地实体中的每个本地实体指定的数据,其中每个本地实体是解析为地理位置的物理实体,并且基于在本地实体的选择中解析的查询词对该地理位置具有本地意义一个位置。
2) 确定相似性度量,即已识别本地实体与相似本地实体的相似性度量; 它们的相似性可能足以将它们视为相关。
该专利是:
检测相关本地实体
发明人:Kumar Mayur Thakur 和 Mukund Jha
受让人:谷歌公司
美国专利 9,858,291
授予时间:2018 年 1 月 2 日
提交时间:2014 年 10 月 30 日
抽象的
用于处理本地实体的方法、系统和装置,包括在计算机存储介质上编码的计算机程序。 在一个方面,一种方法包括访问数据,该数据为一组本地实体中的每个本地实体指定查询项,并为每个查询项指定基于许多查询实例的项值,这些查询包括出现在查询日志中的查询项,以及选择值基于多个搜索结果选择,每个搜索结果都引用本地实体以响应包含查询词并归属于该查询词的查询; 从本地实体集合中选择第一个本地实体; 从本地实体集合中选择第二本地实体的子集; 并且对于子集中的每个第二本地实体,确定第二本地实体与第一本地实体的相似性度量。
如何确定本地实体的相似性?
Google 地图中的本地结果根据以下因素进行排名,例如与移动位置历史记录的距离、企业名称与查找它的查询的相关性以及基于引用的位置显着性得分(链接和评论可以算作引文。)和商业网站的权威评分。
这项新专利告诉我们,谷歌可能会展示类似的网站,以配合特定的本地结果,为搜索者提供选项和访问地点的选择。 它从查看查询和描述中出现的单词的角度解释了如何确定相似性:
相似性度量部分基于每个本地实体的查询词数据。 在此书面描述中使用的查询词可以是构成查询一部分的 n-gram,但不必是整个查询。 例如,对于查询“Restaurant Review Gino's”,查询词可能是一元组“Restaurant”、“Review”和“Gino's”。 其他 n-gram,例如 bi-gram、tri-gram 等,也可以用作查询词。
除了寻找语言相似性之外,谷歌还可能在一定英里数的半径范围内寻找相似的本地实体。 这让我思考在我可能希望出现在本地搜索结果中的企业附近可能有多少类似的企业,以及这些企业的相似程度。
本地搜索有一个类似的本地实体子系统,它从查询日志中学习
当我们想到 Google 的搜索时,我们通常会想到有机搜索,它使用信息检索分数来确定搜索结果与搜索者执行的查询的相关性,以及这些结果的权威分数。 该专利讨论了一个类似的本地实体子系统,用于处理本地结果:

在处理本地结果时,在确定引用本地实体的文档的搜索分数时,可以使用本地实体与其他本地实体的相似性。 同样,如果搜索系统用于搜索独立于文档的本地实体(例如,搜索餐馆),则本地实体与其他本地实体的相似性也可用于确定要列出哪些本地实体以响应本地实体查询。 因此,搜索系统可以包括本地实体相似性子系统或与本地实体相似性子系统进行数据通信。 本地实体相似度子系统为每个本地实体确定对应的相似本地实体列表,该列表包括根据本地实体与列表对应的本地实体的相似度排名的本地实体列表。
本地实体之间的相似性可以部分通过查看查询日志外观来确定,该查询日志出现在某些可能相似的术语的查询日志结果中的频率:
该过程访问数据,为本地实体集合中的每个本地实体指定术语值和查询术语的选择值(202)。 术语值与包括查询日志中出现的查询术语的多个查询实例成比例。 例如,假设查询“Restaurant NYC Italian”和“Italian Restaurants Manhattan”在查询日志中分别出现了 N 次。 基于这两个查询及其各自的实例,“Restaurants”的术语值与 2N 成正比,而“NYC”、“Italian”和“Manhattan”的术语值与 N 成正比。
在响应类似查询时选择提及实体的某些页面是否有助于确定哪些企业在本地搜索中可能相似? 这可能取决于该实体对该页面的重要性。 该专利似乎描述了这种情况:
选择值与搜索结果的许多选择成比例,每个搜索结果响应于包括查询词并归属于该查询词的查询分别指定本地实体。 例如,假设响应于搜索查询而提供每个引用文档的搜索结果。 对于引用文档的搜索结果的每次选择,该文档又引用本地实体,对于该本地实体,查询的查询词的选择值增加。 在一些实现中,选择值增加多少可以取决于描述实体对文档主题的重要性的分数。 例如,对于上面描述的列出数百家餐馆并且对于每个餐馆实体具有相对较低分数的第一个文档,特定查询词和本地实体的查询词选择值将响应于选择而增加非常少引用文档的搜索结果。 相反,对于本地实体得分较高的第二个文档,特定查询词和本地实体的查询词选择值将比第一本地文档的选择增加得更多。
根据业务类型,相似本地实体的距离可能因重要性而异
可能会根据所涉及的企业类型显示类似的本地实体。 你会开车到比萨店多远? 对于加油站?
该专利也提出了这些问题:
例如,从本地实体的集合中选择第二本地实体的适当子集可以涉及选择地理位置在第一本地实体的地理位置的阈值距离内的本地实体。 阈值距离可以是固定距离,也可以根据本地实体类型而变化。 例如,对于餐厅类型的第一个实体,距离可能是 10 英里; 对于加油站类型的第一个实体,距离可能是三英里; 等等。
它还提供了有关这些距离的一些答案:
距离也可以基于估计的旅行时间。 For example, when a first local entity is selected, all other local entities within an estimated 20-minute drive may be selected. 因此,根据地理边界(例如,桥梁、河流等),从中选择其他本地实体的区域可能是不对称的,而不仅仅是圆形或矩形。 例如,可以根据从子集选择阶段和寻路算法之外的系统获得的交通模式来确定基于时间的距离。
用于确定相似性的查询词可能是高质量和低质量的,并查看点击选择数
在比较可能找到不同地方的查询词时,其中一些词被认为是高质量词,例如指示类别的词,例如“食物”。 一些查询词可能被认为质量较低,例如位置词或导航词。
查询中使用的位置术语(例如“NYC”)可能会出现在“pizza NYC”或“Chinese Food NYC”等查询中,但这并不表示与“pizza”等术语表示餐厅的方式相似专门供应比萨饼。 可能用作导航术语的查询术语,例如街区名称或购物中心的名称,例如“Lombardi's”。 同一购物中心或社区中的本地实体可能不太相似。 查询日志中用于比较的那些查询词的存在对于较高质量的词可能比较低质量的词更有帮助。 被确定为“海鲜”的两个地方可能比为“纽约市”找到的两个地方更相似。
该专利更深入地探讨了查询术语的质量,以及类别术语与指示位置或导航偏差的术语。 他们似乎更喜欢将类别作为指示本地实体相似性的查询词类型。
但是他们可能会同时关注高质量和低质量的查询词,尤其是当这些词的选择相似时:
相对选择值的“相似性”意味着查询词的选择分布相似。 例如,假设第一个实体是餐厅,第二个实体是赌场。 两个实体都可能有 5,000 次来自带有“餐厅”一词的查询的点击,但餐厅实体的所有查询有 7,000 次总点击归因于它,而赌场则有 1,000,000 次来自所有归因于它的查询的总点击。 由于相对分布非常不同,因此这两个实体的“餐厅”术语几乎没有相似之处。 相反,另一个实体从“餐厅”一词的查询中获得了 4,000 次点击,总点击次数为 6,000 次将被视为与“餐厅”一词的餐厅实体相似。 同样,另一个实体从“餐厅”一词的查询中获得 6,000 次点击,总点击次数为 975,000 次,将被视为与“餐厅”一词的赌场实体相似。
使用所有查询类型的选择可以指出两个不同的地方是否彼此相似或非常不同。 这不是使用点击信息来确定如何对实体进行排名,而是决定是否显示两个本地实体是否相似。